「智慧计算」对AI起到多大助力?

图:pixabay
人工智能诞生60年了,我们现在每天都能够看到不同新算法、新架构、新工具在AI领域的应用。其实,数年前,AI还没有现在这么热,当时的科学家提出各种不同的想法完全是对当时运行缓慢、体积臃肿,以及昂贵机器的妥协。
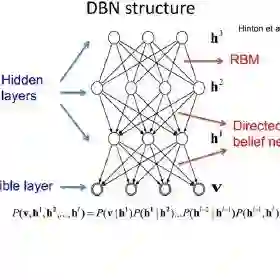
2006年,深度学习这一概念随着Geoffrey Hinton等人发表的论文而大热,深度信念网络(DBN)被提出,这种快速学习算法可用于受限玻尔兹曼机(RBM),深度学习开始迅速腾飞。而该算法需要在成千上万的并行处理器上运行。而改变这一切的,正是计算机的运行速度,当然,还有价格因素。
从整体角度来看,计算力、大数据、算法这三者对于人工智能的助推作用是其加速发展的必要条件。具体来看,计算力的提升,随着时间的推移,针对深度学习的计算机软硬件设施都有所改善,深度学习模型的规模也随之增长。
可以说,深度学习的出现、神经网络理论重新被人提及是与一个重要的定律分不开的,那就是“摩尔定律”。深度学习的训练过程需要数百万计,甚至亿计的数据量,同时,神经网络无论是深度,还是复杂度都是几十年前的数百倍,而这些在90年代以前是不可想象的。同时GPU性能的高速提升,以及其近几年价格的迅速降低,亦促进了深度学习的大面积应用。
既然计算力对于人工智能如此重要,那么“智慧计算”便应运而生了。何为“智慧计算”?中国工程院院士、浪潮集团执行总裁王恩东曾表示,智慧计算“以云计算为基础平台、大数据为认知方法,深度学习为优化工具”。他认为,智慧计算的出现实际上是计算技术发展"分而后合"的一种选择,最初的数学计算演变为科学计算和商业计算两大分支,并在之后的60年中衍生出诸如高性能计算、数据库、关键计算、云计算、大数据、深度学习等众多计算类型。而随着云计算、大数据和深度学习的相互促进、相互融合、共同发展,科学计算与商业计算再次"合二为一",催生了智慧计算这种新的计算类型。

浪潮执行总裁王恩东
伴随着传统计算到大数据、深度学习等新兴的智慧计算转型,作为基本计算设备——服务器的设计也迎来了升级挑战。而就在近日,作为中国服务器的领军企业,浪潮M5服务器的发布便进入了机器人圈的视野,而吸引机器人圈留意的,除了其丰富的AI产品线布局、针对深度学习优良的产品性能本身,更是浪潮大踏步开拓AI市场的决心,以及在智慧计算领域绝对的信心。
智慧计算与AI“相生相依”
今年年初,浪潮宣布成立人工智能事业部,而在这背后,则是其立足行业的实力。根据Gartner和IDC2017Q1最新数据表明,浪潮服务器的销售额、销售量在中国市场稳居第一,互联网行业稳居第一,同时浪潮已成为中国AI领域最大的计算平台供应商。

浪潮集团副总裁彭震
实际上,为了应对人工智能时代,智慧计算已经成为“逃不掉”的话题,我们现在经常探讨的无人驾驶、AlphaGo、人脸识别等,都是智慧计算的具体呈现。浪潮集团副总裁彭震在现场表示:“智慧计算实际上它是以云计算为计算的平台,以大数据为认知的方法,以深度学习为优化工具,未来的智慧计算都会构建在云计算的平台之上,以更大规模、分布式的计算模式进行。同时,所有的东西都是基于大数据,基于大量的海量数据的统计、分析,基于深度学习这样的一种学习方法使得我们具备了足够的智慧计算能力。”
过去的服务器主要面向通用市场设计,一个服务器适用于多种场景,而随着大规模部署的数据中心的出现,以及云计算、大数据、人工智能等应用场景的不断深化,实际上服务器也发生了非常大的、本质性的变化。基于以上三大场景,浪潮推出了新一代服务器M5。
“最领先”我敢拍胸脯
在当天的媒体专访环节,彭震表示:“从某种角度来说,我们现在在AI方面的产品应该是全球‘最领先’的。我们敢拍着胸脯说这句话,可能云计算、大数据,大家都各有所长,我们也很难确定地说,浪潮就是第一,但我认为浪潮的AI产品一定是全球最丰富的。”
彭震说这话的底气源自于浪潮针对AI领域的丰富布局。我们一起来看看:
浪潮拥有2U2、2U4、2U8的GPU服务器,以及4GPUBox、国内唯一的16GPUBOX。在美国GTC17上,浪潮推出加速人工智能计算的超高密度服务器AGX-2;在IPF上,浪潮与百度联合发布了面向更大规模数据集和深层神经网络的超大规模AI计算平台—SR-AI整机柜服务器;在德国ISC17上,浪潮发布了可灵活扩展的新型AI加速计算产品GX4……
AI服务器中的“超算”
众所周知,机器学习在模型训练阶段需要百万级次的迭代,而这当然需要GPU的性能发挥出最大效能。从这个角度看,在发布会现场,最吸引机器人圈眼球的无疑是浪潮刚刚推出的NF5288M5 GPU服务器。据现场的产品经理介绍,与传统的PCIe- GPU服务器相比,该服务器的GPU单独效能可以提高60%以上,这是浪潮迄今为止研发的GPU密度最高的一款服务器,“当然从全球来看,这是浪潮提供的密度最高的支持8块nvLink GPU的服务器”,他补充道。

拥抱开源
实际上,随着深度学习时代的到来,越来越多的大厂商开始开源,把各自的资源贡献出来。在深度学习框架领域,比较知名的有谷歌的TensorFlow、微软的CNTK 、已被亚马逊官方采用的MXNet、LISA lab的Theano,其中在图像处理领域,我们不得不提的就是于UC Berkeley诞生的Caffe,而Caffe是单机版的,并没有针对大量网络环境情况下的版本。
针对上述情况,浪潮发布了集群版的Caffe版本——Caffe-MPI,并在GitHub上开源公布所有代码,以此为客户提供更强大的深度学习平台。根据浪潮提供的官方数据,使用GoogleNet模型,在不同GPU数量的情况下,对比每秒处理图像的速度,Caffe-MPI几乎是TensorFlow的两倍。
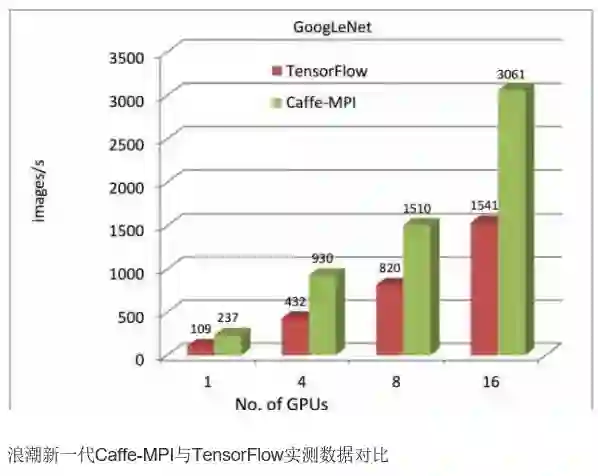
“Caffe并没有做更多的并行化,偏实验性,但是相对比较成熟。所以,我们在里面做了大量的并行化的工作,就是为了给客户做大规模并行学习提供的这样一种能力。所以,我们做了很多的开源投入。”对于为何在开源方面投入资源,彭震补充道:“当然,这一切源于浪潮在HPC上有很多积累,在整个程序的并行化和优化方面有很多积累,我们希望它能够变成一个帮助客户提升业务能力的一个平台,所以我们做了这个事情。”
其实,浪潮对于开源,远不止Caffe-MPI这一件事这么简单。实际上,本次M5新一代产品里采用了很多的开放标准和协议,全线引入Open BMC和Redfish。浪潮目前亦积极参与并设计开放的硬件平台和标准,加入多个开源社区,比如OpenStack、OCP、ODCC、Open19等。
“对于开源而言,云计算造就了开源,开源成就了云计算?在云计算的场景里,大家不希望被某一厂商锁定,需要一个更加开放的平台。实际上,当有了云计算之后,客户希望要自主可控,开源社区便应运而生,之后又极大地推动了云计算的普及,把过去很多的技术门槛全部打掉了,使得很多开发者能够快速地进入到某一领域,推出一个自己觉得不错的开源系统。”彭震解释道,“云计算需要管理那么多设备、有那么多应用,面向这么多复杂的场景,这根本不是任何一个厂商所能够自己对付得了的,所以需要集所有人各种各样的力量参与进来一块做。”
浪潮将开源上升为整个公司的策略,并将其定位于“源于开源、回馈开源、高于开源”。彭震最后强调:“我们在设计里还是有自己压箱底的东西,要高于开源,做出更多创新的东西,要领先别人。”
纵观整个发布会,我们不难发现,在智慧计算时代下,浪潮在AI产品线提供了最完整的AI解决方案,同时在云计算和大数据领域,浪潮亦提供了完整的产品布局。可以说,浪潮M5新一代服务器产品将帮助客户应对智慧计算时代带来的挑战,助力客户向智慧时代转型。

中国人工智能产业创新联盟在京成立 近200家成员单位共推AI发展

关注“机器人圈”后不要忘记置顶哟
我们还在搜狐新闻、机器人圈官网、腾讯新闻、网易新闻、一点资讯、天天快报、今日头条、QQ公众号…
↓↓↓点击阅读原文查看中国人工智能产业创新联盟手册