专知内容生产基石-数据爬取采集利器WebCollector 介绍
今天给大家介绍下我们专知数据采集系统的基石-WebCollector。 作为主流JAVA开源爬虫框架(GitHub上1500+Stars),WebCollector 轻量级、便于二次开发的特点得到了众多数开发者的选取与喜爱。特别与大家分享的是WebCollector的作者Hujunxianligong大神就是我们专知团队的成员。下面开始给大家简单介绍下WebCollector的特性以及在专知的应用。
WebCollector简介
WebCollector 是一个无须配置、便于二次开发的 Java 爬虫框架(内核),它提供精简的的 API,只需编写配置少量代码即可实现一个功能强大的爬虫系统。WebCollector -Hadoop 是 WebCollector 的 Hadoop 版本,支持分布式爬取。
WebCollector入口:百度Google 直接搜索 WebCollector即刻获取。
Github上地址:https://github.com/CrawlScript/WebCollector
1)内核构架图

WebCollector的任务执行流程如上,包括爬取任务生成更新调度管理、任务执行数据爬取、爬取数据信息抽取以及持久化存储。
2)WebCollector 2.x 特性
WebCollector 现已经为2.71版本,基本特性有:
自定义遍历策略,可完成更为复杂的遍历业务,例如分页、AJAX
可以为每个 URL 设置附加信息(MetaData),利用附加信息可以完成很多复杂业务,例如深度获取、锚文本获取、引用页面获取、POST 参数传递、增量更新等。
使用插件机制,用户可定制自己的Http请求、过滤器、执行器等插件。
内置一套基于内存的插件(RamCrawler),不依赖文件系统或数据库,适合一次性爬取,例如实时爬取搜索引擎。
内置一套基于 Berkeley DB(BreadthCrawler)的插件:适合处理长期和大量级的任务,并具有断点爬取功能,不会因为宕机、关闭导致数据丢失。
集成 selenium,可以对 JavaScript 生成信息进行抽取
可轻松自定义 http 请求,并内置多代理随机切换功能。 可通过定义 http 请求实现模拟登录。
使用 slf4j 作为日志门面,可对接多种日志
使用类似Hadoop的Configuration机制,可为每个爬虫定制配置信息。
3)WebCollector 使用
官网:
https://github.com/CrawlScript/WebCollector
镜像:
http://git.oschina.net/webcollector/WebCollector
在Eclipse、Netbeans、Intellij等IDE参照Github配制Maven即可使用,或者使用Jar包。
<dependency> <groupId>cn.edu.hfut.dmic.webcollector</groupId> <artifactId>WebCollector</artifactId> <version>2.71</version> </dependency>
自动爬取新闻网站的例子通过简单配制即可完成:

更多实用请访问WebCollector 主页或者
WebCollector项目主页 http://datahref.com/
WebCollector在专知的使用
我们基于WebCollector构建了实时定点数据采集系统,针对全网的AI内容进行精选采集。基本框架如下图所示。

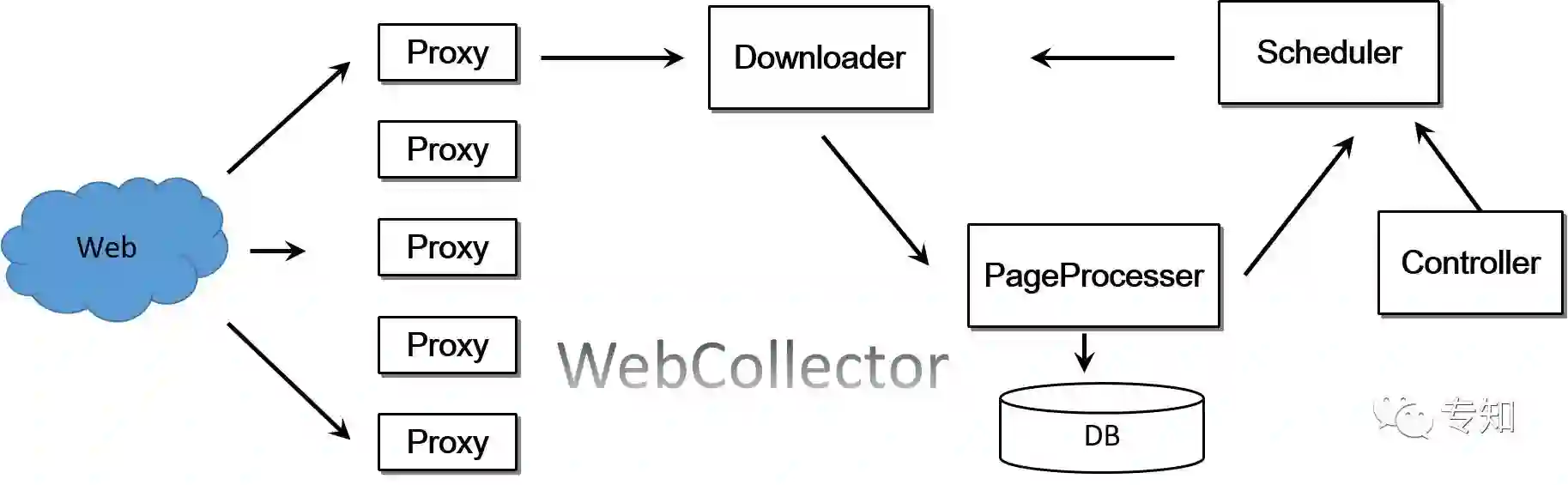
数据采集系统包含代理配置管理、下载器、调度器、内容解析、控制器等,来可扩展性地可配置化采集内容。
感兴趣的同学加入专知——数据采集交流群(请先加微信小助手weixinhao: Rancho_Fang)或者是QQ群专知-人工智能交流群 426491390
欢迎大家使用专知!点击阅读原文即可访问,访问获取更多专知技术算法资源。
同时请,关注我们的公众号,获取最新关于专知以及人工智能的资讯、技术、算法等内容。扫一扫下方关注。

阅读更多:了解使用专知,为你提供一站式AI知识服务。