教你在Python中用Scikit生成测试数据集(附代码、学习资料)

原文标题:How to Generate Test Datasets in Python with Scikit-learn
作者:Jason Brownlee
翻译:笪洁琼
校对:顾佳妮
本文共1754字,建议阅读3分钟。
本文教大家在测试数据集中发现问题以及在Python中使用scikit学习的方法。
测试数据集是一个小型的人工数据集,它可以让你测试机器学习算法或其它测试工具。
测试数据集的数据具有定义明确的性质,如线性或非线性,这允许您探索特定的算法行为。
scikit-learn Python库提供了一组函数,用于从结构化的测试问题中生成样本,用于进行回归和分类。
在本教程中,您将发现测试问题以及如何在Python中使用scikit学习。
完成本教程后,您将知道:
如何生成多分类预测问题
如何生成二分类预测问题
如何生成线性回归预测测试问题
让我们开始吧
教程概述
本教程分为三个部分,分别是:
测试数据集
分类测试问题
回归测试的问题
测试数据集
开发和实现机器学习算法遇到的问题是,您如何知道是否正确地实现了机器学习算法。
即使存在bug有些算法还是能执行。
测试数据集是一个较小的人为设计问题,它允许您测试和调试算法和测试工具。
它们还能帮助更好地理解算法的行为,以及超参数是如何在相应算法的执行过程进行改变的。
下面是测试数据集的一些理想属性:
它们可以快速且容易地生成。
它们包含“已知”或“理解”的结果与预测相比较。
它们是随机的,每次生成时都允许对同一个问题进行随机变量的变化。
它们很小,可以很容易在两个维度中进行可视化。
它们也可以被简单地放大。
我建议在开始使用新的机器学习算法或开发新的测试工具时使用测试数据集。
scikit-learn是一个用于机器学习的Python库,它提供了生成一系列测试问题的功能。
在本教程中,我们将介绍一些为分类和回归算法生成测试问题的例子。
分类测试问题
分类是把标签分配给观测样本的问题。
在这一节中,我们将讨论三种分类问题:斑点、月亮和圆圈。
斑点分类问题
make_blob()函数可用于生成高斯分布的点。
您可以控制生成多少个斑点,以及生成的样本数量,以及其他一些属性。
如果这些斑点有线性可分的性质,那么这个问题适用于线性分类问题。
下面的例子生成一个带有三类斑点的二维数据集,作为一个多类分类预测问题。
每个观察都有两个输入和0、1或2个类值。

完整代码如下
运行这个示例会生成问题的输入和输出,然后创建一个方便的2D绘图,用不同的颜色显示不同的类。
注意,由于问题生成器的随机特性,您的特定数据集和结果图将会有所不同。
这是一个特性,而不是一个bug。
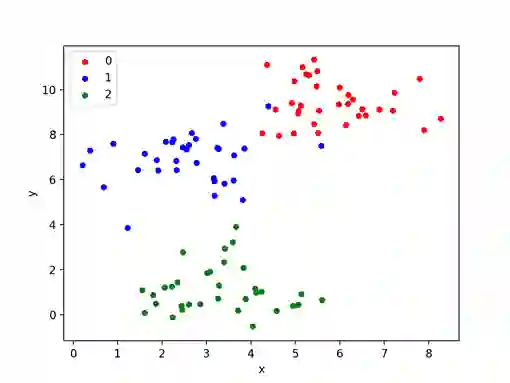
测试分类问题的散点图
我们将在下面的示例中使用这个相同的示例结构。
卫星分类问题
make_moons()函数是用于二分类问题的的,它将生成像漩涡一样,或者像月亮形状一样的数据集。
你可以控制月亮的形状和产生的样本数量。
这个测试问题适用于能够学习非线性类边界的算法。
下面的例子产生了一个带有中等噪声的月球数据集。

完整的代码如下
运行该示例将生成并绘制用于检查的数据集,再次为其指定的类着色。
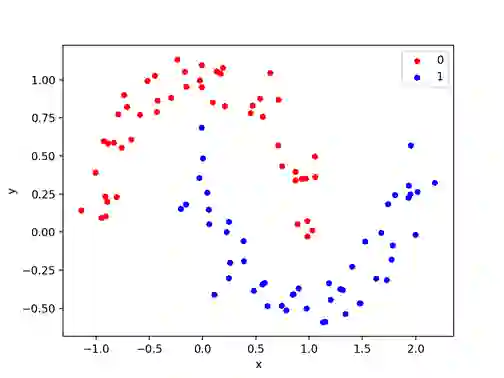
卫星测试分类问题散的点图
圈分类问题
make_circles()函数会产生一个二分类问题,这个问题会出现在一个同心圆中。
再一次,就像卫星测试的问题一样,你可以控制形状中噪音的大小。
该测试问题适用于能够学习复杂非线性曲线的算法。
下面的示例生成一个带有一些噪声的圆形数据集。

完整的代码如下
运行该示例将生成并绘制用于检查的数据集。
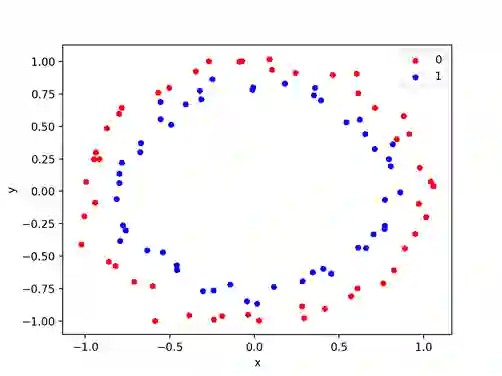
圆试验分类问题的散点问题
回归测试的问题
回归是预测某个观测量的问题。
make_regression()函数将创建一个带有输入和输出之间线性关系的数据集。
您可以配置示例的数量、输入特性的数量、噪声级别,等等。
这个数据集适用于能够学习线性回归函数的算法。
下面的示例将生成100个示例,其中包含一个输入特性和一个输出特性,它的噪声很低。

完整的代码如下。
运行该示例将生成数据,并绘制X和y关系图,由于该关系是线性的,因此非常无趣。
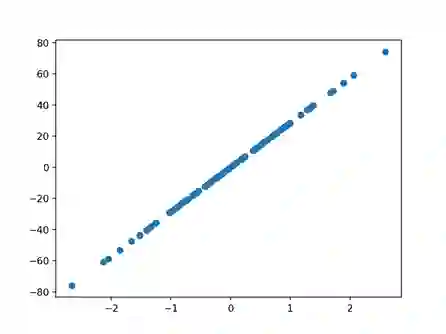
回归测试问题的散点图
延伸
本节列出了一些扩展您可能希望探索的教程的想法。
比较算法
选择一个测试问题,并对问题的算法进行比较,并报告性能。
扩大的问题
选择一个测试问题,并探索扩大它的规模,使用改进的方法来可视化结果,或者探索给定的算法的模型技巧和问题深度。
额外的问题
这个库提供了一系列额外的测试问题;
为每个人编写一个代码示例来演示它们是如何工作的。
如果您探究这些扩展的任何一个,我很想知道。
进一步的阅读
如果您希望深入研究,本节将提供更多关于主题的参考资料。
学习用户指南:数据集加载实用程序(http://scikit-learn.org/stable/datasets/index.html)
scikit-learn API:sklearn - 数据集(http://scikit-learn.org/stable/modules/classes.html#module-sklearn.datasets)
总结
在本教程中,您发现了测试问题,以及如何在Python中使用scikit库。
具体来说,你学会了:
如何生成多分类预测问题
如何生成二分类预测问题
如何生成线性回归预测测试问题
原文链接:https://machinelearningmastery.com/generate-test-datasets-python-scikit-learn/

笪洁琼,中南财大MBA在读,目前研究方向:金融大数据。目前正在学习如何将py等其他软件广泛应用于金融实际操作中,例如抓包预测走势(不会预测股票/虚拟币价格)。可能是金融财务中最懂建筑设计(风水方向)的长腿女生。花式调酒机车冲沙。上赛场里跑过步开过车,商院张掖丝路挑战赛3天徒步78公里。大美山水心欲往,凛冽风雨信步行。
翻译组招募信息
工作内容:需要一颗细致的心,将选取好的外文文章翻译成流畅的中文。如果你是数据科学/统计学/计算机类的留学生,或在海外从事相关工作,或对自己外语水平有信心的朋友欢迎加入翻译小组。
你能得到:定期的翻译培训提高志愿者的翻译水平,提高对于数据科学前沿的认知,海外的朋友可以和国内技术应用发展保持联系,THU数据派产学研的背景为志愿者带来好的发展机遇。
其他福利:来自于名企的数据科学工作者,北大清华以及海外等名校学生他们都将成为你在翻译小组的伙伴。
点击文末“阅读原文”加入数据派团队~
转载须知
如需转载,请在开篇显著位置注明作者和出处(转自:数据派ID:datapi),并在文章结尾放置数据派醒目二维码。有原创标识文章,请发送【文章名称-待授权公众号名称及ID】至联系邮箱,申请白名单授权并按要求编辑。
发布后请将链接反馈至联系邮箱(见下方)。未经许可的转载以及改编者,我们将依法追究其法律责任。

点击“阅读原文”报名




