近日,微软提出了一种基于 NeRF 的新系统 FastNeRF,用它来渲染逼真图像,速度能有多快呢?在高端消费级 GPU 上达到了惊人的 200FPS!
神经辐射场(Neural Radiance Fields, NeRF)领域的最新研究展示了神经网络编码复杂 3D 环境的方式,这类方法能以新的视角真实地渲染环境。渲染这些图像需要非常大的计算量,即使在高端硬件上,这些新进展与实现交互式速率仍然相去甚远。
在本文中,来自微软的研究者提出了一种名为 FastNeRF 的新系统,它以每秒数百帧的速度渲染对象的高分辨率真实性新视图。相比之下,NeRF 等现有方法在速度上要慢几个数量级,并且只能以交互速率渲染分辨率很低的图像。
![]()
FastNeRF 的提出受到了移动和混合现实设备上场景的启发,并且是
第一个基于 NeRF、能够在高端消费级 GPU 上以 200Hz 渲染高真实感图像的系统
(如上图右)。该方法的核心思想是图启发的分解,它允许:在空间中的每个位置紧凑地缓存一个深度辐射图;使用光线方向有效地查询该图以估计渲染图像中的像素值。
大量的实验表明,在运行速度上,FastNeRF 是原始 NeRF 算法的 3000 倍,比加速版 NeRF 至少快一个数量级,同时又保持了视觉质量和可扩展性。
![]()
在 Realistic 360 Synthetic 数据集中 Lego 场景图上,新方法与其他方法的速度评估对比结果。
论文地址:https://arxiv.org/abs/2103.10380
FastNeRF 在速度上取得了巨大的突破。这让在高端消费级硬件上以 200Hz 以上渲染高分辨率逼真图像。
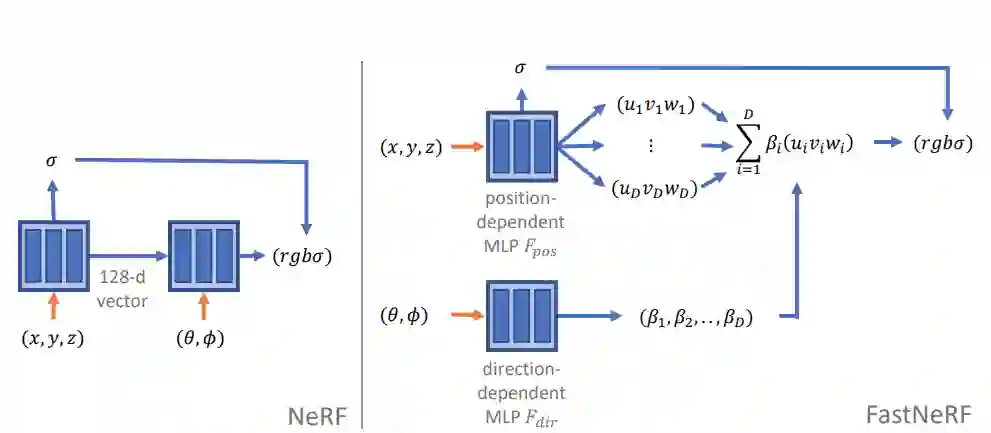
该方法的核心包括将 NeRF 分解为两个神经网络:一个是生成深度辐射图的位置依赖网络;另一个是生成权重的方向依赖网络。权重的内积和深度辐射图用于预估场景中特定位置从特定方向观察所呈现的颜色。FastNeRF 架构可以被高效缓存,在保持 NeRF 的视觉质量的同时,显著提升了测试时间效率。
下图 2 展示了 NeRF 和 FastNeRF 网络架构的比较:
![]()
图 2:左:NeRF 神经网络架构。(x, y, z)代表输入样例位置,(θ, φ)代表光线方向,(r, g, b, σ)是输出颜色和透明度值。右:FastNeRF 架构将同一任务分为两个适合缓存的神经网络。位置依赖网络 F_pos 输出一张深度辐射图(u, v, w),其中包含 D 个分量。而 F_dir 在输入光线方向时,输出分量的权重(β_1, . . . , β_D)。
训练 FastNeRF 和训练 NeRF 一样。研究者分别使用 8 层和 4 层的 MLP 建模 FastNeRF 的 F_pos 和 F_view,并将位置编码用于输入。
在测试阶段,FastNeRF 和 NeRF 都将一组相机参数作为输入。这些参数用于为输出中的每个像素生成光线,然后沿着每条光线生成大量样本并进行集成。FastNeRF 能够使用其神经网络表征来执行,当进行缓存时,性能会大幅度提升。
该研究在 NeRF 论文中使用的 Realistic 360 Synthetic 和 Local Light Field Fusion(LLFF)数据集上进行了定量和定性评估。NeRF 合成数据集由复杂对象的 360 度视图组成,而 LLFF 数据集由前向场景组成,图像较少。在所有与 NeRF 的比较中,该研究均使用与 NeRF 论文中相同的训练参数。
下面来看一下实验结果。如下图 4 所示,FastNeRF 与 NeRF 在使用 8 个分量的 800^2 像素的 [25] 数据集上的定性比较。小型缓存是指我们的方法缓存在 2563,而大型缓存是在 7683。更改缓存大小可实现计算和内存 trading,以达到类似于传统计算机图形中的细节级别(LOD)的图像质量。
![]()
如下图 5 所示,在使用 6 种因子、504 × 378 像素的数据集上,新方法与 NeRF 的定量对比结果:
![]()
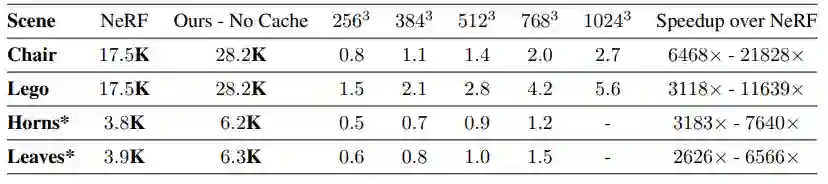
下表 1 中,研究者提供了不缓存网格和以高分辨率缓存时,FastNeRF 与 NeRF 在三种度量(PSNR、SSIM、LPIPS)上的对比,并给出了存在缓存时新方法的平均速度。
![]()
下表 2 为该方法与 NeRF 的速度比较。椅子(Chair)和乐高(Lego)的场景是以 800^2 的分辨率渲染的。犀牛角(Horns)和叶子(Leaves)场景图则是以 504 × 378 分辨率渲染的。该方法在存在缓存时速度没有低于 100FPS,并且经常会更快。
![]()
下表 3 为分量数量和网格分辨率对缓存轮船(ship)场景所需 PSNR 和内存的影响。注意到有多种因素都能够增加网格稀疏性。该研究发现 8 或 6 个分量是一种合理的折衷方案。
![]()
下图 6 为使用结合变形场网络的 FastNeRF 渲染的人脸图像。使用 FastNeRF 可以让人脸表情图像的渲染速度达到 30FPS。
![]()
亚马逊云科技线上黑客松2021
这是一场志同道合的磨练,这是一场高手云集的组团竞技。秀脑洞、玩创意,3月26日至5月31日,实战的舞台为你开启,「亚马逊云科技线上黑客松2021」等你来战!
为了鼓励开发者的参与和创新,本次大赛为参赛者准备了丰厚的奖品,在一、二、三等奖之外,还特设prActIcal奖、creAtIve奖、锦鲤极客奖、阳光普照奖,成功提交作品的团队均可获赠奖品。
识别二维码,立即报名参赛。
![]()
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com