【KDD2020】 半监督迁移协同过滤推荐

推荐系统的数据稀疏性是一个固有的挑战,因为推荐系统的大部分数据都来自于用户的隐式反馈。这就带来了两个困难:
一是大部分用户与系统的交互很少,没有足够的数据进行学习;
二是隐式反馈中不存在负样本。通常采用负样本的方法来产生负样本。
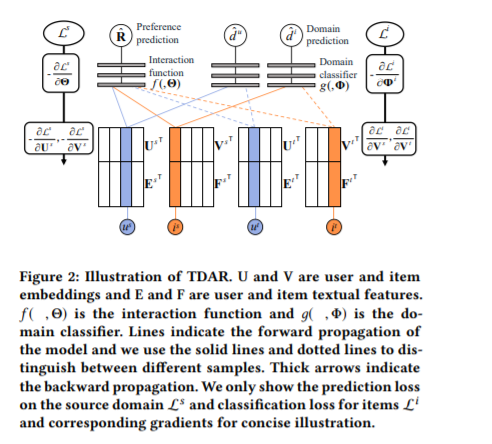
然而,这导致了许多潜在的正样本被误标记为负样本,数据的稀疏性会加剧误标记问题。这是容易解释的,因为:用户购买了某一商品,你可以说他喜欢这一商品;但是用户如果没有买的那些商品,你没有办法说他就不喜欢。为了解决这些困难,作者没有像其他的做法一样,而是将稀疏隐式反馈的推荐问题作为半监督学习任务,并探索领域适应(Domain Adaptation)来解决这个问题。具体地,是将从密集数据中学习到的知识转移到稀疏数据中,并专注于最具挑战性的没有用户或项目重叠的情况。
在这种极端情况下,直接对齐两个数据集的嵌入并不理想,因为这两个潜在空间编码的信息非常不同。因此,作者采用领域不变(domain-invariant)的文本特性作为锚点来对齐潜在空间。为了对齐嵌入,我们为每个用户和项提取文本特性,并将它们与用户和物品的嵌入一起提供给域分类器。训练嵌入来迷惑分类器,并将文本特征固定为锚点。通过域适应,将源域内的分布模式转移到目标域。由于目标部分可以通过区域自适应来监督,因此我们在目标数据集中放弃了负采样以避免标签噪声。
https://arxiv.org/abs/2007.07085
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“SCFD” 可以获取《【KDD2020】 半监督迁移协同过滤推荐》专知下载链接索引



登录查看更多
相关内容

Arxiv
4+阅读 · 2020年12月23日
Arxiv
4+阅读 · 2018年3月26日


相关VIP内容
相关资讯
相关论文
Arxiv
4+阅读 · 2020年12月23日
Arxiv
4+阅读 · 2018年3月26日