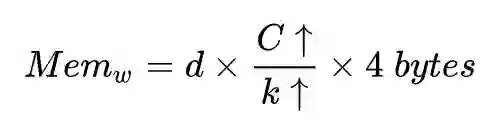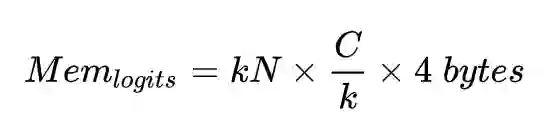这项研究基于现有公开人脸数据集创建了目前全球最大的人脸数据集,并实现了一个高效的分布式采样算法,兼顾模型准确率和训练效率,只用八块英伟达 RTX2080Ti 显卡就可以完成数千万人脸图像的分类任务。
人脸识别是计算机视觉社区长期以来的活跃课题。之前的研究者主要关注人脸特征提取网络所用的损失函数,尤其是基于softmax的损失函数大幅提升了人脸识别的性能。然而,飞速增加的人脸图像数量和GPU内存不足之间的矛盾逐渐变得不可调和。
最近,
格灵深瞳、北京邮电大学、湘潭大学和北京理工大学的研究者深入分析了基于softmax的损失函数的优化目标,以及训练大规模人脸数据的困难
。研究发现,softmax函数的负类在人脸表示学习中的重要性并不像我们之前认为的那样高。实验表明,在主流基准上,与使用全部类别训练的SOTA模型相比,使用10%随机采样类别训练softmax函数后模型准确率未出现损失。
该研究还实现了一个高效的分布式采样算法,兼顾模型准确率和训练效率,而且只用八块英伟达 RTX2080Ti 显卡就完成了数千万人脸图像的分类任务。为了验证该算法的效果和稳健性,研究人员清洗和合并了现有的公共人脸数据集,得到目前最大的公共人脸识别训练数据集Glint360K。
![]()
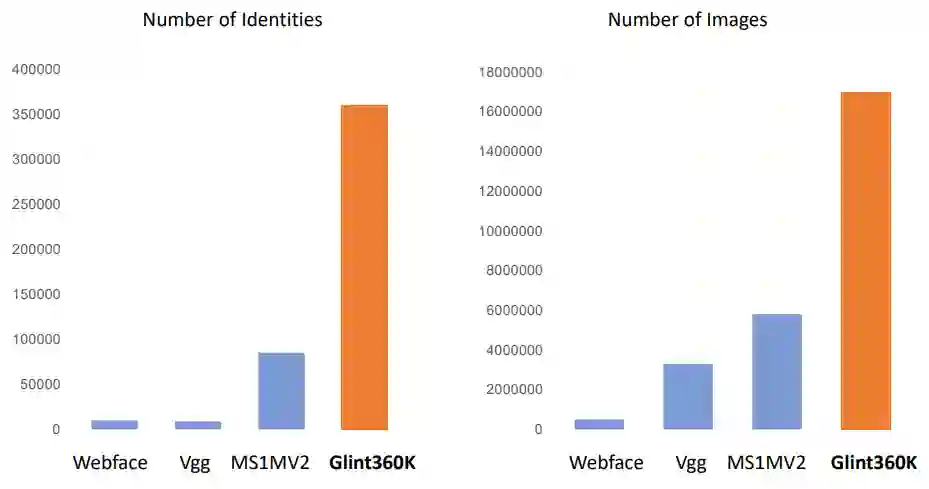
Glint360K数据集包含36万类别的1800万张图像,不论是类别数还是图像数,相比MS1MV2数据集都有大幅提升。
![]()
Glint360K数据集的类别数和图像数比主流训练集加起来还要多。
据研究者介绍,利用该数据集很容易在学术界的测评(比如IJB-C和megaface)上刷到SOTA。
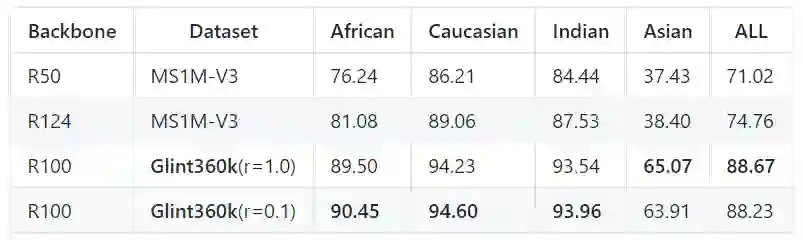
下表展示了IFRT上的结果(IFRT又称国产FRVT, IFRT测试集主要由不同肤色的素人构成,相比IJB-C和megaface更具有模型的区分度):
![]()
相比目前最好的训练集MS1M-V3,Glint360K有十个点的提升。
人脸识别任务的特点是数据多、类别大,几百万几千万类别的数据集在大公司也非常常见,例如2015年Google称他们有800万类别的人脸训练集。
训练如此规模的数据时,很直接的一种方法就是混合并行,即backbone使用数据并行,分类层使用模型并行,W (softmax线性变换矩阵) 分卡存储。该方法具备两个优点:1)缓解了 W 的存储压力。2)将 W 梯度的通信转换成了所有GPU的特征 X 与 softmax 局部分母的通信,大大降低了数据并行带来的通信开销。
这种方法看似可以训练无限的类别(增加GPU的个数就好了),但是实际上大家在尝试更大规模、更多机器的时候,会发现显存不够用了,好像增加类别数的同时增加机器,单个GPU的显存还在增长?其实我们忽略了另外一个占据显存的张量:logits。
首先定义 logits = X_w,其中 w 为存储在每张GPU上的子矩阵,X 为经过集合通信 Allgaher 收集到的全局特征,d 为特征的维度大小,C 为总的类别数,k 为GPU的个数。其中每块GPU中 w 占用的显存为:
![]()
通过这个公式我们发现,即使有更多的类别数,只要增加GPU的个数,就可以维持 w 占用的显存不变。我们再看 logits,假设每张卡上的批次大小为 N,则对于分类层的总批次大小为 kN ,每块GPU中 logits 占用的显存为:
![]()
研究者发现,即使类别数和GPU个数同时增长,logits 占用的显存与总的批次大小 kN 相关,随着GPU个数的增加,logits 占用的显存是持续增加的。假设100w类别需要用一台8卡RTX2080Ti,则1000w类别需要10台8卡RTX2080Ti,设特征维度为512,每张GPU的批次大小为64,则在训练1000w类别的任务时,每个GPU logits 占用的显存为 w 的十倍。在这个例子中,混合并行解决了 w 占用的显存,却增加了 logits 占用的显存。
在人脸识别中,CosineSoftmax的作用是拉近特征与其相应「正类中心」的距离,对其他的「负类中心」则保持距离。这点其实和最近很热的自监督表征学习非常类似,Moco通过队列保存更多的历史负样本,SimCLR则使用多机多卡、超大的batchsize来增加负样本的个数,而SimCLR在很大batchsize的时候提升有限。那么在人脸识别大规模分类任务中,每个特征的负类中心是所有的类中心,把这些负类中心减少一些是不是也能取得一样的效果?
答案是肯定的,具体实现方式还是要结合混合并行一起做。该研究采取的做法很简单:「
正类必采,负类随机
」,即在采样类中心的时候,保证正类中心必须采到,所以首先会把正类中心都拿出来,其次会随机采样一些负类中心,补齐到约定的采样率即可。
在混合并行的实现中,数据会随机地出现在不同的GPU上,而它的「正类中心」则会根据其类别按照顺序存放在一个固定的GPU上,这就会出现样本和「正类中心」不在同一张GPU上的问题。
该研究对此提出了一个简单的解决方案:在实现混合并行时,不仅同步每张卡的特征,同时也同步每张卡的标签,这样每张卡都具备所有卡的完整特征和标签。假设总的批次大小为 kN,则至多会有 kN 个正类中心随机分布在所有的GPU中,
让每个正类中心所属的GPU将该正类采样出来即可,每张GPU正类采出来后,再随机用负类补齐到约定的采样率
。这样每张GPU采样到的类中心一样多,实现负载均衡。后续的过程就是分类层的模型并行部分了,需要注意的是,只有采样出来的类中心的权重和动量会更新。
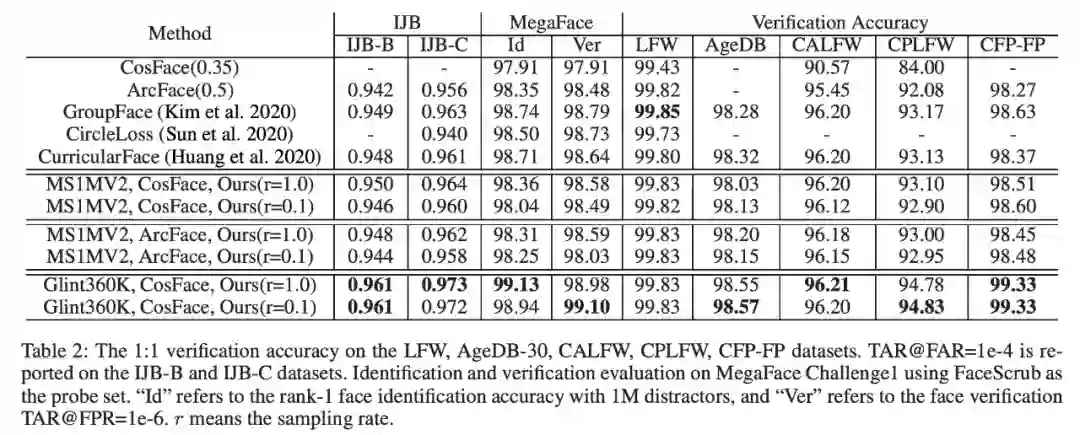
该研究在内部业务和FRVT竞赛上验证了这个方法,在学术界的测试集IJB-C和Megaface上,使用Glint360K的Full softmax和10%采样都有着相当不错的结果。
![]()
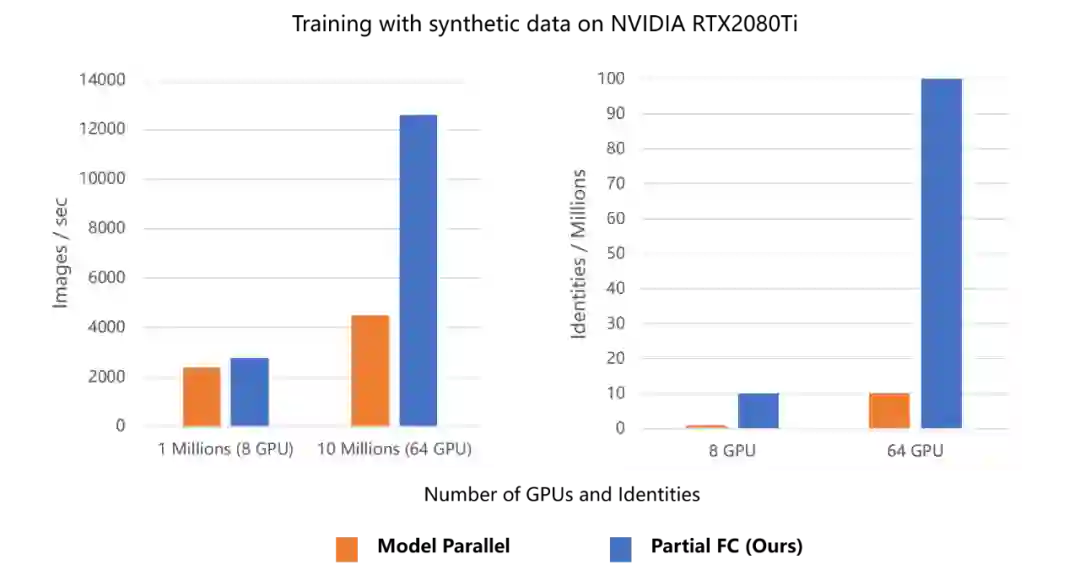
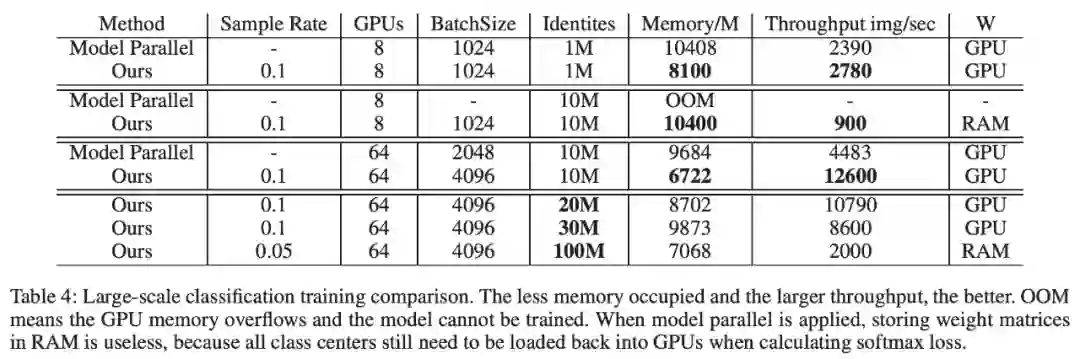
在64块2080Ti、类别数1000w的实验条件下,Partial FC 的速度是混合并行的3倍,占用的显存也更低,并且最大支持的类别数也有了一个数量级的飞跃,成功训练了一亿id的分类任务。
![]()
实战教程:DGL图神经网络详解。
10月22日20:00,AWS上海人工智能研究院的资深数据科学家张建将分享讲解图神经网络、DGL在图神经网络中的作用、图神经网络和DGL在欺诈检测中的应用和使用Amazon SageMaker部署和管理图神经网络模型的实时推断。
点击阅读原文或识别二维码,观看直播。
![]()
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com