Python网络爬虫与信息抽取笔记02 HTTP协议介绍
【导读】我们在上一节的内容中已经为大家针对requests库入门进行讨论,这一节将主要讨论HTTP协议。本文内容涉及HTTP协议的若干主要问题:HTTP协议介绍,URL格式,HTTP协议对资源的操作以及Requests库7个主要方法详解。话不多说,让我们一起学习这些内容吧。
Python网络爬虫与信息抽取笔记01 课程框架和Python IDE工具
Python网络爬虫与信息抽取笔记02 requests库入门
视频网址:
https://www.bilibili.com/video/av9784617?from=search&seid=240663710546169136
http://www.icourse163.org/course/BIT-1001870001?tid=1001962001
Python网络爬虫与信息抽取03 HTTP协议
1.HTTP协议介绍
HTTP协议是浏览器上的超文本传输协议,是基于“请求与响应”、无状态的应用层协议,所谓无状态指的第一次请求和第二次请求没有关联。

2.URL格式
HTTP中的URL链接有固定格式,host、port和path都有其各自代表的内容。

下面是HTTP几个URL的例子,感觉URL链接和指针挺像的。

3.HTTP协议对资源的操作
HTTP协议有6种方法对URL资源可以操作。

其中get,head是获取资源,put,post,patch以及delete是操纵资源

注意patch和put是有区别的,patch可以局部修改,put要一次性全部修改

其实HTTP协议和Requests库中的方法功能有着对应关系
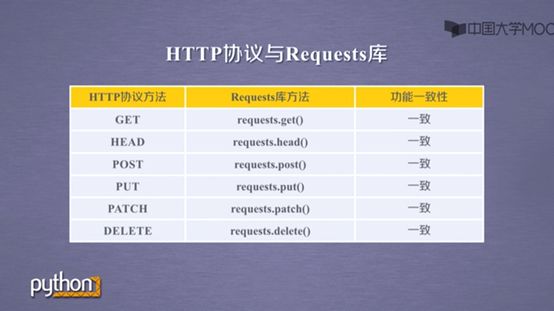
requests.head()可以得到服务器返回响应的头部信息

requests.post()为向URL位置后的资源附加新的数据。该数据如果是字典,自动编码为form

该数据如果为字符串,编码为data

requests.put() 功能则是请求向URL位置存储一个资源,覆盖原URL位置的资源

4.Requests库7个主要方法详解
Requests库的函数功能就对应着HTTP相应的方法

requests.request()是支撑各种方法的基础方法

可以用requests.request实现各种功能

Params是url的参数

Data则是传递的字典、字节序列或者文件对象,Data是提供的键值对不放在url链接里,而是放在url链接对应的位置作为数据来存储

json则传递JSON格式的数据,这个数据复制到服务器的json上

Headers则是HTTP定制头

Cookie和auth,值得注意的是auth是元组类型,支持HTTP认证功能

files代表传输的文件,可以给某一个链接提交一个文件

Timeout用来设置超时时间

Proxies设定代理服务器
一个是http的代理,在这个代理中我们可以增加用户名和密码的设置
另一个是https的服务器,在访问百度时所使用的ip地址就是代理服务器的ip地址
还有其他参数,由于用的很少就不一一细讲了

requests.get()函数的格式

requests.head函数的格式

requests.post函数的格式

requests.put函数的格式

requests.patch函数的格式

requests.delete函数的格式

在http协议中,向url提交资源的功能在服务器上是严格受控的,有很大的安全问题。
所以用的最多的是get。
参考链接:
http://www.icourse163.org/course/BIT-1001870001?tid=1001962001
更多教程资料请访问:人工智能知识资料全集
-END-
专 · 知
人工智能领域主题知识资料查看与加入专知人工智能服务群:
【专知AI服务计划】专知AI知识技术服务会员群加入与人工智能领域26个主题知识资料全集获取

[点击上面图片加入会员]
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请加专知小助手微信(扫一扫如下二维码添加),加入专知主题群(请备注主题类型:AI、NLP、CV、 KG等)交流~

请关注专知公众号,获取人工智能的专业知识!
点击“阅读原文”,使用专知