代替程序员?微软推出会编程的AI后,又让AI学会了代码审查

目前,各类可调大型预训练语言模型(包括 GPT-3、Codex 等)已经能够根据程序员用自然语言表达的意图,成功编写出代码。这类自动化模型当然有望提升每一位软件开发从业者的生产效率,但也由于模型自身难以理解程序语义,因此尚无法保证生成代码的最终质量。
在我们的研究论文《Jigsaw:当大型语言模型牵手程序综合》(Jigsaw: Large Language Models meet Program Synthesis,文章已被国际软件工程会议 ICSE 2022 接收)中,我们介绍了一种可以提高这类大型语言模型性能的新工具。Jigsaw 中包含可以理解程序语法及语义的后处理技术,可利用用户反馈不断提升修正能力。配合多模输入,Jigsaw 即可为 Python Pandas API 合成代码。
我们的经验表明,随着这些大型语言模型逐步演变为“按意图合成代码”的利器,Jigsaw 也将在提高系统准确性方面发挥重要作用。
以 OpenAI 的 Codex 项目为代表的各类大型语言模型,正在重塑编程领域的整体面貌。软件开发者如今在处理编程任务时,可以直接对所需代码片段的功能做出英文描述,Codex 则通过 Python 或 JavaScript 等语言合成出预期代码。
然而,机器编写的代码可能并不正确、甚至无法编译或运行。因此,Codex 用户必须在代码使用前进行审查。
在 Jigsaw 项目中,我们的目标就是让审查实现部分自动化,帮助 Codex 等大型语言模型按开发者指示合成代码、提高生产效率。
假定 Codex 为软件开发者提供了一条代码片段,之后开发者可以检查代码能否编译、借此做出初步审查。如果未能编译,则开发者可以参考编译器提供的报错信息进行修复。而一旦代码最终编译完成,开发者则通过输入 / 输出(I/O)开展测试,检查代码所产生的输出是否符合预期。
这一阶段中,代码同样有可能暴露出问题(例如引发异常或产生错误输出),这就要求开发者进一步进行修复。我们证明,这一过程完全可以自动化执行。Jigsaw 将预期代码的英文描述以及 I/O 示例作为输入,再将输入与相关输出进行配对,最终保证 Python 输出代码能够正确编译、且可以根据输入产生符合预期的高质量输出结果。
在之前提到的论文《Jigsaw:当大型语言模型牵手程序综合》中,我们在 Python Pandas 上评估了这种方法。Pandas 是目前在数据科学领域中广泛使用的 API,具有数百个用于操作数据框或行列表的函数。
要让开发者记住这么多函数用法显然太不“人道”,更好的办法当然是使用 Jigsaw。在它的帮助下,用户可以通过英语描述预期转换效果、提供输入数据框与对应的输出数据框,之后由 Jigsaw 合成预期代码。例如,假定开发者希望从下表的“country”列中删除前缀“Name:”,可以在 Pandas 通过执行以下操作来实现:
df['c'] = df['c'].str.replace('Name: ', '')
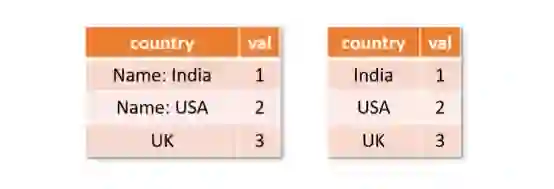
图一:输入数据框与输出数据框。Jigsaw 从名为“country”的列中删除了多余部分“Name:”。
在传统流程中,刚刚接触 Pandas 的开发者往往需要先熟悉函数及其参数,才能整理出相应的代码片段;或者是将查询与示例结果发布到 Stack Overflow 等论坛上,之后坐等热心网友的回复。另外,开发者还时常需要结合上下文背景大幅调整响应。相比之下,直接使用英语来描述自己想要的输入 - 输出表(或数据框)无疑要方便得多。
Jigsaw 首先获取英语查询信息、再配合适当的上下文对查询进行预处理,由此构建起可被馈送至大型语言模型的输入。Jigsaw 模型属于黑箱形式,而且已经使用 GPT-3 及 Codex 完成了评估。
这种设计的最大优势,在于能够以即插即用的形式支持各类最新、最好的可用模型。在模型生成输出代码之后,Jigsaw 就会检查其是否满足 I/O 示例。如果满足,则模型输出正确、代码直接可用。在我们的实验中,约有 30% 的输出代码无需修复、直接可用。但如果代码有误,则在后处理阶段启用修复流程。
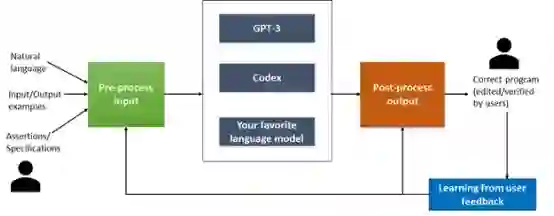
图二:所有供大型语言模型(包括 GPT-3、Codex 等)的输入都将经过预处理。如有必要,后处理输出还将被返回至最终用户进行验证和编辑。学习结果则被反馈至预处理和后处理机制当中,用以进一步改进 Jigsaw 的修正能力。
在后处理过程中,Jigsaw 使用三种转换来实现代码修复。其中每一种转换均由我们在 GPT-3 及 Codex 中观察到的故障模式所驱动。令人意外的是,GPT-3 与 Codex 的代码错误案例间有着极高的相似性,因此 Jigsaw 在后处理中使用的故障模式对二者都有很大帮助。
我们观察到,Codex 的输出中经常会出现不正确的变量名称。例如,大部分公开代码会将数据框命名为 df1、df2 等,所以 Codex 也就直接照搬了过来。然而,如果开发人员实际使用的是 g1、g2 等数据框名称,那么 Codex 对 df1、df2 的坚持就会引发问题。
另外,Codex 还时常把收到的变量名称搞混。例如,正确的输出应该是 df1.merge(df2),但却被它写成了 df2.merge(df1)。为了修复这些错误,Jigsaw 需要把 Codex 生成代码中的名称替换为可用范围内的一切名称,直到其满足 I/O 示例。我们发现,这种简单的转换已经足以解决机器代码中的大多数问题。
有时候,Codex 生成的代码还会调用预期 API 函数,但其中某些参数却存在错误。例如:
a.) 查询 - 删除‘inputB’列中的所有重复行
dfout = dfin.drop_duplicates(subset=['inputB']) # Model
dfout = dfin.drop_duplicates(subset=['inputB'],keep=False) # Correct
b.) 将 df 当中 country 列内的所有 CAN 查询 - 替换为 Canada
df = df.replace({'Canada':'CAN'}) # Model
df = df.replace({'country':{'Canada':'CAN'}) # Correct
为了修复此类错误,Jigsaw 会成系统地枚举一切可能的参数,并以 Codex 生成的函数及参数序列作为起点,直到找出满足 I/O 示例的组合。
AST(抽象语法树)就是以树的形式表示代码。因为 Codex 这类模型会在句法层级上设计代码结构,所以可能会生成句法与预期相近、但某些字符存在问题的输出结果。例如:
a.) 查询 - 选择 dfin 中符合条件的各行,要求其 bar 值 <38 或者>60
dfout = dfin[dfin['bar']<38|dfin['bar']>60] # Model
dfout = dfin[(dfin['bar']<38)|(dfin['bar']>60)] # Correct
错误——缺少括号会改变优先级次序并引发异常
b.) 查询 - 计数 df 中重复行的数量
out = df.duplicated() # Model
out = df.duplicated().sum() # Correct
错误——需要求和以获取重复行的总量
为了修复这类问题,Jigsaw 还提供随时间学习的 AST 到 AST 转换功能。用户首先自行修复代码,再由 Jigsaw UI 捕捉编辑结果、把结果推广到其他适用的转换场景当中,同时学习转换知识。随使用次数与转换次数的增加,Jigsaw 也将逐步掌握开发者的修复思路。
我们还在多种数据集上评估了 Codex 直出代码与 Jigsaw 修复后代码,并测量二者的准确度(即系统能够产生预期结果的情况,在总体数据集任务中所占的百分比)差异。Codex 直出代码的准确度大约在 30% 左右,这也与 OpenAI 论文中的观点相符。Jigsaw 能够将准确度提高到 60% 以上,如果配合用户反馈、则准确度可以进一步拉升至超过 80%。
我们已经发布了可供公开使用的 Jigsaw 评估数据集。每个数据集中包含多项任务,各项任务分别对应一条英语查询与一个 I/O 示例。要解决任务,模型需要生成一段 Pandas 代码,并将提供的输入数据框映射至相应的输出数据框。我们希望大家能以这套数据集为基础,评估并比较更多其他系统。尽管目前部分数据集只包含英语查询加 I/O 示例等简单任务,但 Jigsaw 数据集仍然开创了行业先河。
随着语言模型的不断发展壮大,我们相信 Jigsaw 将一路为其保驾护航、帮助这些大型模型在更多实际场景内发挥作用。当然,这只是相关研究领域内的冰山一角,我们还有以下关键问题需要解决:
这些语言模型能否通过训练掌握代码语义?
Jigsaw 能否集成进更好的预处理与后处理步骤?例如,我们正在研究用表述分析技术改进后处理效果。
I/O 示例对于 Python Pandas 之外的其他 API 是否有效?如果没有相应的 I/O 示例,我们该如何解决?怎样才能使 Jigsaw 适应 JavaScript 等语言以及 Python 中的通用代码?
Jigsaw 目前的输出结果仍有改进空间,就是说除了用自然语言执行查询之外,开发者仍需要对输出进行评估和调查。
这就是我们正在努力探索的几个有趣方向。随着 Jigsaw 的不断改进和完善,相信它的自动化能力将在提高程序员生产力方面发挥重要作用。我们也将尝试把 Python Pandas API 方面的经验推广到其他 API 和编程语言当中。
原文链接:
https://www.microsoft.com/en-us/research/blog/jigsaw-fixes-bugs-in-machine-written-software/
今日荐文
点击下方图片即可阅读

数字化转型失败了,谁该承担责任?IBM因IT项目开发失败,被判赔偿保险公司6.6亿元

你也「在看」吗?👇


