论文浅尝 | XQA:一个跨语言开放域问答数据集

Citation: Liu, J., Lin, Y., Liu, Z., & Sun, M. (2019,July). XQA: A Cross-lingual Open-domain Question Answering Dataset. InProceedings of the 57th Conference of the Association for ComputationalLinguistics (pp. 2358-2368).
来源:ACL 2019
链接:https://www.aclweb.org/anthology/P19-1227
近年来,开放域问答(open-domain question answering, OpenQA)这一任务备受关注,一些模型和方法也取得了很好的结果,尤其是在使用了神经网络之后。但使用神经网络要求大量的标注数据,而这对于一些低资源量的语言是不现实的,因此现有的 OpenQA 模型无法直接用在这些语言上。解决这一问题的一种办法是构建一个跨语言的 OpenQA 系统,在高资源量的语言上(如英语)训练,在其他目标语言上为开放域问题预测答案。跨语言 QA 实际上可以被视作跨语言语言理解(cross-lingual language understanding, XLU)的一个特定任务,而 XLU 最近被用于跨语言文档分类、跨语言自然语言推理和机器翻译等任务。现有的跨语言模型大都集中在单词或句子层面上的理解,而问题和文档之间的关系以及对整个文档的理解却对 OpenQA 至关重要,然而现在并没有一个专门为跨语言 OpenQA 设计的数据集。因此,本文引入了这样的一个数据集:XQA。
构建了一个开源的跨语言 OpenQA 数据集:XQA,包含英语的训练集以及英语、法语、德语、葡萄牙语、波兰语、中文、俄语、乌克兰语和泰米尔语的验证集和测试集。测试集包含 56279 对英语问答对以及相关文档,验证集和测试集分
别包含 17358 和 16973 对问答对,所有问题都由来自以相应的语言为母语的人的自然语言并潜在反映了不同语言的文化差异;
使用公开的语料库构建了几个 baseline 系统,包括两个基于翻译的方法(分别翻译训练数据和测试数据)和一个零样本(zero-shot)跨语言方法(跨语言
BERT),在 XQA 上测试这几个 baseline 在不同语言上的文本获取和阅读理解能力。
现有的 OpenQA 模型通常先使用信息提取模块从大量的文本语料中抽取和问题有关的文档,再从这些文档中用阅读理解模块预测答案。形式化的描述为,给出问题 Q,OpenQA 系统首先使用信息抽取系统抽取和 Q 有关的 m 个文档(段落)P = 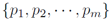
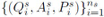
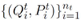
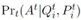
最直观的方法是基于翻译的,即将机器翻译系统和单语 OpenQA 结合起来。本文考虑了两种使用机器翻译系统的方式:第一种是 Translate-Train,即将来自源语言的训练数据集翻译成目标语言然后在目标语言上训练标准的 OpenQA;第二种是 Translate-Test,即在源语言上构建 OpenQA 系统,把来自目标语言的问题和获取的文档翻译成源语言。本文选取了两个现有最好的 OpenQA 模型,一个是 Document-QA,另一个是 BERT。
另外一种方式是零样本跨语言方法,即对于源语言和目标语言使用统一的一个模型,该模型用源语言的标注数据训练,直接使用在目标语言上。本文选用的 baseline 是Multilingual BERT。
本文提供了一个新颖的用于跨语言 OpenQA 的数据集——XQA。
数据的收集方法如下:维基百科每天会在不同语言的主页上提供一个“你知道吗”板块,如下图 1。该板块包含几个由维基百科编辑写的事实性的问题,并且链接到答案的百科页面。
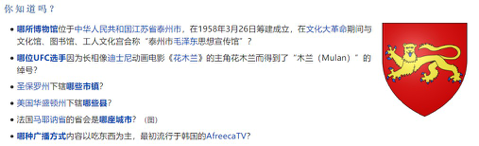
本文从这一板块中收集问题,把实体名和其来自 WikiData 知识库的别名作为标准答案。
对于每个问题,本文抽取了由 BM25 排出的最相关的 10 篇维基百科文章。不同语言的示例如表 1。

维基百科的文章中,实体名字几乎总是出现在文档的最开始,这会导致模型只预测最开始的几个字而忽略真正有用的信息。为了避免这一情况,本文的做法是删去每一篇文档的第一段。
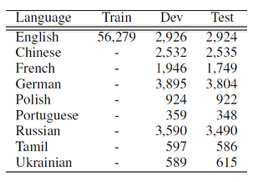
XQA 总共有来自 9 种语言的 90610 个问题,具体细节数据如表 2。
另外,本文还计算不同语言问题和文档的平均长度,如下表 3。大部分语言的平均问题长度都在10~20 之间,所有语言的平均问题长度为18.97。XQA 数据集中的文档都比较长,平均有 703.62 个符号和 11.02 个段落。泰米尔语和波兰语的文档最短。

表 3:不同语言下问题和文档的平均长度(中文为字符个数,其他语言为单词个数)及平均段落个数
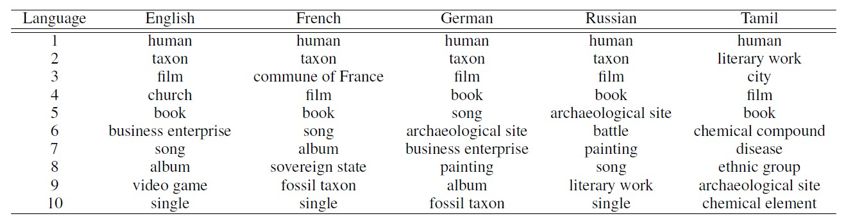
本文还通过匹配答案在 WikiData 中的类型,统计了不同语言的问题话题分布。最多的类型如下表 4。
本文在 XQA 上测试了几个 baseline 系统。
对于Translate-Test,本文使用清华大学自己的机器翻译系统 THUMT 来翻译德语、法语、葡萄牙语、俄语和中文这几种到英语,而波兰语、乌克兰语和泰米尔语用的是谷歌翻译。 而由于训练数据的翻译十分耗时,本实验对于Translate-Train 只使用了THUMT 翻译了德语和中文。两种翻译系统的BLEU 分数如下表 5。

表 5:两个机翻系统的BLEU 分数
为了处理多个段落对应一个问题的情况,本文采用了 shared-normalization。另外,通过合并最多 400 个符号的连续段落来重构文档。测试的时候,模型分别在最高的 5 个重构后的段落上分开来测试,分数最高的答案被选作预测。
对于DocumentQA 模型,本文使用的是官方的实现,在Translate-Test 中使用 GloVe 300- 维词向量,在 Translate-Train 中使用在中文/德语维基百科库上训练的 300-维 skip-gram 词向量。
对于 BERT 模型,和 SQuAD 中的做法类似,不过在训练过程中对于段落的取样使用了shared-normalization。使用了 BASE 配置,最大序列长度为 512。Translate-test 模型使用公开的“BERT-Base, Cased”预训练模型来初始化,而 Translate-train 以及多语言 BERT 模型使用“BERT-Base, Multilingual Cased”模型来初始化。
评估的标准为答案中符号的 EM 和 F1 值。在 Translate-test 配置中,本文将目标语言的标准答案翻译成英语并在此基础上汇报结果。
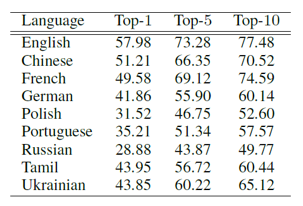
首先是文档抽取的表现。不同语言上抽取的结果如下表 6。
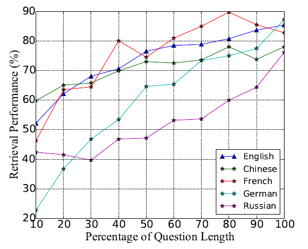
不同问题长度的抽取结果如下图 2。可以看出问题越长,抽取表现越好。
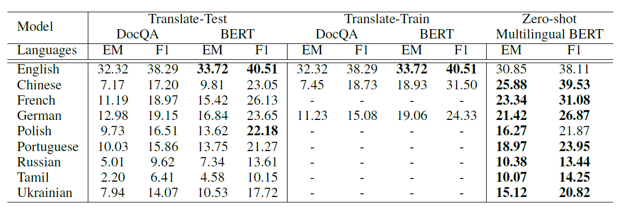
然后是总体结果。表 7 为上述几种不同方法在不同语言下的总体表现。英语和其他语言的结果差距很大,可见跨语言 OpenQA 还是很艰巨的一个任务。Zero-shot Multilingual
BERT 模型除了英语之外,在几乎其他所有语言上的表现都优于另外几个模型,可见其在跨语言获取答案上的能力。
比较 DocumentQA 和 BERT 模型的结果,可以看见 BERT 更占优势,本文推测是由于
BERT 模型在大量的未标注数据上预训练,通用能力更强,因此能更好地处理原始的英语训练数据和机器翻译后的测试数据之间的分布差异。
比较Translate-train 和Translate-Test,可以看出 Translate-Train 除了DocumentQA 中的德语这一项数据之外几乎完胜 Translate-Test,本文推测是由于 DocumentQA 使用空格符号化的词语作为基本单元,而德语的复合词之间没有空格,因此会得到无数种可能的组合,因此Translate-train 中的德语数据没有预训练的词向量。相比之下,BERT 使用的是 Word Piece
Tokenizer,因而不受影响。
最后,本文还对实验结果作了进一步讨论,分析指出基于机器翻译的方法提升的关键可能在于更好地处理命名实体的翻译,而 Multilingual BERT 模型通过更好地融合单语和平行语料能获得提升。
本文为跨语言 OpenQA 提供了新的数据集 XQA,并分别在几个 baseline 模型上测试了XQA,分析了现有模型的表现。
OpenKG
开放知识图谱(简称 OpenKG)旨在促进中文知识图谱数据的开放与互联,促进知识图谱和语义技术的普及和广泛应用。

点击阅读原文,进入 OpenKG 博客。



