©PaperWeekly 原创 · 作者|邓云天
学校|哈佛大学计算机系博士生
研究方向|自然语言处理
论文标题: Cascaded Decoding with Markov Transformers
论文链接: https://arxiv.org/abs/2006.01112
论文代码: https://github.com/harvardnlp/cascaded-generation
引言
目前文本生成最常用的算法基于 fully autoregressive 模型,比如 RNN 和 transformer。在 fully autoregressive 模型中,生成下一个词的概率取决于之前所有的词。
给定一个 fully autoregressive 模型,文本生成通常使用 beam search 从左到右搜索概率最大的句子。但由于 beam search 是一个顺序的过程,我们无法在 GPU 上进行并行加速。
近年来,为了加速文本生成,Gu et al 2017 提出了 non-autoregerssive 模型。在 non-autoregressive 模型中,不同位置的词的生成是相互独立的,因此可以使用 GPU 同时生成所有词。但是这个独立假设太强,经常导致一些明显的问题,比如重复生成相同的词。
我们指出 non-autoregressive 模型是并行生成的充分但不必要条件。如果我们考虑 m 阶 Markov 模型的概率分布(每个词的概率取决于过去 m 个词称为 m 阶 Markov 模型),那么从这个分布中采样也是可以并行计算的(Rush et al 2020),而 non-autoregressive 模型只是 0 阶 Markov 模型的特殊情况。
在这个工作中,我们利用这个有限阶数 Markov 模型的性质提出 cascaded decoding(Weiss et al 2010)。Cascaded decoding 的核心是从 0 阶 Markov 模型开始,逐渐引入高阶 Markov 模型,从而逐步缩小搜索空间。
为了支持这个搜索算法,我们需要一组不同阶数的 Markov 模型。为此我们提出 transformer 的一个变种 Markov transformer,由此通过一个 Markov transformer 实现一组不同阶数的 Markov 模型。
值得一提的是,我们方法的速度与 non-autorgressive 方法相当,并且能够同时考虑到不同位置的词之间的关联从而达到很好的生成质量。
搜索算法:Cascaded Decoding
我们用 Conditional Random Field (CRF)来描述文本生成模型
,其中
是第
个单词,
是句子的长度。一个 m 阶 CRF 模型为:
上式中的
是带有参数的 log potential,它可以建模相邻
个单词之间的关系。当
,得到了一个 non-autoregressive 模型,而当
,得到 fully autoregressive 模型。
生成文本时,我们需要找到概率最高的句子
。我们可以使用动态算法计算,但时间复杂度是
,即使
都很不现实,因为
一般是几万量级的。
常用的做法是用 beam search 去找到近似的最优解,但 beam search 无法并行,而人们还很少考虑能替代 beam search 的算法。
我们提出的 cascaded decoding 的思路与 beam search 的从左到右不同,是基于对整个解空间
的不断过滤。我们考虑每个位置的可能的 n-gram,把不太可能的 n-gram 过滤掉,从而保留
个最可能的 n-gram。
首先,我们用一个 0 阶模型去过滤掉每个位置不太可能的 unigram,然后用一个 1 阶模型过滤掉每个位置不太可能的 bigram,再用一个 2 阶模型过滤掉每个位置不太可能的 trigram,直到最后得到一个高阶模型,并使用动态算法去找出过滤后的空间里的最优解。
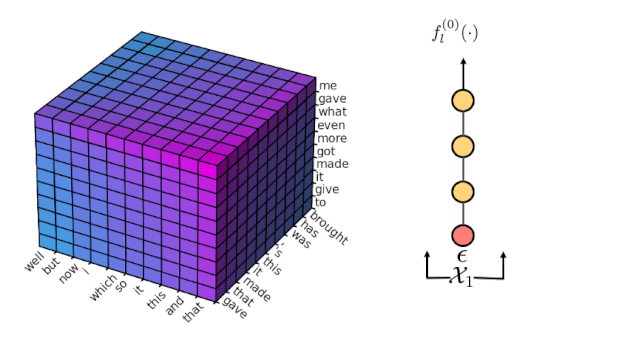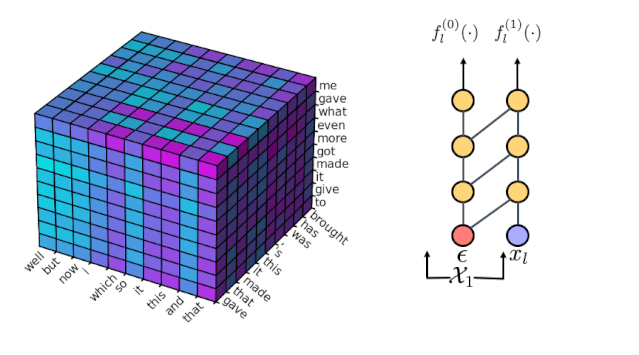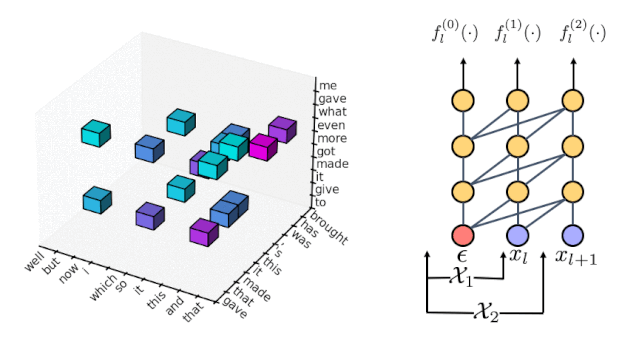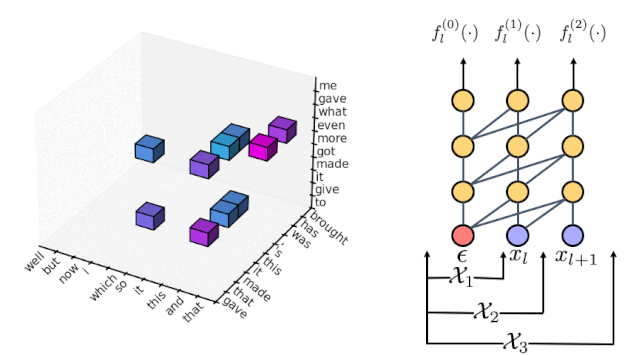
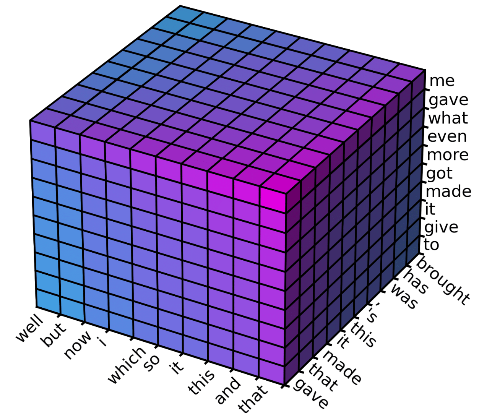
为了便于理解,下图中展示了一个序列长度
并且过滤 3 次的例子,这里我们使用
,也就是每次保留前 10 个 n-gram。
首先,我们使用一个 0 阶的 Markov 模型
(non-autoregressive 模型)去过滤掉每个位置不太可能的 unigram,每个位置只保留最可能的 10 个 unigram,所以过滤后的解空间如下图所示是一个 10
10
10 的立方体(过滤前的解空间大小为 V
V
V)。这里的坐标轴分别代表
,
和
。
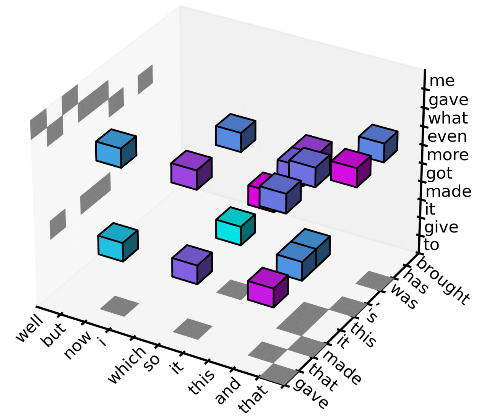
在此基础上,我们使用一个 1 阶的 Markov 模型
去过滤掉每个位置不太可能的 bigram,所以解空间进一步缩小为每个位置只考虑 10 个最可能的 bigram,可以从下图中的水平平面投影和左面垂直平面的投影中看出:每个平面上恰好有 10 个阴影小方块,代表 10 个被保留的 bigram(10 个可能的
和 10 个可能的
)。
最后,我们使用一个 2 阶的 Markov 模型
去过滤掉每个位置不太可能的 trigram,使得解空间缩小为每个位置只考虑 10 个最可能的 trigram,可以从下图中的 10 个小立方看出。
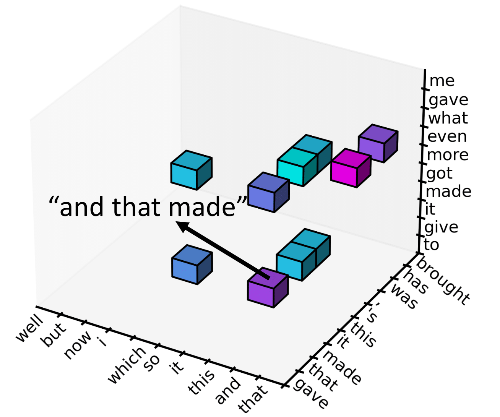
我们重复上述过程的次数越多,就能使用越高阶的模型从而更接近 fully autoregressive 模型。在最后的缩小的解空间里,我们可以使用动态算法去找出最可能的一句话。
在上面的过程中,我们用到了每个位置“最可能”的 n-gram,这个“最可能”的评判方式有很多,比如每个 n-gram 的 marginal probability,但我们实际使用的是 max-marginal(Weiss et al 2020),具体细节参见我们的论文。
变长生成
目前为止我们假定已知生成序列的长度,但实际应用中我们很难准确预测生成序列的长度,因此我们提出一个可以同时考虑不同可能长度的算法。我们先估计一个最大长度,然后在搜索中考虑所有比这个最大长度短的序列。
这种变长搜索在 CRF 中的实现非常简单:我们只需要在词表中引入一个占位字符 pad ,同时改写 log potential 使得句尾 eos 和 pad 的下一个词必须为 pad ,那么我们在生成时只需要使用一个最大长度,就可以同时考虑不同长度的句子:不同长度的句子只是句尾 pad 的个数不同而已,但 pad 的存在不会影响分数。
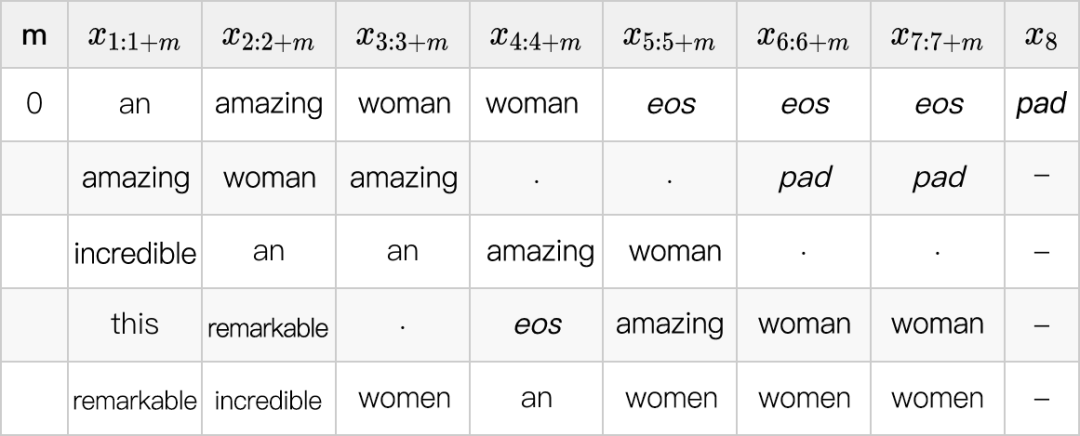
下表中我们展示一个 cascaded decoding 和变长生成的例子,这里我们考虑最大长度 8,并使用
,也就是只保留最可能的 5 个 unigram,birgram,trigram,在每个 table 的 5 行中按分数由大到小排序。
首先,我们使用一个 0 阶模型,并在下表中展示出每个位置最可能的 unigram。如果我们只使用一个 0 阶模型(non-autoregressive),那么得到的解将会是“an amzing woman woman eos ”(第一行),重复了单词“woman”,这也是 non-autoregressive 模型的常见问题。
在我们的算法中,之后引入的高阶模型可以修正这个问题。这里一个小细节是我们限制最后一个单词为占位字符 pad ,以确保每句话都有结束符 eos (end-of-sentence)。
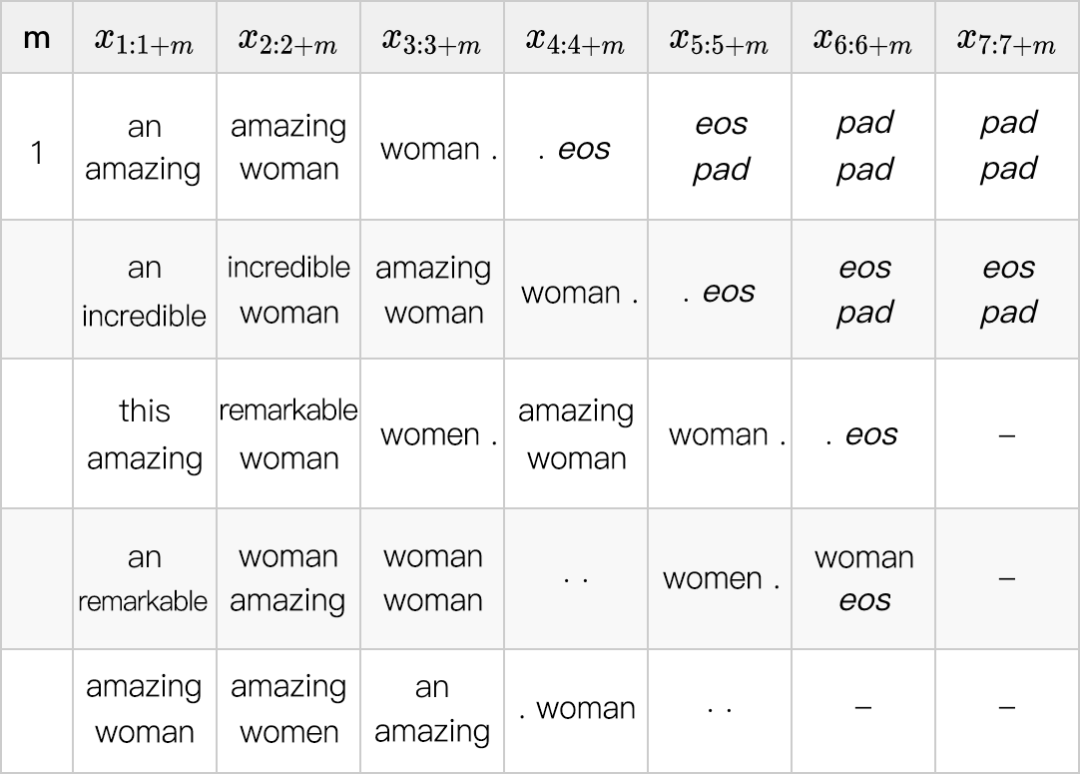
下一步,我们使用一个 1 阶模型,并在下表中展示出每个位置最可能的 bigram。现在已经修正了之前的重复问题:按照第一行的最可能 bigram,最可能的解已经是“an amazing women . eos pad pad pad ”。
同时注意到由于占位字符 pad 的存在,我们可以考虑长度小于最大长度 8 的句子,这在很多其他的 non-autoregressive 工作中是很难做到的。
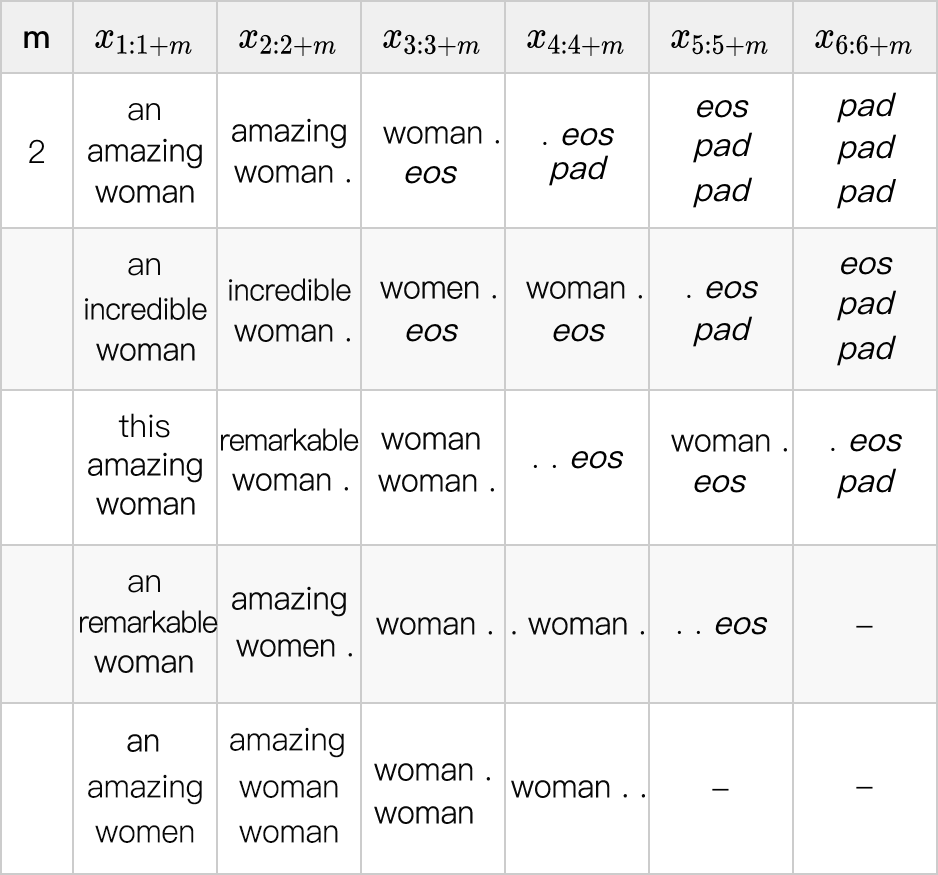
然后,我们使用一个 2 阶模型,并在下表中展示出每个位置最可能的 trigram。
我们可以重复上述过程来引入越来越高阶的模型,最后使用动态算法得到最可能的解。
并行化
计算不同位置 log potential 的过程是互相独立的,因此我们可以使用 GPU 并行计算所有位置的 log potential。除了 log potential 外,另一个问题是如何并行计算我们使用的过滤 n-gram 的指标 max-marginal。
实际上,Rush et al 2020 中已经指出 CRF 中的 max-marginal 和 marginal 都可以使用并行的动态算法计算,核心思路是建一个以句子的每个位置为叶子节点的二叉树并从下向上再从上到下计算,而不像传统的动态算法那样从句子的最左到最右再从右至左。这个算法已经在 torch-struct
[6]
包里实现。
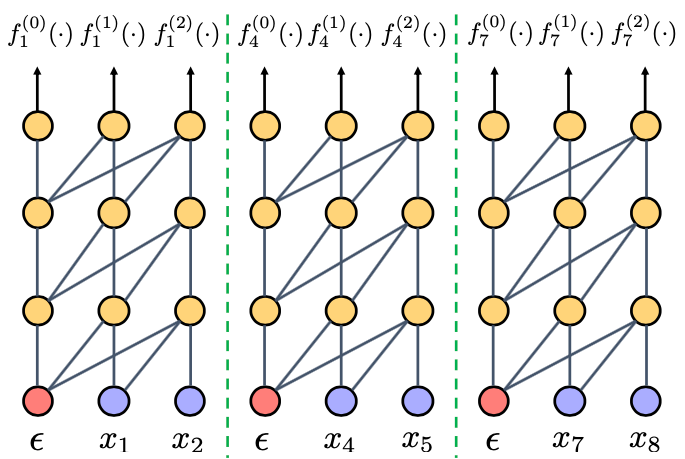
我们前面使用了很多不同阶的 Markov 模型,然而实际上我们可以修改 transformer 的训练过程,使一个 transformer 可以被当做不同阶的 Markov 模型使用,即 Markov transformer。
这里的核心思路是:如果在训练时每 M 个单词就重置 transformer 的 hidden state,并随机选择第一个重置位置,那么 transformer 就可以在测试中被当做任何小于
阶的模型,如下图所示(
)。
在上图中,绿色分割线代表重置 hidden state(在 transformer 中我们只需要要求灰色线条表示的 self attention 不穿过分割线即可,同时我们使用空白字符
去重置分割线后一个位置的 state)。
第 1、4、7 个位置的输出没有使用任何其他单词的信息,因此相当于使用了 0 阶模型;第 2、5、8 个位置的输出使用了前一个单词,因此相当于使用了 1 阶模型;第 3、6、9 个位置的输出使用了前两个单词,因此相当于使用了 2 阶模型。
综上,这个模型在测试时可以在任何位置被当做 0 阶、1 阶或者 2 阶模型使用。(我们需要随机选择第一个重置位置,否则比如上图中第 3 个位置无法被用作 0 阶或者 1 阶模型)。
实验结果与分析
使用 knowledge distillation,我们在 WMT14 En-De 上可以达到常规的 fully autoregressive transformer 速度的 2.4 倍,BLEU 只低 0.5。在 IWSLT14 De-En 上,我们的速度是 transformer 的 5.88 倍速度,BLEU 只损失 0.54。这个 BLEU 分数比去年的 FlowSeq(Ma et al 2019)高 6 分。
与 beam search 相比,cascaded decoding的另一个优势是在搜索过程中考虑了非常多的序列。虽然每个位置只考虑了
个 n-gram,但考虑的序列个数最多是以序列长度的指数增长的:比如如果每个位置只考虑
个 unigram,那么对于长度为
的序列就考虑了
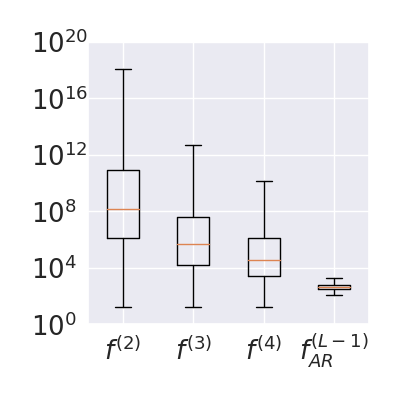
个可能的序列。下图中我们用一个 box plot 展示实际能够考虑的序列个数。
上图中的
,
,
是指 cascaded decoding 最终使用 2 阶、3 阶、4 阶 CRF 的结果, 而
展示的是 beam search 的结果。由此可见,即使我们使用 4 阶 CRF,依然可以比 beam search 考虑多一个量级的序列个数。
Beam search 在文本生成中的地位几十年来未被撼动。我们提出一种新的文本生成搜索算法 cascaded decoding,不仅形式简洁优美,而且性能优异。Cascaded decoding 可以衍生出很多新的研究方向,比如我们可以进行长文本生成,或者引入 latent variable 去考虑全局信息以弥补目前算法只能考虑局部关联的不足。
此外,我们提出的 Markov transformer 的思路可以被用来学习任何结构的概率图模型。最后,我们这里使用了一个 locally normalized 的语言模型作为 log potentials,实际上我们可以用更强大的 globally normalized 模型(Deng et al 2019)。
[1] Gu et al 2017:https://arxiv.org/pdf/1711.02281.pdf
[2] Rush et al 2020:https://arxiv.org/pdf/2002.00876.pdf
[3] Weiss et al 2010:http://proceedings.mlr.press/v9/weiss10a/weiss10a.pdf
[4] Ma et al 2019:https://arxiv.org/pdf/1909.02480.pdf)
[5] Deng et al 2019:https://openreview.net/pdf?id=B1l4SgHKDH
[6] https://github.com/harvardnlp/pytorch-struct
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读 ,也可以是学习心得 或技术干货 。我们的目的只有一个,让知识真正流动起来。
📝 来稿标准:
• 稿件确系个人原创作品 ,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
📬 投稿邮箱:
• 投稿邮箱: hr@paperweekly.site
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
🔍
现在,在「知乎」 也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」 订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」 ,小助手将把你带入 PaperWeekly 的交流群里。