预训练生成模型:结合VAE与BERT/GPT-2提高文本生成效果

论文标题:
Optimus: Organizing Sentences via Pre-trained Modeling of a Latent Space
论文作者:
Chunyuan Li, Xiang Gao, Yuan Li, Xiujun Li, Baolin Peng, Yizhe Zhang, Jianfeng Gao
论文链接:
https://arxiv.org/abs/2004.04092
代码链接:
https://github.com/ChunyuanLI/Optimus
本文提出首个大规模预训练生成模型OPTIMUS,在VAE之上进行预训练,既利用了预训练的优势,又利用了生成模型在文本生成上的优势,可以轻松扩展到各类文本生成任务上。
在语言模型、受控文本生成、语言理解等任务上,OPTIMUS都取得了显著的效果。
背景:生成式模型与隐变量模型
文本生成任务就是要求模型生成一段文本,这可以分为两类:给定了输入和没给定输入。这二者都可以形式化为

生成式模型在过去的几年里大都基于Transformer,比如GPT,BERT的变体等,这类模型直接去优化条件概率
但是,在诸多生成式模型中,有一种特殊的模型,它去建模一个隐式的语言空间,每次在语言空间中采样一个点,代表语法/语义等语言学信息,也就是说,它并不是直接建模

使用这种模型,我们可以在某种意义上“操纵”隐变量
过去的预训练大都是基于典型生成模型,这一方面是因为这类模型简单直观,调参、训练也比较简单;另一方面是因为隐变量模型通常难以优化,尤其是对离散型的文本。
但是,预训练隐变量生成模型就不能实现吗?本文给出了一个答案,通过仔细地设计模型结构、调整训练过程,我们依然能够在隐变量生成模型上进行大规模文本预训练,并且可以取得非常好的效果!
本文的贡献如下:
提出首个大规模预训练隐变量生成模型OPTIMUS;
高效地将隐变量和预训练的GPT-2相结合;
发现大规模预训练可以减缓KL Vanishing的问题;
在多个任务上取得显著的效果。
OPTIMUS:大规模预训练隐变量生成模型
和传统的预训练模型一样,OPTIMUS有预训练(Pretraining)和微调(Finetuning)两个阶段,下面分别进行介绍。
预训练
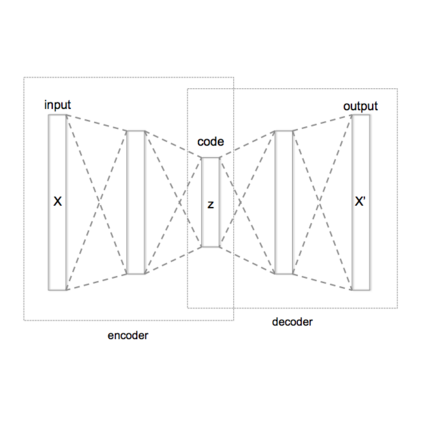
OPTIMUS采用VAE(变分自编码器)和预训练的BERT与GPT-2的结合作为整体模型。模型的生成基于隐变量

而隐变量是通过一个编码器

对于给定的输入文本
此外,还有一个KL散度损失,用于让得到的隐变量
所以,总的损失就是:

上述公式就表达了VAE的训练过程,其中加入
可以看到,模型的编码器是预训练的BERT,用来得到隐变量;模型的解码器是预训练的GPT-2,用于基于隐变量去生成文本。
注意到,这里的预训练和OPTIMUS的预训练不同,OPTIMUS的预训练是对整个模型而言,而BERT和GPT-2的预训练是对它们各自而言。
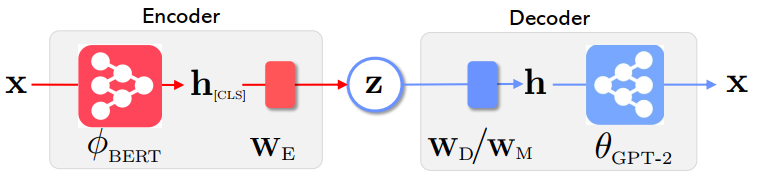
现在有一个问题(其实还有好几个问题,我们忽略其他更细节的问题,请读者参考原文):我们该如何把隐变量
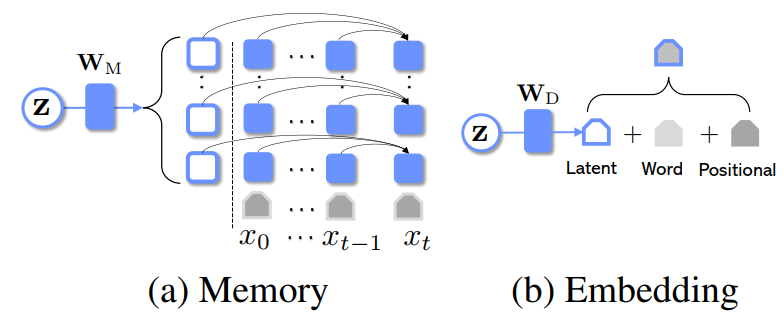
本文提供两种方法,分别为记忆(Memory)和嵌入(Embedding):
Memory: 在得到
之后,再通过一个变换把它转换为L个向量,每个向量服务解码器的一层,作为额外的记忆单元让解码器在生成的每一步去关注(相当于一个特殊的词);
Embedding: 在得到
之后,用一个线性变换先把它转换为一个向量,然后在生成的每一个,直接把它和解码器每一步的状态向量相加。
下图是这两种方法的图示。
实验表明,Memory比Embedding好,而二者合起来使用最好。因此,在后面的实验部分,我们默认二者一起使用。
最后就是详细的预训练细节了。预训练数据是1990K个Wikipedia的句子。在训练的过程中,由于熟知的KL Vanishing问题,我们还要对训练过程做一些优化。具体来说,本文采用如下优化:
对
使用循环调度(cyclical schedule);
在训练的前一半,设置
,对后一半的前一半,将其增长到1,对最后四分之一,固定为1;
当
不等于0的时候,加入hinge loss,保证KL项始终大于一个数
。

微调
在预训练OPTIMUS之后,剩下的就是对不同的任务进行微调了。本文在三类任务上实验:语言模型、受限文本生成和自然语言理解。每个任务和数据集在微调上都有一些细微的差别,笔者建议读者阅读原文进行了解。
实验
现在就到了见证OPTIMUS威力的时刻了。下面我们根据任务来看看OPTIMUS的效果。
语言模型
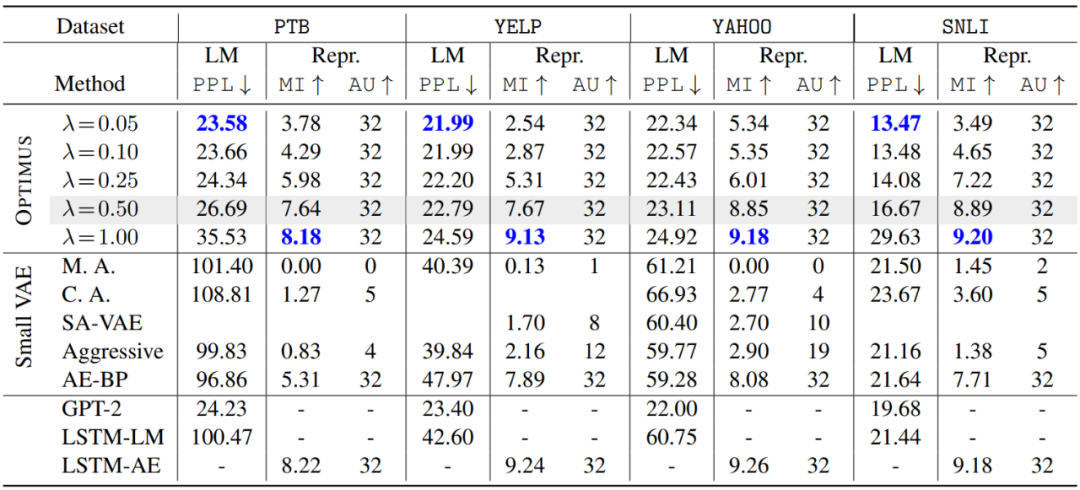
语言模型的数据集有PTB、SNLI和Yelp,度量方式有PPL、Active Units (AU)和Mutual Information (MI)。基线模型有GPT-2、Annealing-VAE、AggressiveTraining-VAE、AE-FB。
下表是实验结果。可以看到,单纯的VAE(第二组,Small VAE)在各个指标上都表现得很差,这归结于:(1)传统VAE的模型很小,表达力不够;(2)KL Vanishing严重,难以充分训练。
在PPL指标上,即使和典型生成模型GPT-2相比,依旧非常有优势。注意到不同的
受限文本生成:数学运算
我们在最开始提到,隐变量模型的一大优势是,我们可以“操纵”隐变量,从而得到不同的文本。
为了探究OPTIMUS所得到隐空间的表示能力,我们首先在“文本算术”任务上进行实验。
给定三个文本A,B,C,首先用编码器得到它们的隐变量

它的意思是,如果OPTIMUS能够得到足够光滑、分布良好的隐空间,那么将文本编码为隐变量之后,隐变量之间的线性运算就代表了文本语义之间的运算。
如下图所示,在给定了A,B之后,不断给定新的C,模型通过上式生成新的句子D。可以看到,句子A表达的是单数、日常生活,句子B表达了复数、运动。
因此,对所有给定的C,模型都能把其中的单数变成复数,把日常生活主题变为运动主题。这就可以从侧面表明,OPTIMUS得到的隐空间是比较好的。

另一个展示隐空间良好性的方法是插值。给定两个句子A,B,得到它们的隐变量


可以看到,系数越大,生成的文本约偏向句子A,反之偏向句子B。
受限文本生成
下面在具体的任务——普通对话生成、风格化对话生成和基于标签的文本生成上进行实验。数据集分别是Dailydialog和Yelp。下面三个表分别是这三个任务的实验结果。
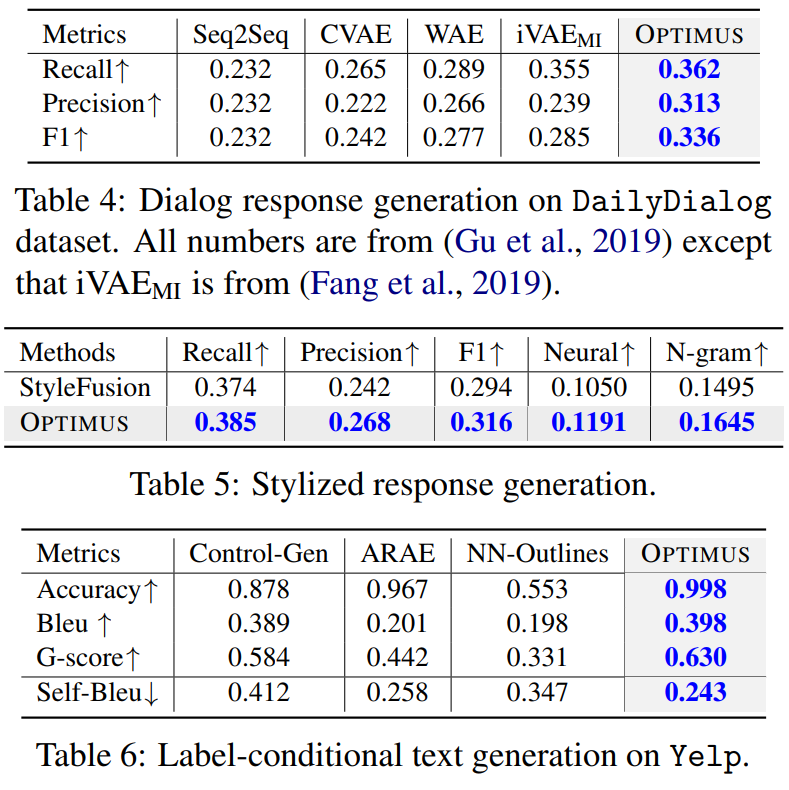
可以看到,在普通对话生成上,OPTIMUS优于基线模型,在风格化对话生成上,OPTIMUS优于StyleFusion,而尤其在基于标签的文本生成上,OPTIMUS效果显著。
自然语言理解
下面来看看OPTIMUS在NLU任务上的效果,这类任务旨在度量模型“理解”文本的能力。下表是在GLUE上的结果。注意到,比较的Feature-Based模型,也就是微调的时候只更新分类器,而不更新模型主体,这样就会大大减少训练开支。
可以看到,在Feature-Based上,OPTIMUS显著优于BERT,尤其是在比较大的数据集上。当更新整个模型的时候(Finetune-Based),OPTIMUS和BERT的效果相似。

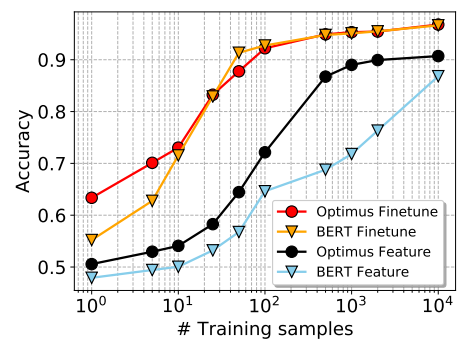
下面继续来探究在低资源条件下,OPTIMUS的效果。对Yelp数据集,随机对每一类采样若干样本,在Feature-Based和Finetune-Based两种设置下,看不同模型的效果,下图是结果。
在Feature-Based下,OPTIMUS显著优于BERT,这表明,在资源比较少的时候,OPTIMUS更能区分不同类别,这得益于它的隐变量性质;而在Fintune-Based下,二者结果差别不大,但在资源特别少的时候,OPTIMUS显著优于BERT,这说明OPTIMUS有更好的迁移能力。
小结
本文提出了一个大规模预训练隐变量生成模型OPTIMUS,它结合了VAE和预训练的典型生成式模型BERT/GPT-2,以VAE的方式在额外的数据上预训练之后,能够兼具VAE和BERT/GPT-2的优点,在多个任务上取得比较好的效果。
本文在自然语言处理上成功使用VAE迈出了成功的一步,这极有可能是NLP下一个时代产生突破的重点领域。
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。