用自然语言来搜索图片中的人
论文:《Person Search with Natural Language Description》
作者:
Shuang Li, Tong Xiao, Hongsheng Li, Bolei Zhou, Dayu Yue, Xiaogang Wang, The Chinese University of Hong Kong
点击文章末尾“原文链接”可阅读原论文

摘要
用自然语言描述查询大型图像数据库中的人员在视频监控中具有重要的应用。现有的方法主要集中在基于图像的方法或基于属性的方法,这对于实际使用具有重要的局限性。在本文中,我们用自然语言描述研究人物搜索的问题。给定个人的文本描述,需要人物搜索算法对个人数据库中的所有样本进行排名,然后检索与查询描述相对应的最相关样本。由于没有可用的文本描述人物数据集,我们收集了一个大型人物描述数据集,其中包含了各种来源的详细自然语言注释和人物样本,称为CUHK-PEDES。我们还提出了门结构控神经注意机制(GNA-RNN)的RNN达到了人物搜索方面时下最优性能。
引入和相关工作
传统的人员搜索有两种方法:基于图片的方法和基于属性的方法。
基于图片的人员搜索方法在计算机视觉当中也叫做“人物重新识别任务“。给出查询图像,算法获得查询与图像数据库中的查询之间的亲和度。可以根据亲和度值从数据库检索最相似的人员。然而,这样的问题设置在实践中有很大的局限性,因为它需要至少一张被查询者的照片。在许多刑事案件中,可能只有口头上描述嫌犯的外表。
人员搜索也可以通过基于属性的查询来完成。一组预定义的语义属性用于描述人的外观。然后对每个属性对分类器进行训练。给定一个查询,数据库中的类似的人可以被检索为具有相似属性的人。然而,这些属性也具有许多实际的限制。一方面,属性描述人的外表的能力有限。例如,PETA数据集定义了61个二分类和4个多类人物属性,然而描述一个人的外观可以有数百个单词。另一方面,即使有一套可以穷尽的属性系统,将它们标记为大型人物图像数据集也是一个极为昂贵的过程。
针对两种模式的局限性,我们建议使用自然语言描述来搜索人。它不需要像这些基于图像的查询方法那样预先给出照片。自然语言也可以精确地描述人物的细节。由于没有现有的数据集专注于用自然语言描述人物,我们首先从现有人员重新识别数据集中构建了一个大型语言数据集,共有40,206个图像,13,003个人。每个人的形象用两个独立的工作人员Amazon Mechanical Turk(AMT)来描述。在视觉方面,来自各种重新识别数据集的人物图像在不同的场景,观点和摄像机规格下,增加了图像内容的多样性。在语言方面,数据集有80,412个句子描述,包含丰富的词汇,短语和句子模式和结构。数据集的描述如下图。

本文的贡献有三点:1)我们提出研究用自然语言搜索人员的问题。这个问题设置对于现实世界的场景更为实用。为了支持这一研究方向,收集了具有丰富语言注释的大规模人物描述数据集,并给出了用户对自然语言描述的研究。 2)我们根据不同的视觉和语言框架,包括图像字幕,视觉质量检查和视觉语义嵌入,研究广泛的合理解决方案,并建立人员搜索基准的基线。 3)我们进一步提出了一种具有门控神经注意力的新型循环神经网络(GNA-RNN),用于人员搜索,以及对人员搜索基准的最先进的表现。
用GAN-RNN进行人员搜索
作者做了一个用户研究。首先,作者发现在语言和属性两种类型的图片描述中,语言描述更容忍为人所接收,并且搜索结果更准确。所以这说明,用自然语言来搜索人员比较好。其次,作者发现描述时句子越长,单词越多,越容易为人所接收。这说明我们在描述图片时,用长一点的句子描述比较好。最后,作者发现,对于单词词性,名词包含的信息量最大,对我们搜索最优帮助,其次是形容词,最后是动词。这说明我们在使用描述性语言来搜索人员时,应该给名词更多权重,动词较少的权重。
以上这些对人们进行的研究,对我们构造模型有很大的帮助。基于上面的研究结论,作者提出了自己的网络结构,如下。
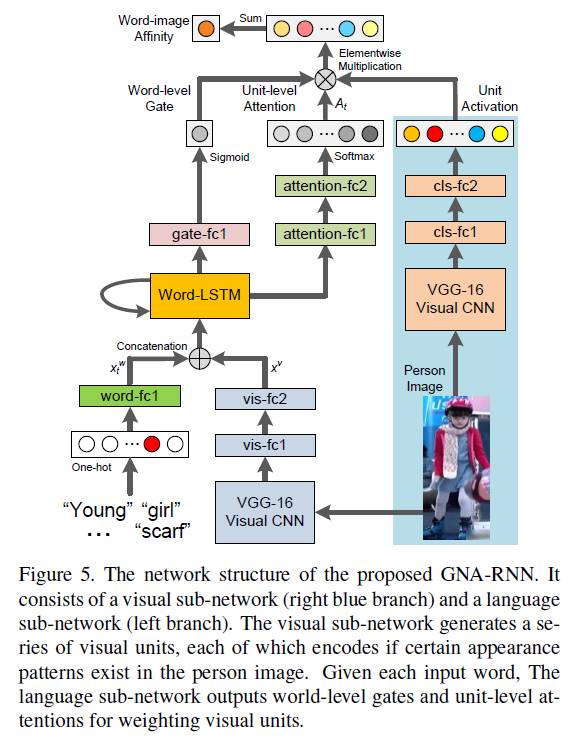
整个网络分为两个分支,左边是自然语言处理子网络,右边蓝色的分支是视觉图像处理子网络。
右边视觉图像处理子网络比较简单,注意最后将VGG-16的“drop7”后又加了两个全连接层,cls-fc1,cls-fc2,最后产生一个包含512个视觉单元的视觉向量。
左边的自然语言处理子网络中,最后产生两个输出:unit-level attention和word-level gate。
首先我们介绍unit-level attention。对于输入的第t个单词,会生成一个unit-level attention向量A_t,它用来控制每个单词对图片内容的注意力。对于不同的输入单词,网络对图片各部分内容的注意力不同,均满足如下特点。
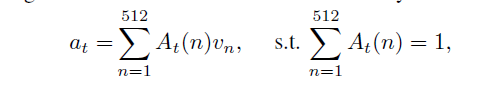
A_t(n)表示A_t的第n维(A_t也是512维),v_n表示视觉特征的第n维。不同单词,对图片有不同的注意力。如果单词产生的注意力A,和图片本身的视觉特征v很相近,那么他们的乘积就很大,这样的话,说明它们的亲和度a越大,即这个单词描述的内容和图片描述的内容很相近。而包含t个单词的一句话最终和一张图片的总的亲和度,就是它各个单词和图片的亲和度之和,如下。
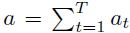
其次,我们还要介绍word-level gate。看样子上面的a已经能表示最终的亲和度了,但是别忘了,我们进行的“用户研究”的实验表明,不同单词的重要程度是不一样的,所以这么直接相加并不是最好的,因为这其实默认各个单词的权重都为1。所以,我们还要针对每个单词,生成一个控制门,作为这个单词的权重。那么第t个单词调整后的亲和度,即可以用以下公式表示。
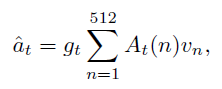
而调整以后的总亲和度,即可表示为以下。
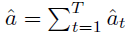
实验