AI 编程“神器”国产化!华为耗时 8 个月,这个能用中文生成代码的模型诞生了

作为近年来最火的科技突破之一,AI 的应用已逐渐渗透至方方面面。前有各类 AI 工具写小说、编剧本、画插图,后有 AI 代码生成神器 GitHub Copilot 帮写代码,解放程序员的双手。
在此热潮下,近日华为研制出了当前业界最新的代码生成模型 HUAWEI PanGu-Coder。据介绍,HUAWEI PanGu-Coder 由华为诺亚方舟实验室语音语义实验室联合华为云 PaaS 技术创新实验室共同研发,不但熟悉常见算法,还能熟练地使用各种 API,甚至可以求解高等数学问题。在代码生成的一次通过率(PASS@1)指标上,HUAWEI PanGu-Coder 大幅超越同等参数规模的模型,为更好地服务使用中文的开发者,它在中文上也有十分出色的表现。
目前,处于内测阶段的 HUAWEI PanGu-Coder 还在不断迭代与演进,尚未正式对外开放,但我们或许可以通过对华为云 PaaS 技术创新实验室主任王千祥的访谈,提前窥见有关 HUAWEI PanGu-Coder 的更多细节及其从无到有的故事。

HUAWEI PanGu-Coder 诞生前传
科技圈中近年来一直流传着一句话:软件正在吞噬世界。
这句话所代表的数字化转型意味着大量的编码工作,背后则是无数程序员的辛苦劳动。但伴随着数字化转型日益成为大势所趋,程序员肩负的重担也愈发沉重。王千祥指出:“与各个行业对代码的需求相比,目前程序员的产出差距还是太大了。”
针对这一痛点问题,AI 代码生成模型正在成为破局的关键,成为提升代码产出率的利器。
实际上,王千祥在北大时就曾探索过这个技术,后来入职华为也时常琢磨,但当时并没有投入太多。他在 2018 年还曾就这个话题与华为创始人任正非简单讨论过:“我当时说,AI 编程离进入实用阶段还很远,但任总不这么认为。”
因此,当去年 6 月微软发布了 Copilot,王千祥发现其背后模型 Codex 在解答 OJ 题(Online Judge,在线编程练习系统)方面取得了突破性进展(正确率高达 70% 以上)时,给了他相当大的震撼,也由此激发出要打造一款国产代码生成模型的决心:“微软的 Copilot 集成了 Codex 的能力,很好地展示出了代码生成模型的威力。华为既然长期关注软件开发能力的提升,希望利用智能化技术来提升软件开发的生产力,自然需要开展这方面的研发。”
在王千祥所在的华为云 PaaS 技术创新实验室关注到 Codex 的同时,华为诺亚方舟实验室语音语义实验室也在研究此事,而推动双方决定共同加大研发力度的,主要有两件事:一是去年 9 月 OpenAI CEO 预告 GPT-4 将更关注代码;二是去年 10 月 Github 声明内部团队中 30% 的新代码是在 Copilot 的帮助下完成的,同时 Copilot 的用户留存率也超过了 50%。
基于此,去年 11 月华为云 PaaS 技术创新实验室和华为诺亚方舟实验室语音语义实验室共同成立了一个联合工作组,以打造一款国产代码生成模型为目标,在 12 月正式开工——于是,HUAWEI PanGu-Coder 项目开始启动。
考虑到目前在该领域中较著名的唯有 OpenAI 的 Codex 和 DeepMind 的 AlphaCode,便可以预想到,开发一款成熟的 AI 代码生成模型并不容易。王千祥坦言,在 HUAWEI PanGu-Coder 的整个开发过程中,他们面对的困难不仅源自客观资源,也来自主观上的质疑。
第一个挑战:计算资源
如谷歌 2 月份发表的论文显示,AlphaCode 参加编程竞赛时,每道题都投入了 7500 多张 TPU 卡——训练大模型需要大量计算资源,这个是业界共识,这也就是为什么只有少数大型企业才能开展这方面的探索。在训练 HUAWEI PanGu-Coder 时,开发团队为解决计算资源不足的难题,向华为内部的 AI 全栈软硬件生态进行了协调。
第二个挑战:各种质疑
质疑来自很多方面。首先是公司内部的,很多同事、包括高级专家都认为程序员不太可能接受这样的代码。其次是公司外部的,在 Copilot 推出不久,王千祥联系了几位在美国微软工作的学生,发现他们甚至没听说过这项技术。这让他开始仔细考虑 AI 生成代码的应用场景。

将 3 亿参数的 HUAWEI PanGu-Coder 模型训练到最优
历经 8 个月,克服重重阻碍,HUAWEI PanGu-Coder 终于在今年 7 月底问世了。
由于 PanGu-Alpha 所采用的的自回归 Transformer 架构具备强大的文本生成能力,因此 HUAWEI PanGu-Coder 也将此模型架构用于代码生成任务。其架构如下图所示:
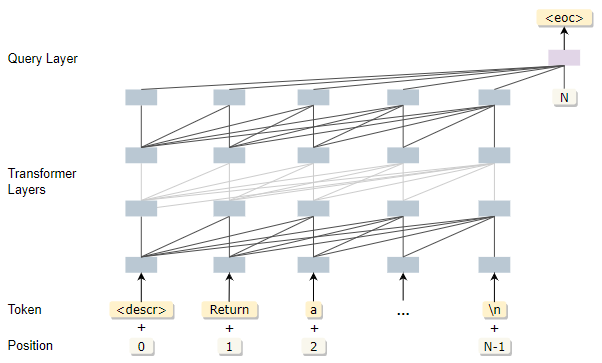
同时,HUAWEI PanGu-Coder 也沿用了 PanGu-Alpha 的中英文多语词表,具备支持中英文输入的能力,尤其在中文上的表现也十分出色。
“这其实是一个超出预期的结果,因为我们在收集和加工训练数据时并没有刻意包含中文。”HUAWEI PanGu-Coder 开发团队对这一现象进行了深入的分析,应该是预训练模型具备优秀的跨语言迁移能力,训练总数量又很大(超过两千亿 token 数),从而促成了 HUAWEI PanGu-Coder 能够很好地支持中文描述。
目前,华为开发团队正在训练多个规模的 HUAWEI PanGu-Coder 模型,包括 3 亿参数、26 亿参数甚至更大规模的,但王千祥透露,现阶段更关注如何将 3 亿参数的模型训练到最优。
“现阶段很多参数量很大的模型并没有被充分训练,更大的参数也意味着推理成本增加和响应时间变长。因此在算力成本受限的情况下,是存在一个最优模型规模的,并非越大越好。”
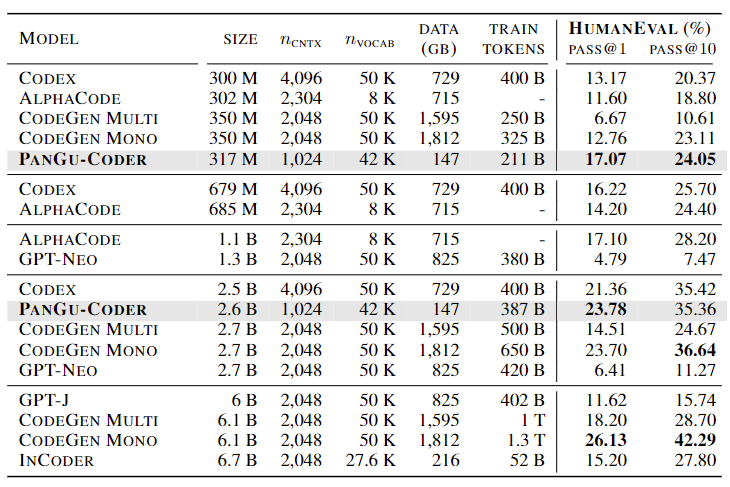
事实证明,这个想法是正确的。模型的一次生成通过率(PASS@1)是代码语言生成模型最重要的能力衡量指标,从这个数据上来看,采取数据集构建策略和分阶段训练设计的 HUAWEI PanGu-Coder 在 3 亿级别上的准确率相比其它公开模型要高很多:3 亿参数的 HUAWEI PanGu-Coder 模型(PASS@1=17.07%)超越了 Codex(PASS@1=16.22%)接近 7 亿参数的模型结果,基本持平了谷歌 10 亿的模型。
HUAWEI PanGu-Coder 模型目前已集成到了华为云的代码开发辅助工具中,可以在 IDE 插件中使用自然语言描述生成函数级的 Python 代码,或根据上下文进行补全。值得一提的是,这个基于 HUAWEI PanGu-Coder 内核构建的 IDE 插件在前后处理上有很大的发挥空间,为尽可能生成更可靠、可用的代码,该插件融合了华为近年来在代码可信方面的积累,并通过后处理的方式来保证提供给程序员的代码质量。
得益于以上措施,HUAWEI PanGu-Coder 在内测阶段已表现不俗:熟悉常见的数据结构算法、会写 SQL 查询功能,能使用机器学习工具创建文本分类器,还能求解高等数学题。
以下例举两个 HUAWEI PanGu-Coder 在内测中的实际表现:
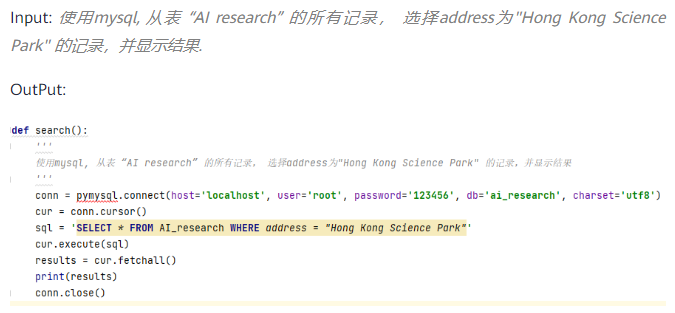
用中文让 HUAWEI PanGu-Coder 编写 SQL 查询语句
让 HUAWEI PanGu-Coder 求微分:

为了进一步让 HUAWEI PanGu-Coder 更贴合真实的编程场景,而不是目前各文章介绍的编程竞赛场景,其开发团队目前还在努力提升代码生成的能力,计划未来对外发布具备代码生成能力的 IDE 插件。

“工具是人类的助手,而非杀手”
然而,随 着 Codex、HUAWEI PanGu-Coder 等越来越多 AI 代码生成模型的出现,开发者圈内有关它们的争议和讨论也愈发激烈,对此王千祥也给出了他的独到见解。
CSDN:从行业角度来看,自微软 AI 编程工具 GitHub Copliot 推出以来,不少人对生成的代码版权问题一直表示担忧,HUAWEI PanGu-Coder 在代码生成上是否有这样的困扰?
王千祥:我们注意到了一些个人与团体对代码生成的版权疑虑。在我看来,首先,知识共享是社会进步的重要因素;其次,共享的同时要尊重原创者。像学术界的研究工作,需大量参考其他同行的进展,并在文章中列出参考文献。开源是新时代的知识共享方式,并由此衍生出了很多不同的开源协议。
目前的 AI 代码生成技术,是利用机器学习技术以及大量开源代码去训练一个模型,然后利用这个模型将一段自然语言转换为代码。这个过程就像是一个程序员新手阅读了大量开源代码后,具备了一定的能力,在遇到类似问题时,会参考着编写出类似的新代码。只要写出来的代码不是对原来代码的简单复制,我认为不必上升至版权问题的层面。
当然,版权问题一个不是单纯的技术问题,现在还缺乏一些共识,新的开源协议也在不断产生,从而促进创新并保护原创。
CSDN:你如何看待“代码生成工具的普及将逐渐取代程序员人类”这种言论?
王千祥:这种言论类似于 19 世纪出现的“机器的普及将逐渐取代工人”的说法,这个担心是没有必要的。
实际上,从微软 Copilot 的名字上也可以看出:Copilot 是程序员的协同驾驶员,是程序员的聪明助手。代码生成工具也有它的适用场景,那就是重复性的低级编码。软件开发是充满创新的智力活动,让工具去做重复性劳动,节省出程序员的一些时间,投入到更高价值的创新活动中不是很好吗?工具是人类的助手,而非杀手。
当然,具体到程序员个人层面,则需要逐步提升能力,不要与工具去争抢低级重复性劳动。另外,还有一点需要强调,代码生成工具的能力是有边界的,不要对它期待值过高,以免产生不切实际的期望。
CSDN:HUAWEI PanGu-Coder 的到来,将为开发者带来哪些影响?在使用方面,你有哪些建议可以给到开发者?
王千祥:开发者的新生力量可能更容易受影响,因为新人往往更愿意去接触新技术。如果要给开发者一些建议的话,我建议大家以后着重增强自己的设计能力,并多利用工具的实现能力。这些设计能力主要包括:
1)如何用机器容易懂的方式描述意图;
2)如何准确地定义接口,尤其是方法级的接口;
3)如何给出最佳的测试数据,用来自动验收工具生成的代码。
☞