最新《可解释机器学习:原理与实践》综述论文,33页pdf

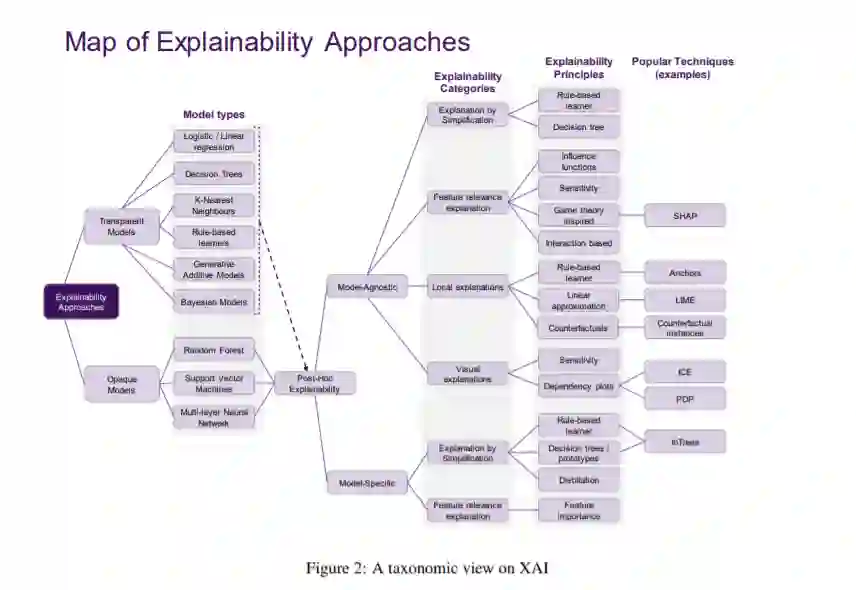
人工智能(AI)为改善私人和公共生活提供了很多机会,以自动化的方式在大型数据中发现模式和结构是数据科学的核心组件,目前驱动着计算生物学、法律和金融等不同领域的应用发展。然而,这种高度积极的影响也伴随着重大的挑战:我们如何理解这些系统所建议的决策,以便我们能够信任它们?在这个报告中,我们特别关注数据驱动的方法——特别是机器学习(ML)和模式识别模型——以便调查和提取结果和文献观察。通过注意到ML模型越来越多地部署在广泛的业务中,可以特别理解本报告的目的。然而,随着方法的日益普及和复杂性,业务涉众对模型的缺陷、特定数据的偏差等越来越关注。类似地,数据科学从业者通常不知道来自学术文献的方法,或者可能很难理解不同方法之间的差异,所以最终使用行业标准,比如SHAP。在这里,我们进行了一项调查,以帮助行业从业者(以及更广泛的数据科学家)更好地理解可解释机器学习领域,并应用正确的工具。我们后面的章节将围绕一位公认的数据科学家展开叙述,并讨论她如何通过提出正确的问题来解释模型。
https://arxiv.org/abs/2009.11698
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“EML33” 可以获取《最新《可解释机器学习:原理与实践》综述论文,33页pdfg》专知下载链接索引



登录查看更多
相关内容




相关VIP内容
相关资讯
相关论文