观点 | 几个月就能化身为数据科学家?不存在的
选自 towardsdatascience
作者:Andrew Lukyanenko
机器之心编译
参与:高璇、王淑婷
成为一名数据科学家,Course 或 MOOC 上的广告说几个月就行。然而本文作者说,这是不存在。以下是作者根据自身经历写的经验(鸡汤)贴,内容详实丰富 ↓↓
关于做一名数据科学家,我有一些想法。成为一名数据科学家并不容易,需要付出很多努力,但如果你对数据科学充满兴趣,那一切都是值得的。
时常有人问我:如何成为一名数据科学家?必修的课程是什么?需要多长时间?你是怎么成为数据科学家的?我已多次回答过这些问题。所以在我看来,写一篇汇总的文章也许能帮助那些想要成为数据科学家的人。
关于我自己
我(俄罗斯,莫斯科)在密歇根州立大学经济学院获得硕士学位,并在 ERP 系统规划领域做了 4 年的分析师和顾问。我的工作涉及与客户交谈,讨论他们的需求并将其落地,编写文档,向程序员说明任务,测试结果,组织项目和许多其它事情。
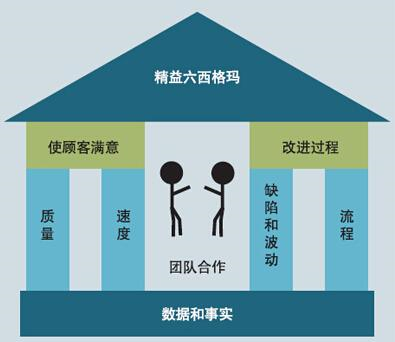
这是一项压力很大的工作,需要处理很多问题。更重要的是,我并不喜欢它。尽管我喜欢处理数据,但我做的大多数事情还是令人索然无味。所以,在 2016 年的春夏之交,我开始另谋出路。我通过了精益六西格玛(Lean Six Sigma)的绿带测试,但还未找到新的就业机会。有一天我发现了大数据(BigData)。在 google 上搜索和阅读了许多文章后,我意识到这可能是我的梦想职业。
我辞去工作,并在八个月后在一家银行找到了第一份数据科学家的工作。从那之后,我先后就职了几家公司,但我对数据科学的热情日益增加。我完成了一些关于机器学习和深度学习的课程,实践了一些项目(如聊天机器人或数字识别 APP),先后参加了许多机器学习的比赛和活动,在 Kaggle 上获得了三枚银牌。总之,我有一些学习数据科学和作为数据科学家工作的经验。当然,我还有很多技能需要学习。
免责声明
本文所述仅为我自己的观点。可能有些人会对其中的内容持反对态度,但我无意冒犯任何人。我认为想成为一名数据科学家必须投入大量的时间和精力,否则将一事无成。Course 或 MOOC 声称可以让你在几周或几个月内成为机器学习/深度学习/数据科学专家的广告语并不是真的。你可以在数周/数月内获得一些知识和技能。但如果没有广泛的实践(大多数课程内不包含这一部分),你无法真正掌握它。
你确实需要内在的动力,但更重要的是,你需要严格地规范自己,这样你可以在动力消失后继续努力。
再说一遍——你需要自己动手动脑。如果你在提出最基础的问题之前没有用 Google/ StackOverflow 或思考几分钟,那你将永远无法赶上专业人士。
在我参加的大多数课程中,只有大约 10-20%的人完成了这些课程。半途而废的人基本都缺乏耐心和决心。
什么样的人能成为数据科学家?

上图显示了数据科学家所需的一些核心技能,比如:数学和统计学,编程和开发,领域相关知识和软技能。
这么多技能!怎么可能完全掌握呢?嗯,需要花费很多时间。但告诉你一个好消息:没必要掌握全部。
2018 年 10 月 21 日,Yandex 上有一个有趣的演讲,其中提到数据科学专家类型有很多,他们只是拥有上述技能中的某几种而已。
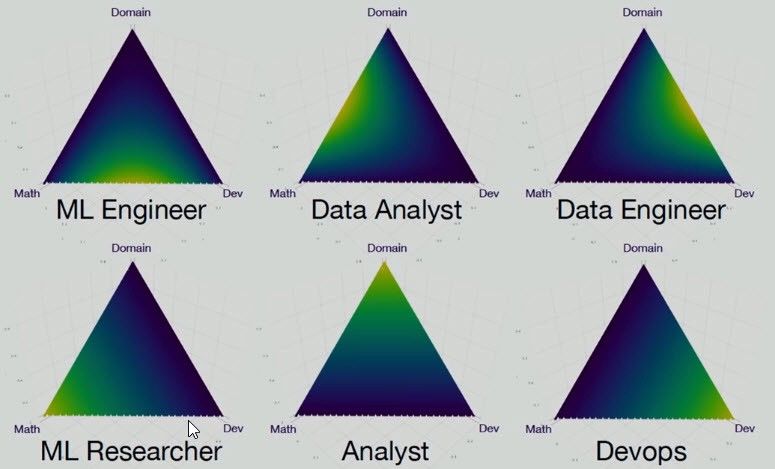
数据科学家应该处于图片中间的位置,但实际上他们可以处于三角形的任何位置,不同位置对应了不同的专家能力。
在本文中,我将讨论的一类数据科学家是那些可以与客户交谈,进行分析,构建模型并实施项目的人。
转行?这意味着你已有所了解!
有人说转行相当困难。虽然这是事实,但转行也通常意味着你对现在工作已经有所了解。也许你有编程和开发经验,也许你在数学/统计学领域工作过,或者你每天锻炼你的软技能。至少你拥有一些自己领域的专业知识。你可以扬长避短。
来自 Reddit 的数据科学路线图
实际上这里有两个路线图:)
第一个来自 Reddit:
首先,阅读 Hastie、Tibshirani 和 Jerome Friedman 所著的《The Elements of Statistical Learning》第 1-4 章和 7-8 章。就算暂时不理解,也要坚持阅读。
如果需要,你可以阅读该书的其它部分。假设你对全书都已有所了解。
观看 Andrew Ng 的 Coursera 课程。用 python 和 R 语言完成所有练习。确保你能写出正确答案。
然后阅读一本深度学习书。在 Linux 系统中运行 tensorflow 和 pytorch 框架并实践示例项目,直到完成。尝试使用卷积神经网络、循环神经网络和前馈神经网络。
完成所有这些后,继续在 arXiv 上阅读最新的有用论文。文献不断在更新,所以要跟上大部队。
完成这些的你现在会被大多数公司录取。如果你需要完善简历,可以参加一些 Kaggle 比赛。如果你有调试问题,请使用 StackOverflow。如果在数学方面有问题,请多读文献。如果生活上问题,自己看着办吧。(以上引用)
《The Elements of Statistical Learning》地址:https://web.stanford.edu/~hastie/ElemStatLearn//printings/ESLII_print10.pdf
其中一条评论:
这些还不够。还有一个新问题:没有训练数据,想想怎么收集。学会写 scraper,然后做一些标注和特征提取。在 EC2 上完成所有安装并实现自动化。尝试编写代码,以便有新数据时,在生产中不断重新训练和部署模型。
虽然这些听起来很简短,但很严苛且非常困难,如果做到了,它可以让你有个饭碗。
当然,还有许多其它的数据科学方法,我提供的只是我自己的方法。它并不完美,但却是基于我的个人经验。
我的路线图:
有一项技能可以让你走得很远。如果你还没拥有这项技能,希望你尽快掌握。这项技能是——独立构思,检索信息,发现信息,理解信息。有些人无法独立构思,有些人无法找到最基本问题的解决方案,有些人甚至不知道如何正确使用谷歌搜索。这是一项必备的基础技能,你必须掌握它!
选择一门编程语言进行学习。Python 或 R 语言就不错。我强烈建议选择 Python。理由我就不多说了,关于 R / Python 的争论已经多得数不胜数,不过我个人认为 Python 更通用,更实用。花上 2-4 周学习语言,这样你就能做基本的事情了。大致了解要使用的库,例如 pandas / matplotlib 或 tydiverse / ggplot2。
过一遍 Andrew NG 的 ML 课程。这门课比较老,但它可以帮你夯实基础。用 Python/R 完成其中的任务可能很有用,但没有必要。
再选择一门(或几门)进阶的 ML 课程进行学习。对于 R 用户,我推荐 Analytics Edge,对于 Python 用户,我推荐 mlcourse.ai。如果你懂俄语,那么 Coursera 上的这门课(https://www.coursera.org/specializations/machine-learning-data-analysis)也很棒。在我看来,mlcourse.ai 是三者中最好的。为什么?它提供了良好的理论和一些有挑战的任务,这已经足够了。同时它还教人们参加 Kaggle 比赛并制作独立项目。这对实践很有帮助。
学习 SQL。大多数公司的数据都保存在关系数据库中,因此你要能够获取它。可以使用 select 语句、group by 语句、join 语句、CTE 表达式等。
尝试使用原始数据,获得处理杂乱数据集的经验。
上一条是选做,但这一条是必须完成的:完成至少 1 或 2 个完整项目。例如,对某些数据集进行详细的分析和建模,或创建一个应用程序。最重要的是学习如何构思一个想法、规划实施、获取数据、实施并完成项目。
参加 Kaggle 比赛。
加入一个好的社区。我加入了 ods.ai——由一万五以上活跃的俄罗斯数据科学家组成的社区(不过这个社区对任何国家的数据科学家都开放),这对我帮助很大。
学习深度学习是另一个全新的话题。

这仅仅是个开始。遵循这个路线图(或做相似的事)将帮助你开启数据科学家之路。剩下的路要靠你自己走!

原文链接:https://towardsdatascience.com/a-long-term-data-science-roadmap-which-wont-help-you-become-an-expert-in-only-several-months-4436733e63ff
本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com