PostgreSQL用户应掌握的高级SQL特性(有书送)

作者介绍
谭峰,网名francs,中国开源软件推进联盟PostgreSQL分会特聘专家,《PostgreSQL实战》作者之一,《PostgreSQL 9 Administration Cookbook》译者之一。现就职于浙江移动负责应用上云架构管控以及私有云建设工作。
张文升,中国开源软件推进联盟PostgreSQL分会核心成员之一,《PostgreSQL实战》作者之一,活跃于PostgreSQL、MySQL、Redis等开源技术社区,致力于推动PostgreSQL在互联网企业的应用及企业PostgreSQL培训与技术支持。
PostgreSQL数据库在SQL和NoSQL方面具有很多丰富的特性,本文将先从SQL高级特性入手来进行介绍。
一、PostgreSQL的SQL高级特性
这一部分主要介绍PostgreSQL在SQL方面的高级特性,例如WITH查询、批量插入、RETURNING返回修改的数据、UPSERT、数据抽样、聚合函数、窗口函数等。
WITH查询是PostgreSQL支持的高级SQL特性之一,这一特性常称为CTE(Common Table Expressions),WITH查询在复杂查询中定义一个辅助语句(可理解成在一个查询中定义的临时表),这一特性常用于复杂查询或递归查询应用场景。
先通过一个简单的CTE示例了解WITH查询,如下所示:
WITH t as (
SELECT generate_series(1,3)
)
SELECT * FROM t;
执行结果如下:
generate_series
-----------------
1
2
3
(3 rows)
这个简单的CTE示例中,一开始定义了一条辅助语句t取数,之后在主查询语句中查询t,定义的辅助语句就像是定义了一张临时表,对于复杂查询如果不使用CTE,可以通过创建视图方式简化SQL。
WITH查询的一个重要属性是RECURSIVE,使用RECURSIVE属性可以引用自己的输出,从而实现递归,一般用于层次结构或树状结构的应用场景。
例如,存在一张包含如下数据的表:
id name fatherid
1 中国 0
2 辽宁 1
3 山东 1
4 沈阳 2
5 大连 2
6 济南 3
7 和平区 4
8 沈河区 4
使用PostgreSQL的WITH查询检索ID为7以及以上的所有父节点,如下:
WITH RECURSIVE r AS (
SELECT * FROM test_area WHERE id = 7
UNION ALL
SELECT test_area.* FROM test_area, r WHERE test_area.id = r.fatherid
)
SELECT * FROM r ORDER BY id;
查询结果如下:
id | name | fatherid
----+--------+----------
1 | 中国 | 0
2 | 辽宁 | 1
4 | 沈阳 | 2
7 | 和平区 | 4
(4 rows)
批量插入是指一次性插入多条数据,主要用于提升数据插入效率,PostgreSQL有多种方法实现批量插入:
方式一:INSERT INTO..SELECT.
过表数据或函数批量插入,这种方式大部分关系数据库都支持,语法如下:
INSERT INTO table_name SELECT …FROM source_table
方式二:INSERT INTO VALUES (),(),…()
这种批量插入方式为一条INSERT语句中通过VALUES关键字插入多条记录,通过一个例子就很容易理解,如下所示:
mydb=> CREATE TABLE tbl_batch3(id int4,info text);
CREATE TABLE
mydb=> INSERT INTO tbl_batch3(id,info) VALUES (1,'a'),(2,'b'),(3,'c');
INSERT 0 3
数据如下:
mydb=> SELECT * FROM tbl_batch3;
id | info
----+------
1 | a
2 | b
3 | c
(3 rows)
这种批量插入方式非常独特,一条SQL插入多行数据,相比一条SQL插入一条数据的方式能减少和数据库的交互,减少数据库WAL(Write-Ahead Logging)日志的生成,提升插入效率,通常很少有开发人员了解PostgreSQL的这种批量插入方式。
方式三:COPY或\COPY元命令
COPY或\COPY元命令能够将一定格式的文件数据导入到数据库中,相比INSERT命令插入效率更高,通常大数据量的文件导入一般在数据库服务端主机通过PostgreSQL超级用户使用COPY命令导入。
将文件tbl_batch4.txt的一千万数据导入到表中,如下所示:
mydb=# TRUNCATE TABLE pguser.tbl_batch4;
TRUNCATE TABLE
mydb=# COPY pguser.tbl_batch4 FROM '/home/pg10/tbl_batch4.txt';
COPY 10000000
PostgreSQL的RETURNING特性可以返回DML修改的数据,具体为以下三个场景 ,INSERT语句后接RETURNING属性返回插入的数据,UPDATE语句后接RETURNING属性返回更新后的新值,DELETE语句后接RETURNING属性返回删除的数据,这个特性的优点在于不需要额外的SQL获取这些值,能够方便应用开发,接着通过示例演示。
RETURNING返回插入的数据
INSERT语句后接RETURNING属性返回插入的值,以下创建测试表,并返回已插入的整行数据。
mydb=> CREATE TABLE test_r1(id serial,flag char(1));
CREATE TABLE
mydb=> INSERT INTO test_r1(flag) VALUES ('a') RETURNING *;
id | flag
----+------
1 | a
(1 row)
INSERT 0 1
RETURNING返回更新后数据
UPDATE后接RETURNING属性返回UPDATE语句更新后的值,如下所示:
mydb=> SELECT * FROM test_r1 WHERE id=1;
id | flag
----+------
1 | a
(1 row)
mydb=> UPDATE test_r1 SET flag='p' WHERE id=1 RETURNING *;
id | flag
----+------
1 | p
(1 row)
UPDATE 1
RETURNING返回删除的数据
DELETE后接RETURNING属性返回删除的数据,如下所示:
mydb=> DELETE FROM test_r1 WHERE id=2 RETURNING *;
id | flag
----+------
2 | b
(1 row)
DELETE 1
PostgreSQL的UPSERT特性是指INSERT ... ON CONFLICT UPDATE,用来解决在数据插入过程中数据冲突的情况,比如违反用户自定义约束,日志数据应用场景通常在事务中批量插入日志数据,如果其中有一条数据违反表上的约束,则整个插入事务将会回滚,PostgreSQL的UPSERT特性可解决这一问题。
接下来通过例子来理解UPSERT的功能,定义一张用户登录日志表并插入一条数据,如下:
mydb=> CREATE TABLE user_logins(user_name text primary key,
login_cnt int4,
last_login_time timestamp(0) without time zone);
CREATE TABLE
mydb=> INSERT INTO user_logins(user_name,login_cnt) VALUES ('francs',1);
INSERT 0 1
在user_logins表user_name字段上定义主键,批量插入数据中如有重复会报错,如下所示:
mydb=> INSERT INTO user_logins(user_name,login_cnt)
VALUES ('matiler',1),('francs',1);
ERROR: duplicate key value violates unique constraint "user_logins_pkey"
DETAIL: Key (user_name)=(francs) already exists.
上述SQL试图插入两条数据,其中matiler这条数据不违反主键冲突,而francs这条数据违反主键冲突,结果两条数据都不能插入。PostgreSQL的UPSERT可以处理冲突的数据,比如当插入的数据冲突时不报错,同时更新冲突的数据,如下所示:
mydb=> INSERT INTO user_logins(user_name,login_cnt)
VALUES ('matiler',1),('francs',1)
ON CONFLICT(user_name)
DO UPDATE SET
login_cnt=user_logins.login_cnt+EXCLUDED.login_cnt,last_login_time=now();
INSERT 0 2
上述INSERT语句插入两条数据,并设置规则:
当数据冲突时更新登录次数字段login_cnt值加1,同时更新最近登录时间last_login_time,ON CONFLICT(user_name)定义冲突类型为user_name字段,DO UPDATE SET是指冲突动作,后面定义了一个UPDATE语句,注意上述SET命令中引用了user_loins表和内置表EXCLUDED,引用原表user_loins访问表中已存在的冲突记录,内置表EXCLUDED引用试图插入的值,再次查询表user_login,如下所示:
mydb=> SELECT * FROM user_logins ;
user_name | login_cnt | last_login_time
-----------+-----------+---------------------
matiler | 1 |
francs | 2 | 2017-08-08 15:23:13
(2 rows)
一方面冲突的francs这条数据被更新了login_cnt和last_login_time字段,另一方面新的数据matiler记录已正常插入。
数据抽样(TABLESAMPLE)在数据处理方面经常用到,特别是当表数据量比较大时,随机查询表一定数量记录很常见,PostgreSQL早在9.5版时就已经提供了TABLESAMPLE数据抽样功能,9.5版前通常通过ORDER BY random()方式实现数据抽样,这种方式虽然在功能上满足随机返回指定行数据,但性能很低,如下:

表user_ini数据量为100万,从100万随机取一条上述SQL执行时间为367ms,这种方法走了全表扫描和排序,效率非常低,当表数据量大时,性能几乎无法接受。
9.5版本以后PostgreSQL支持TABLESAMPLE数据抽样,语法如下:
SELECT …
FROM table_name
TABLESAMPLE sampling_method ( argument [, ...] ) [ REPEATABLE ( seed ) ]
sampling_method指抽样方法,主要有两种:SYSTEM和BERNOULLI。接下来详细介绍这两种抽样方式,argument指抽样百分比。
SYSTEM抽样方式
SYSTEM抽样方式为随机抽取表上数据块上的数据,理论上被抽样表的每个数据块被检索的概率是一样的,SYSTEM抽样方式基于数据块级别,后接抽样参数,被选中的块上的所有数据将被检索。
创建test_sample测试表,并插入150万数据,抽样因子设置成0.01,意味着返回1500000*0.01%=150条记录,执行如下SQL:

以上执行计划主要有两点:
一方面走了Sample Scan扫描(抽样方式为SYSTEM),执行时间为0.166毫秒,性能较好;
另一方面优化器预计访问150条记录,实际返回107条。
BERNOULLI抽样方式
BERNOULLI抽样方式随机抽取表的数据行,并返回指定百分比数据,BERNOULLI抽样方式基于数据行级别,理论上被抽样表的每行记录被检索的概率是一样的,因此BERNOULLI抽样方式抽取的数据相比SYSTEM抽样方式具有更好的随机性,但性能上相比SYSTEM抽样方式低很多,下面演示下BERNOULLI抽样方式,同样基于test_sample测试表。
设置抽样方式为BERNOULLI,抽样因子为0.01,如下所示:

从以上执行计划看出走了Sample Scan扫描(抽样方式为BERNOULLI),执行计划预计返回150条记录,实际返回152条,从返回的记录数来看,非常接近150条(1000000*0.01%),但执行时间却要22.569毫秒,性能相比SYSTEM抽样方式0.166毫秒差了136倍。
多次执行以下查询,查看返回记录数的变化,如下所示:
mydb=> SELECT count(*) FROM test_sample TABLESAMPLE BERNOULLI(0.01);
count
-------
151
(1 row)
mydb=> SELECT count(*) FROM test_sample TABLESAMPLE BERNOULLI(0.01);
count
-------
147
(1 row)
从以上看出,BERNOULLI抽样方式返回的数据量非常接近抽样数据的百分比,而SYSTEM抽样方式数据返回以数据块为单位,被抽样的块上的所有数据都被返回,因此SYSTEM抽样方式的数据量返回的偏差较大。
这里演示了SYSTEM和BERNOULLI抽样方式,SYSTEM抽样方式基于数据块级别,随机抽取表数据块上的记录,因此这种方式抽取的记录的随机性不是很好,但返回的数据以数据块为单位,抽样性能很高,适用于抽样效率优先的场景,例如抽样大小为GB的日志表;而BERNOULLI抽样方式基于数据行,相比SYSTEM抽样方式所抽样的数据随机性更好,但性能相比SYSTEM差很多,适用于抽样随机性优先的场景,读者可根据实际应用场景选择抽样方式。
聚合函数可以对结果集进行计算,常用的聚合函数有avg()、sum()、min()、max()、count()等,本节将介绍PostgreSQL两个特殊功能的聚合函数并给出测试示例。
在介绍两个聚合函数之前,先来看一个应用场景,假如一张表有以下数据,如下:
country | city
---------+------
中国 | 台北
中国 | 香港
中国 | 上海
日本 | 东京
日本 | 大阪
(5 rows)
要求得到如下结果集:
中国 台北,香港,上海
日本 东京,大阪
这个SQL大家想想如何写?
string_agg函数
首先介绍string_agg函数,此函数语法如下:
简单的说string_agg函数能将结果集某个字段的所有行连接成字符串,并用指定delimiter分隔符分隔,expression表示要处理的字符类型数据;参数的类型为(text, text) 或 (bytea, bytea),函数返回的类型同输入参数类型一致,bytea属于二进制类型,使用情况不多,我们主要介绍text类型输入参数,本节开头的场景正好可以用string_agg函数处理。
将city字段连接成字符串如下:
mydb=> SELECT string_agg(city,',') FROM city;
string_agg
--------------------------
台北,香港,上海,东京,大阪
(1 row)
可见string_agg函数将输出的结果集连接成了字符串,并用指定的逗号分隔符分隔,回到本文开头的问题,通过以下SQL实现,如下所示:
mydb=> SELECT country,string_agg(city,',') FROM city GROUP BY country;
country | string_agg
---------+----------------
日本 | 东京,大阪
中国 | 台北,香港,上海
array_agg函数
array_agg函数和string_agg函数类似,最主要的区别为返回的类型为数组,数组数据类型同输入参数数据类型一致,array_agg函数支持两种语法,第一种如下:
输入参数可以是任何非数组类型,返回的结果是一维数组,array_agg函数将结果集某个字段的所有行连接成数组,执行以下查询:
mydb=> SELECT country,array_agg(city) FROM city GROUP BY country;
country | array_agg
---------+------------------
日本 | {东京,大阪}
中国 | {台北,香港,上海}
array_agg函数输出的结果为字符类型数组,其他无明显区别,使用array_agg函数主要优点在于可以使用数组相关函数和操作符。
PostgreSQL提供内置的窗口函数,例如row_num()、rank()、lag()等,除了内置的窗口函数外,聚合函数、自定义函数后接OVER属性也可作为窗口函数。
窗口函数的调用语法稍复杂,如下所示:
function_name ([expression [, expression ... ]]) [ FILTER ( WHERE filter_clause ) ] OVER ( window_definition )
其中window_definition语法如下:
[ existing_window_name ]
[ PARTITION BY expression [, ...] ]
[ ORDER BY expression [ ASC | DESC | USING operator ] [ NULLS { FIRST | LAST } ] [, ...] ]
[ frame_clause ]
OVER表示窗口函数的关键字。
PARTITON BY属性对查询返回的结果集进行分组,之后窗口函数处理分组的数据。
ORDER BY属性设定结果集的分组数据的排序。
row_number() 窗口函数
创建一张成绩表并插入测试数据,如下所示:
CREATE TABLE score ( id serial primary key,
subject character varying(32),
stu_name character varying(32),
score numeric(3,0) );
INSERT INTO score ( subject,stu_name,score ) VALUES ('Chinese','francs',70);
INSERT INTO score ( subject,stu_name,score ) VALUES ('Chinese','matiler',70);
INSERT INTO score ( subject,stu_name,score) VALUES ('Chinese','tutu',80);
INSERT INTO score ( subject,stu_name,score ) VALUES ('English','matiler',75);
INSERT INTO score ( subject,stu_name,score ) VALUES ('English','francs',90);
INSERT INTO score ( subject,stu_name,score ) VALUES ('English','tutu',60);
INSERT INTO score ( subject,stu_name,score ) VALUES ('Math','francs',80);
INSERT INTO score ( subject,stu_name,score ) VALUES ('Math','matiler',99);
INSERT INTO score ( subject,stu_name,score ) VALUES ('Math','tutu',65);
avg() OVER()窗口函数
聚合函数后接OVER属性的窗口函数表示在一个查询结果集上应用聚合函数,本小节将演示avg()聚合函数后接OVER属性的窗口函数,此窗口函数用来计算分组后数据的平均值。
查询每名学生学习成绩并且显示课程的平均分,通常是先计算出课程的平均分,之后score表再与平均分表关联查询,如下所示:
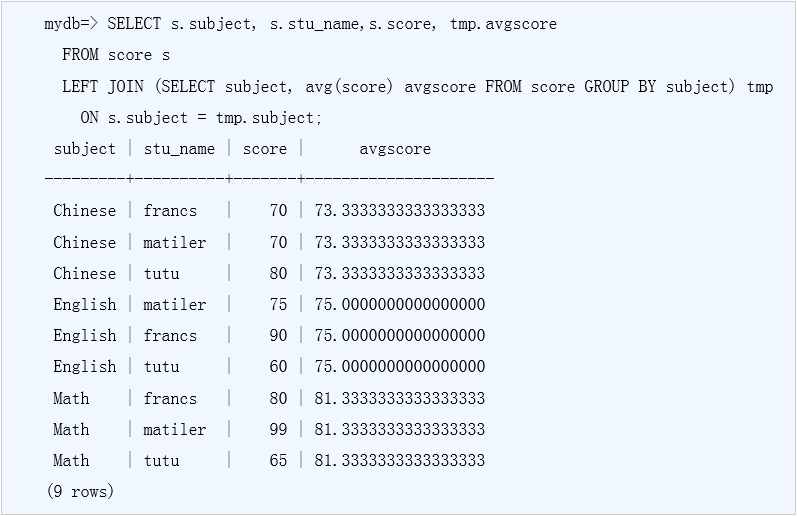
使用窗口函数很容易实现以上需求,如下所示:
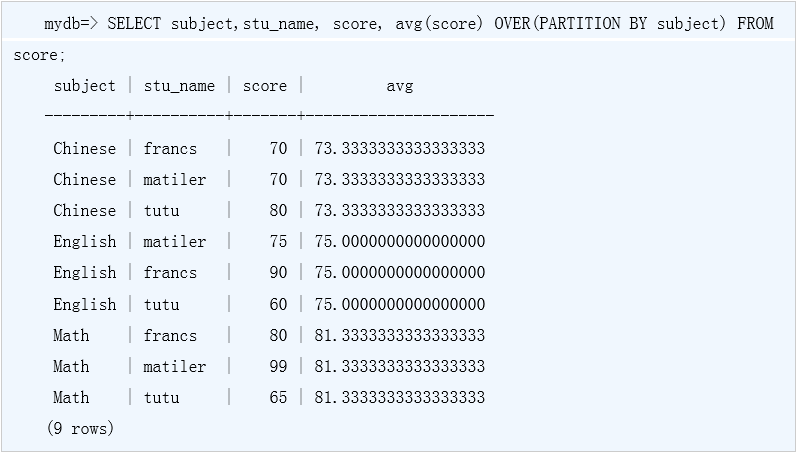
以上查询前三列来源于表score,第四列表示取课程的平均分,PARTITION BY subject表示根据字段subject进行分组。
rank()窗口函数
rank()窗口函数和row_number()窗口函数相似,主要区别为当组内某行字段值相同时,行号重复并且行号产生间隙(手册上解释为gaps),如下:

以上示例中,Chinese课程前两条记录的score字段值都为70,因此前两行的rank字段值1,而第三行的rank字段值为3,产生了间隙。
dense_rank ()窗口函数
dense_rank ()窗口函数和rank ()窗口函数相似,主要区别为当组内某行字段值相同时,虽然行号重复,但行号不产生间隙(手册上解释为gaps),如下:
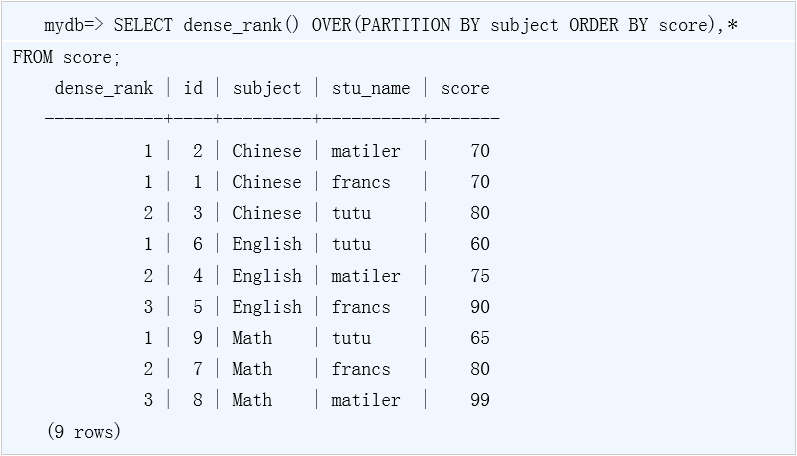
以上示例中,Chinese课程前两行的rank字段值1,而第三行的rank字段值为2,没有产生间隙。
PostgreSQL还支持很多其它内置窗口函数,例如、lag()、first_values()、last_values()等,篇幅关系不再介绍。
二、总结
本篇文章主要介绍了PostgreSQL支持的一些高级SQL特性,例如WITH查询、批量插入、RETURNING返回DML修改的数据、UPSERT、数据抽样、聚合函数、窗口函数等,了解这些功能能够简化SQL代码,提升开发效率,并且实现普通查询不容易实现的功能,希望通过阅读本章,大家能够在实际工作中应用SQL高级特性,同时挖掘PostgreSQL的其它高级SQL特性。
PostgreSQL不仅是关系型数据库,同时支持NoSQL特性,关于PostgreSQL的NoSQL特性我们将在下一篇文章中介绍。
新书抢先看
在本文微信订阅号(dbaplus)评论区留言,谈谈#你一般通过哪些途径了解并学习PostgreSQL#或#在使用、学习PostgreSQL过程中遇到的最大困难#,小编将在本文发布后的隔天中午12点选出留言最精彩的一位读者,送出以下书籍一本~
本文精选自《PostgreSQL实战》一书的第四章“SQL高级特性”,可以登陆网址:https://item.jd.com/12405774.html 购入。更多精华内容也将由dbaplus社群陆续呈现。

*特别鸣谢机械工业出版社为本次活动提供图书赞助

更多数据库探索与实战,尽在2018 Gdevops全球敏捷运维峰会北京站!峰会议题覆盖AIOps与DevOps落地、数据库选型、SQL优化、技术管理等多方面实战,全方位助你满血前进!
↓↓↓ 点击链接了解更多详情 ↓↓↓






