知识增强的文本生成研究进展
©作者|李军毅
机构|中国人民大学高瓴人工智能学院
研究方向 | 自然语言生成与知识融合

本文梳理近些年在知识增强的文本生成领域的一系列研究进展,其主要内容参考以下这篇论文。我们的文章也同步发布在AI Box知乎专栏(知乎搜索 AI Box专栏),也欢迎大家在知乎专栏的文章下方评论留言,交流探讨!

A Survey of Knowledge-Enhanced Text Generation ( https://arxiv.o rg/abs/2010.04389)
一、研究背景
文本生成是目前自然语言处理(NLP)领域一个非常重要且有挑战的任务。文本生成任务通常是以文本作为输入(例如序列,关键词),通过将输入文本数据处理成语义表示,生成可以理解的自然语言文本。几个具有代表性的文本生成任务,例如机器翻译,文件摘要,对话系统。自从2014年Seq2Seq框架提出以来,文本生成迅速成为研究热点,包括一系列经典而有效的模型,例如循环神经网络(RNN),卷积神经网络(CNN),Transformer。基于这些模型,注意力机制(attention)和拷贝机制(copy/pointer-generator)的提出也极大促进了文本生成的研究。但是,研究人员发现,传统的文本生成任务只依靠输入文本进行生成,缺乏更加丰富的“知识”信息,因此生成的文本往往非常乏味,缺少有意思的内容。例如在对话系统中,如果只提供一段输入文本而没有其他上下文,对话机器人往往会回答“我也是一样”,“我听不懂你在说什么”等。相比之下,人类通过从外界获取、学习和储存知识,可以迅速理解对话里的内容从而做出合适的回复。所以,“知识”对于文本生成任务而言,可以超越输入文本中的语义限制,帮助文本生成系统生成更加丰富、有意思的文本。在文本生成任务中,“知识”是对输入文本和上下文的一种“补充”,可以由不同方法和信息源获得,包括但不限于关键词,主题,语言学特征,知识库,知识图谱等,可以参考下图1中的 Information Sources。这些“知识”可以通过不同的表示方法学习到有效的知识表示,用于增强文本生成任务的生成效果,这就被称为知识增强的文本生成(Knowledge-Enhanced Text Generation)。因此,知识增强的文本生成主要有两个难点:如何获取有用的知识(图1 Information Sources),以及如何理解并借助知识促进文本生成(图1 Methods)。接下来的内容将主要围绕着这两个问题进行展开。
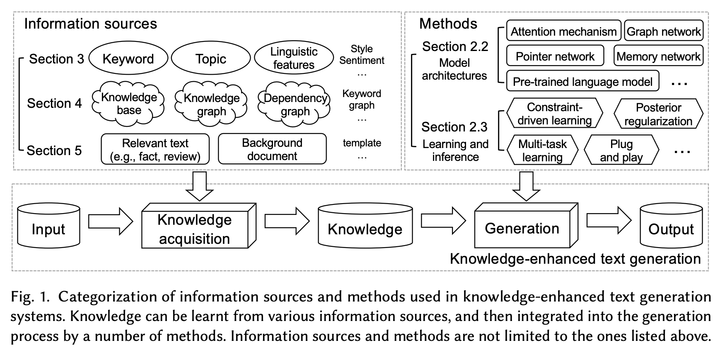
图 1
二、知识融合的文本生成
这一部分主要介绍几种通用的将知识融入文本生成的方法。下图2是常用的数学符号标记。

图 2
2.1 基础文本生成模型
传统的文本生成模型主要是基于encoder-decoder框架,encoder学习将输入文本编码为向量表示,decoder则负责将此向量表示解码为文本序列。从概率角度来说,encoder-decoder框架就是学习一个条件概率分布,给定输入文本文本,即下式:
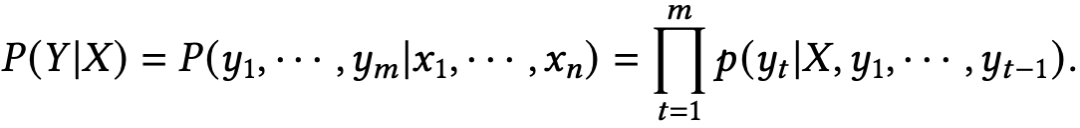
经典模型包括2014年提出的RNN-Seq2Seq模型(其中 ):
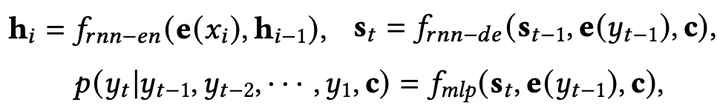
以及2017年提出的Transformer模型(其中 ):
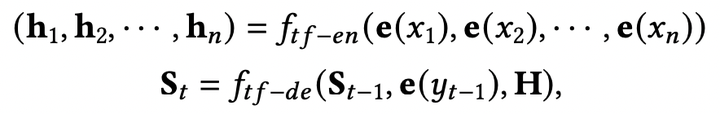
文本生成过程可以看做是一个序列化的多标签分类问题,它可以通过负对数似然(NLL)损失进行优化。因此,文本生成模型的目标函数是一个最大化似然估计(MLE):
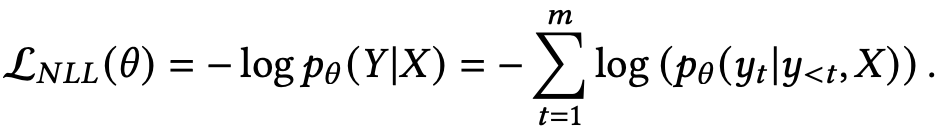
2.2 知识融合方法
下面介绍几种广泛用于将知识融入生成模型的方法,包括注意力机制,拷贝机制,记忆网络,图网络和预训练模型。
注意力机制 (Attention Mechanism) 在论文[1]中,注意力机制主要是在decoder中加入上下文向量 ,用于刻画输入文本对于生成过程的重要程度:
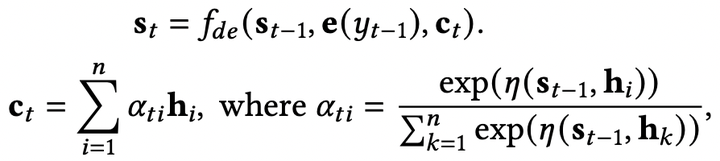
如何借助注意力机制将知识融入文本生成模型?模型学习一个针对“知识”的上下文向量
,反映了“知识”对于生成文本的重要性,最后将
和
结合 (例如,
)加入到decoder中。下图3罗列了对于不同的知识类型,注意力机制的计算方式。

图 3
拷贝机制 (Copy and Pointer-Generator Mechanism) 拷贝机制主要是用于从输入文本序列中选择合适的子序列放到输出序列中。论文[2]提出了CopyNet框架。在CopyNet框架中,生成概率由两种模式的概率组合而成:生成模式和拷贝模式 ( ):
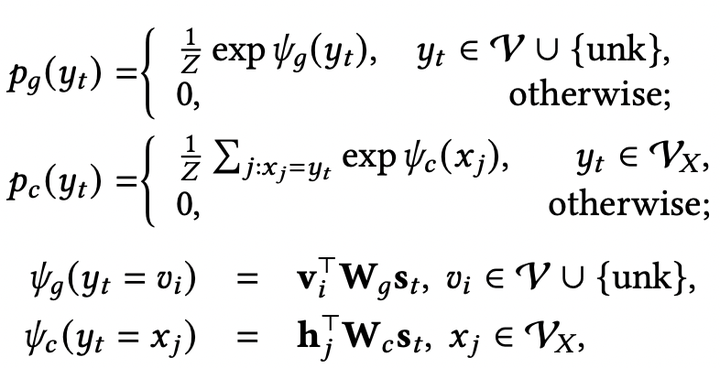
其中 是全局词典, 是输入序列的词典, 是unknown token。论文[3]提出了Pointer-Generator,与CopyNet不同,Pointer-Generator显式地计算生成模式和拷贝模式之间的转换概率 ,并且将注意力分布作为拷贝概率使用:
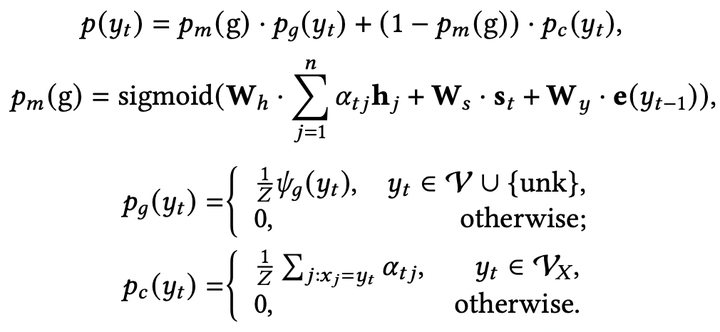
如何借助拷贝机制将知识融入文本生成模型?针对知识设计了知识模式和知识相关的词典
,最后生成概率由三种模式的概率组合而成:生成模型,拷贝模式和知识模式,其中知识模式的概率是在
上进行计算。以知识库为例,知识模式会从知识库中拷贝相应的实体和关系到生成文本中。下图4展示了针对不同知识所设计的知识模式计算方式。
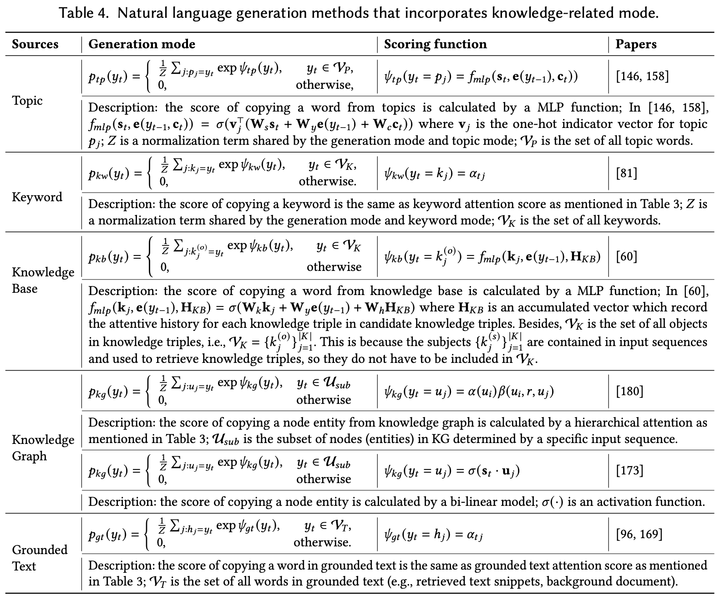
图 4
记忆网络 (Memory Network) 论文[4]提出了记忆网络,通俗来说,记忆网络类似于作用在外部存储上的循环注意力模型,通过循环地利用输入序列“读取”存储上的记忆表示,然后将更新的记忆表示写回存储上。给定输入集合 ,Memory Network会将其存储为记忆表示 ,其中 是一个矩阵,每一列是每个输入 的向量表示。在第 轮中,输入序列向量 作为读取“query”,计算当前轮的记忆表示 :
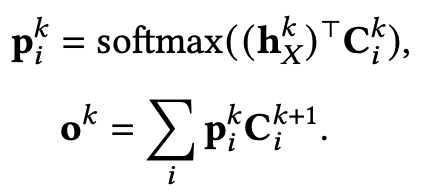
之后,下一轮的读取“query”在此基础上更新 ,继续重复上述步骤 次,得到最终的记忆表示 ,加入到decoder生成过程中。如何借助记忆网络将知识融入文本生成模型?将外部知识存储为记忆,然后按照上述过程。
图网络 (Graph Network) 图网络主要依靠message passing机制捕捉图上各节点之间的依赖关系。通过图神经网络,一系列图结构的“知识”(例如,知识图谱,关键词图谱,依赖图等)都可以融入文本生成模型。形式化地,图可以表示为 ,其中 表示节点集合, 表示边集合。在图神经网络中,每个节点通过aggregation操作计算节点表示:
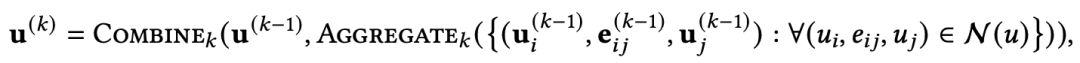
其中 表示节点 相关的边。关于AGGREGATION方法的选择可以阅读图神经网络的论文。
预训练模型 (Pretrained Models) 目前文本生成任务的数据集规模都比较小,而模型的参数规模相对比较大,因此容易出现模型泛化能力不足的问题。因此,许多研究者希望利用大规模的无标注数据集预训练模型,这些模型可以为文本生成任务模型提供更好的模型初始化。第一代预训练模型学习的是静态/无上下文的词向量 (non-contextual embedding),例如Word2Vec,GloVe等。第二代预训练模型则关注动态/有上下文的词向量 (contextual embedding),例如GPT,BERT等。静态的词向量最大的缺点是无法刻画单词的上下文信息,因此无法处理多义词的情况,而动态的词向量则是词向量会根据上下文的不同而发现变化。通过大规模的预训练语料,预训练模型本身可以学习到语言相关的知识,例如指代关系,单词搭配等,这些可以帮助文本生成任务生成更加流畅自然的文本,而且预训练模型也可以从知识库中的三元组信息学习到一些常识知识,例如ERNIE,这些加入知识的预训练模型可以用作下游的文本生成模型。
三、基于主题、关键词和语言学特征增强的文本生成
3.1 主题增强的文本生成
主题(Topic)可以看做是文本语义的高度压缩,可以用来保证文本的语义连贯性(semantic coherence),从而帮助文本生成。例如,文本摘要里通常要求生成文本准确把握输入文档的关键主题,对话系统里要求回复的文本与对话主题相关,避免生成无意义回复。近年来,许多研究将神经网络和主题建模技术(例如,LDA)进行结合,从文本中挖掘潜在主题。下图5展示了近年比较有代表性的基于主题增强的文本生成模型。
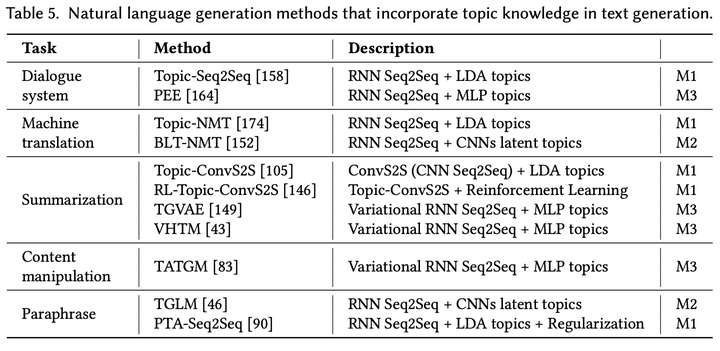
图 5
这些模型可以总结为三种方法:
M1:借助生成式主题模型 (generative topic models) 中的主题词 (topic words):它首先利用生成式主题模型(例如,LDA)挖掘主题,然后通过主题注意力机制将主题表示融入文本生成模型。主题表示提供了关于生成文本的高度语义表示,保证文本连贯性。
M2:同时优化生成模型和卷积主题模型 (CNN topic model):神经网络会同时学习如何表示主题和如何生成文本。卷积神经网络(CNN)可以通过迭代卷积(iterative convolution)和池化(pooling)操作学习潜在的主题。
M3:使用变分推断 (variational inference),利用神经主题模型增强文本生成:相对卷积主题模型,神经主题模型参数较多,因此更容易发生过拟合。变分推断往往假设主题分布符合隐式空间里的某个先验分布(例如,高斯分布),从而缓解上述问题。
下面详细介绍这三种方法。
借助生成式主题模型中的主题词 对于从生成式主题模型中获取的主题,目前有两种主流表示方法。第一种方法是对于输入序列中的每个单词使用主题分布,即所有主题的单词分布,例如,Topic-NMT将主题分布与encoder和decoder中的隐状态进行拼接,Topic-ConvS2S将主题分布和词向量拼接作为encoder输入,增强decoder对主题信息的感知。第二种方法是对于输入序列选择某个主题,然后选择当前主题top-k的单词,使用词向量(例如,GloVe)来表示这些主题词,例如,Topic-Seq2Seq使用从预训练LDA模型中获取的主题词作为先验知识,PTA-Seq2Seq增加两个惩罚项用于主题的重要性判断和主题词的选择。相比于第一种方法使用主题分布,第二种方法显式地引入主题词可以给生成过程带来很强的指导信号,但是如果主题选择不当会对生成产生极大的误导。
同时优化生成模型和卷积主题模型 LDA模型通常是无监督的,它一般假设主题的单词分布符合狄利克雷分布。因此,无监督的LDA模型无法针对特定的文本生成任务寻找合适的主题,并且它的训练过程和文本生成模型是分离的,导致其无法刻画输入和输出文本之间多样化的依赖关系。考虑到卷积神经网络同样可以学习潜在的主题,许多工作(例如,BLT-NMT)开始研究利用卷积神经网络学习主题表示,以增强文本生成任务。实验证明,基于卷积的主题抽取往往要优于基于LDA的主题模型,但在可解释性方面不足。
使用变分推断,利用神经主题模型增强文本生成 神经主题模型结合了神经网络和概率主题模型两者的优势,可以通过反向传播进行训练,并且很容易适应不同的上下文信息。在主题模型中,文档中的主题满足多元正态分布,主题中的单词同样也满足多元正态分布。为了促进主题模型中的推断,狄利克雷分布可以作为先验分布生成文档的多元正态分布中的参数 。因此,LDA中的生成过程可以表示为:(1) ;(2) ;(3) ,其中 表示文档bag-of-words表示, 表示单词 的主题, 表示在给定主题 下单词的分布。文档 的边缘似然函数为:
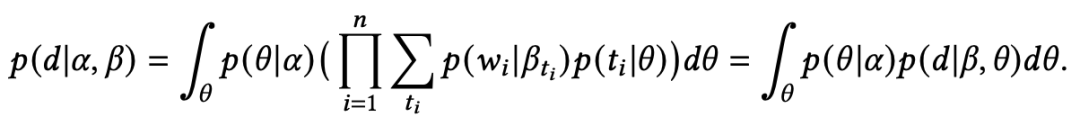
但是,a directed generative model comes up against the problem of establishing low variance gradient estimators.(论文原话,不是很明白,请大佬在评论区解惑)Miao等人使用神经网络对多元正态分布进行参数化,通过变分推断学习模型参数。他们通过一个高斯分布构造出主题分布,即 ,其中 由各向同性高斯 经过神经网络得到。因此,文档 的边缘似然函数为:
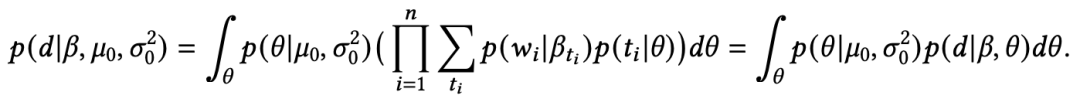
与 相比,隐变量 通过作用在高斯分布上的神经网络进行参数化。为了进行变分推断,Miao等人构造了一个推断网络 来近似后验分布 。在没有共轭先验的情况下,参数的更新可以直接由变分下界(variational lower bound)进行推导。形式化地,对于文档对数似然的变分下界为:
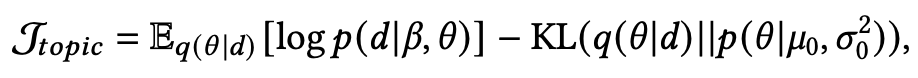
其中 是一个变分分布,目的是近似真实的后验分布 ,它的下界可以通过从分布 采样 得到。为了将上述神经主题模型和神经生成模型进行结合,可以使用变分自编码器(VAE)。Wang等人提出了基于主题的变分自编码器(TGVAE),从一个主题依赖的高斯混合先验中采样出隐变量 z ,将主题信息融入隐变量中。这个主题依赖的高斯混合模型为:
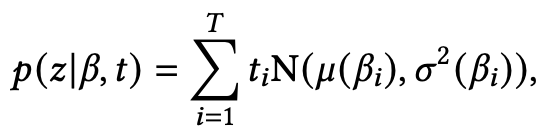
其中 T 是主题个数, 和 是多层感知器。具体来说,TGVAE将输入文档的bag-of-words映射为主题向量,然后使用主题向量重构得到bag-of-words,并且TGVAE会学习每个主题上的单词分布,这个分布会作为一个主题依赖的先验分布生成最后的文本 。因此,关于文档 和输出 的联合边缘似然函数为:
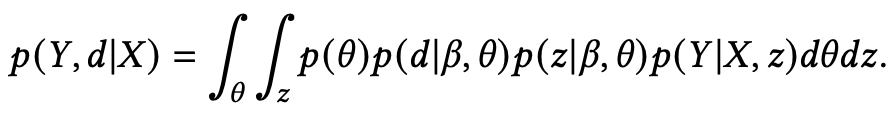
为了最大化对数似然 ,构造了一个变分目标函数:
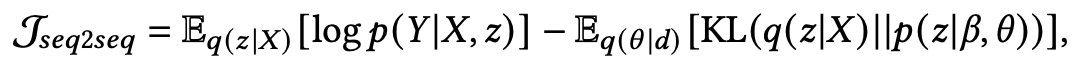
其中 是关于 的变分分布。最终的目标函数为:
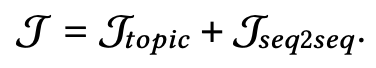
主题增强的优点和缺点 主题模型往往将文档和单词的语义表示整合到一个网络中,因此有着严格的概率解释。除此以外,主题模型可以很容易地融入到生成框架中。例如,主题词可以表示为词向量,主题向量也可以通过注意力机制融入生成过程中。但是,LDA模型和神经模型的训练过程是分离的,因此无法适应输入和输出之间多样化的依赖关系。神经主题模型将神经网络和概率主题模型两者的优势结合在一起,可以通过反向传播同时进行训练。但是,他们通常假设主题分布是一个各向同性高斯,所以无法对主题之间的关联进行建模。而且目前的神经主题模型在使用VAE时会假设文档满足独立同分布,但事实上文档是由单词组成的,单词之间有很大关联而不是相互独立。
3.2 关键词增强的文本生成
关键词(Keyword)通常是指一个或多个词,是关于文本重要内容的提炼。主流的关键词获取方法主要有两种:关键词分配(keyword assignment)和关键词抽取(keyword extraction)。关键词分配是指从一个可控的词表或预定义的分类系统中选择关键;关键词抽取则是从文档中抽取出最具有代表性的单词。关键词抽取技术(例如,TF-IDF,TextRank,PMI)近年来被广泛应用,文本生成任务也可以吸收关键词信息,保持文本的语义连贯性。其中,对话系统和文本摘要应用关键词知识较多的两个任务,下图6展示了对话系统和文本摘要基于关键词增强的文本生成模型。
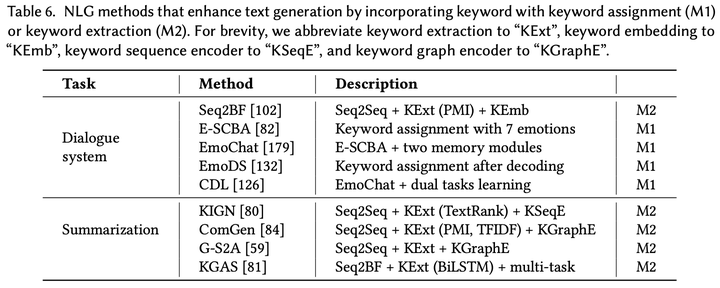
图 6
这些模型可以总结为两种方法:
M1:借助关键词分配的文本生成:在关键词分配中,关键词是从一个预定义的词表中选择得到。为了获取关键词,可以基于输入文档学习一个关键词分类器,预测合适的关键,然后使用关键词指导生成。
M2:借助关键词抽取的文本生成:关键词抽取是从文档中选择最重要的单词,可以采用的技术包括统计方法(例如,TF-IDF,TextRank)和有监督学习方法(例如,BiLSTM)。抽取的关键词可以用来增强生成过程。
下面详细介绍这两种方法。
借助关键词分配的文本生成 在关键词分配中,关键词被限定在一个预定义的词表中,优点是可以保证关键词的质量,即使对于两个没有重合单词但语义高度相似的文档也可以分配到相同关键词(因为关键词分类器会学习将输入文档映射为一个关键词),但这个方法受限于某些无法清晰定义合适关键词词表的应用场景。
在实际应用中,可能会出现输入序列中没有包含预定义词表中的关键词。例如,句子“If you had stopped him that day, things would have been different.”表达的是伤心但它不包含关键词“sad”。针对这种情况,E-SCBA提出一种方法预测句子的情感类别,这个情感会指导对话回复的生成。具体地,预测的情感类别 可以表示为向量 ,这个向量与原先的上下文向量 结合为新的上下文向量 。为了动态地追踪情感在句子中的表达,EmoChat使用一个记忆模块刻画生成过程中的情感变化。但是,上述方法显式地引入情感关键词会导致句子对某个情感的过度表达。所以,EmoDS使用一个情感分类器作为句子级别的情感判别器,用于识别句子是否隐式地表达了某个情感,而不是希望句子显式地包含情感词。
借助关键词抽取的文本生成 将抽取的关键词融入生成过程和前一种方法类似,将抽取的关键词作为decoder的额外输入。这些关键词可以表示为 ,然后decoder的隐状态可以通过如下更新: ,其中 是利用注意力机制对 计算得到的关键词上下文向量。KIGN提出使用Bi-LSTM编码关键词,然后将前向的最后一个隐状态和后向的第一个隐状态拼接作为关键词上下文向量: 。
关键词增强的优点和缺点 前面也提到,关键词分配方法有两个主要优点:一是可以保证关键词质量;二是对于两个语义高度近似的文本可以分配相同的关键词(即使文本没有共同单词)。但是,这类方法也有两个主要缺点:一是对于新领域而言,维护关键词词表是代价很大的;二是如果文本中潜在的关键词如果不在词典则会被忽略。因此,基于关键词分配的模型主要应用在需要特殊关键词引导的特殊任务上,例如,生成某个情感下的对话回复。关键词抽取方法的一大优势是不受环境制约,可以很容易适用于其他任务。但其有两个缺陷,一方面是无法保证一致性,对于两个相似的文档如果没有共同的单词,则会被表示为不同的关键词;另一方面则是当文本中没有合适的关键词时,模型会抽取出不相关的关键词,从而误导文本生成。因此,基于关键词抽取的模型主要适合输出序列需要包含输入文本的重要信息任务上,例如,文档摘要,文本复述。
3.3 语言学特征增强的文本生成
除了输入文本,encoder还可以引入额外的手动设计的特征,语言学特征一种比较常见的特征,例如 lemmas,part-of-speech (POS) tags,dependency parsing,semantic parsing。在这一部分,我们将主要介绍 lemmatisation特征,POS tags,NER tags 和 leave dependency parsing,semantic parsing。
Lemmatisation特征 在morphology和lexicography中,a lemma(词根) is the canonical form and dictionary form of a set of words that have the same meaning。例如,“run”,“runs”,“ran”和“ranning”具有相同的词素(lexeme),而“run”则是词根。对于那些词法学丰富的语言(例如,德语,捷克语),文本生成任务很难建模单词序列,例如,机器翻译。因此,lemmatisation就被用来消除data sparseness,允许inflectional variants of the same word。Semmrich等人发现如果单词之间具有相同的词素,那么这些单词的表示之间在某些维度应该是共享的。Conforti等人直接将词向量和词根向量拼接作为每个单词的向量表示。
POS tags和NER tags Part-of-speech会预测每个单词的语法类别,例如,名词 (N),动词 (V),形容词 (A)。命名实体识别(NER)会识别句子中每个实体的类别,例如,人 (P),位置 (P),组织 (O)。POS tag和NER tag可以帮助检测输入文本中的命名实体,更好地理解文本,从而促进生成。
四、基于知识库、知识图谱和依赖图增强的文本生成
4.1 知识库增强的文本生成
在文本生成任务中,如何刻画文本中语义单元之间、输入和输出之间的依赖关系是重要的,这种依赖关系可以理解为一种“知识”,例如常识,事实事件,语义关系等。知识库(knowledge base, KB)就是一个收集、存储和管理大规模知识信息的技术。知识库包含大量的三元组(triple),三元组由subjects,predicates和objects组成,可以被称为事实(facts)或事实三元组(factual triples)。目前已有非常多的工作使用知识库作为额外的知识信息去学习文本中语义单元之间的依赖关系,常用的知识库包括DBpedia,Freebase和Wikidata。
一个非常典型的利用知识库的文本生成任务是问答系统。单纯依靠问题本身很难得出满意的回答,一个好的回答往往需要问题之外的信息,甚至需要基于已有常识或事实做出恰当的推理才能推导出问题的答案,而这些常识和事实可以从知识库中检索得到。另一方面,回答问题并不是简单地提供一个知识库中的subject或object,它需要以可理解的自然语言给出。下面给出一个例子:
另一个典型的任务是对话系统。与问答系统不一样,对话内容往往是开放性的主题,“Do you have any recommendations?”,并且需要考虑对话历史上下文才能引入合适的实体进行回复,知识库可以帮助建模对话历史中长距离的上下文。下图7展示了近年来知识库增强的文本生成模型。
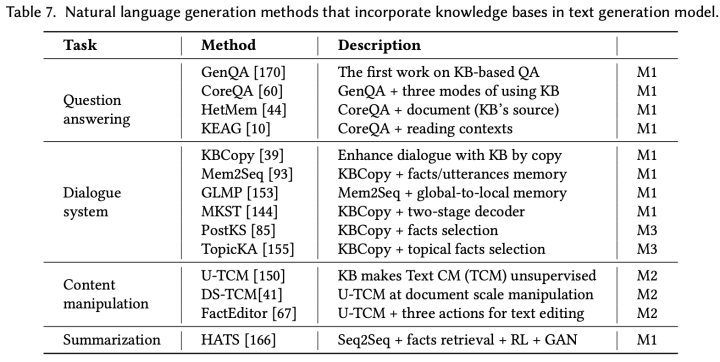
图 7
根据知识库和文本序列之间的关系,这些模型可以总结为三种方法:
M1:针对知识库设计有监督任务进行联合优化:某些任务需要从知识库中检索有用的知识,而这些知识可能对于文本生成任务而言也是有效的,因此可以针对知识库设计有监督任务对模型参数进行联合优化。
M2:针对知识库设计无监督方法,作为额外条件因素:输入和输出文本之间可能具有某些潜在的相同之处,例如事实或事件,但由于语言、格式等原因导致这些相同之处在文本中差异很大。那么,知识库可以看作是生成输入和输出文本的条件
M3:选择知识库或事实增强知识融合:知识库的相关性对于发现文本生成中的知识是非常重要的。所以,如何选择从知识库中选择相关的事实知识可以增强后续的知识融合。
下面详细介绍这三种方法:
针对知识库设计有监督任务进行联合优化 传统的Seq2Seq模型虽然可以学习到某些语言模式(例如语言多样性),但却无法很好地对文本中离散的概念进行表示,无法达到知识融合之后预期的效果。为了有效地融合利用知识库中的知识,本方法的主要思想是在多个任务上进行联合训练。例如,当目标任务是生成问题回答时,额外的任务可以包括问题理解和知识库知识检索,这些知识可以在联合的encoder-decoder框架里共享。具体地,问题理解和知识检索任务是高度相关的,因为对问题的理解可以促进问题与知识库中相关知识的匹配。例如,如果问题是“Where was Barack Obama born in the U.S.?”,短语“Barack Obama”可以与知识库中的三元组(Barack Obama, born, Hawaii)进行匹配。解析问题然后检索相关知识可以帮助排除不相关的信息,避免后续生成回答时引入不相关的知识。
GenQA是第一个使用知识库生成问题回答的工作,它能够从知识库中检索单词帮助生成。但是,GenQA没有考虑输入问题中相关的单词,因此无法处理复杂问题的情况。进一步地,CoreQA同时使用拷贝和检索机制生成回答,它设计了一个检索模块基于对问题的理解从知识库中检索相关的事实,这个检索模块会计算输入问题表示 和每个相关事实 之间的匹配分数。在知识库中,每个事实 的表示为subject,predicate和object三者的表示拼接而成: 。在生成过程中,融入的信息可以通过注意力机制融入decoder中: 。CoreQA预测单词的概率包括三个部分:(i) 从全局词典生成单词;(ii) 从知识库检索事实单词;(iii) 从输入序列拷贝单词。
针对知识库设计无监督方法,作为额外条件因素 自然语言有着多样的格式,例如新闻文章,科学论文和社交媒体推文的格式差别都非常大。目前有一部分工作关注可控的文本生成任务,即将文本的某个属性修改为目标属性而不影响文本的主要内容,称为content manipulation。例如,给定一个结构化的知识 (player: "Lebron James", points: "20", assists: "10")和输入序列 “Kobe easily dropped 30 points”,目标是生成和序列 格式相同的文本“Lebron easily dropped 20 points and 10 assists”。一大挑战是需要理解文本的结构,根据输入序列的格式进行模仿,同时保证输出文本的语法正确性和流畅性,这里不需要真实目标文本 进行训练,因此是一种无监督的方法。
U-TCM则是解决上述问题的一个无监督模型,它同时优化两个目标函数。第一个目标函数是content fidelity,第二个目标函数是style preservation。 表示包含目标格式的序列 和其对应的知识 ,这个任务目标是按照序列 X 的格式生成包含知识 的文本 。首先,content fidelity函数是基于 和 重构原始序列 ,即 ;然后,style preservation函数是基于 和 重构原始序列 ,即 ;最后,这两个目标函数相加,e达到最终的优化目标。
选择知识库或事实增强知识融合 将知识融入文本生成模型,最简单的方法则是对输入序列进行解析,然后检索出最相关的知识,最后基于输入序列和检索出的知识生成文本。我们希望检索出的知识可以帮助建立起输入和输出之间的依赖关系,但由于知识的复杂性,我们检索出的知识并不总是相关的。虽然PostKS通过一个检索模型(例如,计算语义相似度)从知识库中选择知识,但由于知识的多样性,基于输入句子检索出不同的知识就可能导致最终生成的文本出现偏差。因此,给定一个输入句子和目标回复,我们可以构建从输入句子和目标回复到知识库上的后验概率分布,这个后验分布可以为模型提供额外的指导。上述现象可以称为先验和后验分布之间的差异,模型往往是基于先验分布(从输入句子到知识库)选择合适的知识,但这很难保证后验分布的准确性(从输出到知识库)。
为了解决上述差异,Lian等人和Wu等人提出利用先验分布近似后验分布,以选择合适的知识。他们引入了一个额外的损失,即KL散度损失,来衡量先验分布和后验分布之间的接近程度:
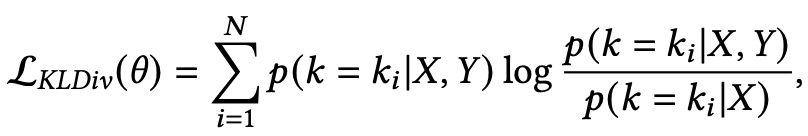
4.2 知识图谱增强的文本生成
知识图谱(knowledge graph, KG)是一种结构化的人类知识。知识图谱包括若干结构化的知识三元组,三元组由实体(entities),关系(relations)和语义描述(semantic description)所组成。知识库和知识图谱通常不区分使用,但本质上却是不一样的。知识图谱通常是一个图结构,实体之间的直接联系称为一阶关系。目前知识图谱在许多应用上都取得了不错的效果,例如推荐系统,对话系统和问答生成。相比于知识库中独立的三元组,借助知识图谱上相连接实体和关系之间丰富的语义信息更加有利于文本生成任务。
在知识图谱中,节点嵌入(node embedding)和关系路径(path of connected links)对于下游文本生成任务都有着不同的重要性,对应于两种技术:知识图谱嵌入(knowledge graph embedding)和基于路径的知识图谱推理(path based knowledge graph reasoning)。而且,随着图神经网络(graph neural network, GNN)和graph-to-sequence encoder-decoder架构的出现,在文本生成任务中引入多跳和高阶关系更加便捷和高效。下面形式化地定义关于知识图谱的概念。

知识图谱是一个有向多关系图,由实体和关系组成。知识图谱通常定义为 ,其中 是实体节点集合, 是类型边集合。在这个章节,我们只考虑本体论中的知识图谱,即每个边都是完全无歧义的。
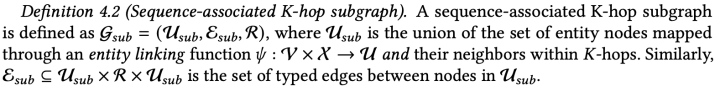
跳子图 的实体包含实体集 中的实体,以及与这些实体相连K跳之内的实体。

跳路径指的是从实体 出发,按照关系 连接而成的实体关系序列。下图8列出了目前将知识图谱融入文本生成任务的模型。
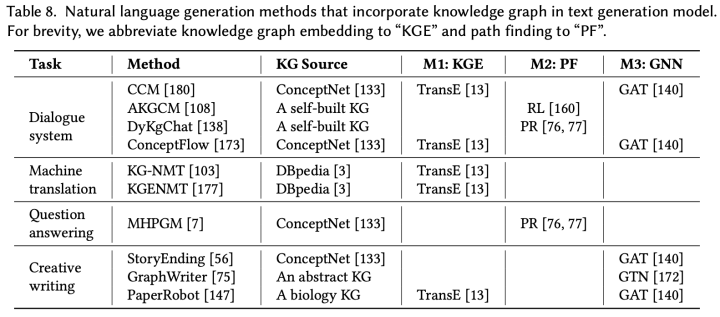
图 8
根据如何学习知识图谱和输入/输出序列之间的关系,这些模型可以分为以下三种方法:
M1:将知识图谱嵌入融入文本生成:知识图谱嵌入技术通过某些函数将实体和关系映射到向量空间,同时保持知识图谱潜在的结构特性。但是,知识图谱嵌入只依赖一跳关系,并且受到打分函数的影响。
M2:通过路径寻找策略在知识图谱上进行推理:路径寻找策略可以提供灵活的多跳路径,相比于一跳关系而言。更重要的是,路径寻找在知识图谱上是一种推理的过程,可以应用到许多复杂问答生成和对话系统等场景中。
M3:使用图神经网络增强图表示:图神经网络和graph-to-sequence框架打通了图表示和文本生成之间的壁垒。许多文本生成任务并不需要进行推理,更关注对于知识图谱全局上下文的理解,所以图神经网络可以帮助将知识图谱中丰富的语义和结构化信息融入文本生成。
下面具体介绍这三种方法。
将知识图谱嵌入融入文本生成 知识图谱提供了不同实体节点之间的连接信息,因此知识图谱嵌入可以刻画实体节点之间的语义关联。基本的想法是将实体和关系映射到低维向量空间 (其中 ),这样可以减少数据唯独,同时保持知识图谱潜在的结构信息。在知识图谱嵌入中,TransE是其中广泛使用的方法,给定一个知识图谱边 ,可以看做是从头实体以很小的误差经过关系“翻译”到尾实体,即 。知识图谱嵌入一般采用基于margin的优化目标,因此需要构建负例集合,采取的方式是随机选择一个实体替换三元组中的头实体或尾实体,最后通过随机梯度下降和L2正则优化:
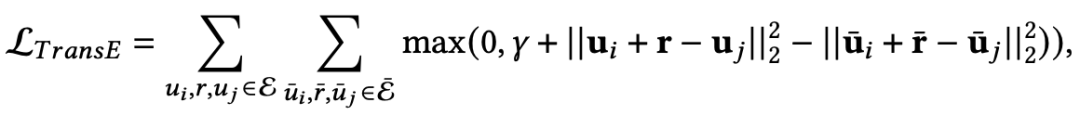
其中 为正例, ( , , )是负例。文本生成模型可以在encoder和decoder中融入实体和关系的表示。
通过路径寻找策略在知识图谱上进行推理 知识图谱嵌入在计算时利用的是一跳关系的路径,而知识图谱推理可以显式地在关系路径在进行推理,对多种关系做出决策。以问答生成为例,为了理解复杂的问题,需要在知识图谱上进行推理得出潜在的和问题相关的实体,从而生成答案。所以,难点在于如何识别出知识图谱上期望的的实体集合,这些实体往往通过某些概念和关系连成序列。基于路径的寻找方法可以探索实体之间的多种连接模式,学习到可以提供给生成过程的最佳路径。
基于路径的寻找方法主要分为两种:(i)基于路径排序的方法;(ii)基于强化学习的方法。路径排序算法(path ranking algorithm, PRA)使用随机游走策略进行多界深度优先搜索(multiple bounded depth -first search)来寻找关系路径。配合基于弹性网的学习(elastic-net based learning),PRA可以剪去哪些虽然符合事实但非理想的的路径,从而找到更加合适的路径。例如,DyKgChat提出一种基于路径排序算法在动态知识图谱上的神经对话模型。在生成阶段,为了生成富信息的文本,模型将从两个网络中选择一个输出,包括一个GRU decoder和一个基于PRA的多跳推理网络。但是,一个主要的缺点是PRA作用在离散空间中,使得它很难找到知识图谱上相似的实体和关系。MHPGM通过一个3步打分策略(初始节点打分,累积节点打分,路径选择)对路径进行排序和过滤,来保证加入信息的质量和多样性。
基于强化学习的方法通过在一个连续空间中寻找路径进行推理,这类方法在路径寻找的奖励函数中引入多种评测手段,使得路径寻找的过程更加灵活。Xiong等人提出DeepPath,这是第一个使用马尔可夫决策过程(Markov Decision Process, MDP)和强化学习在知识图谱上寻找路径的方法。但是,MDP的状态要求目标实体事先是已知的,所以这个路径寻找策略依赖于答案实体。因此,这个方法无法应用于许多现实场景的问答生成和对话系统中。基于强化学习的路径寻找方法一般包括两个阶段:(i)将序列 作为输入从知识图谱中检索出开始节点 ,进行多跳图推理最终到达一个终止节点 ,这条从 到 的关系路径包含了文本生成所需要的知识信息;(ii)利用两个encoder对输入序列 和路径 进行表示,分别对其使用注意力机制解码生成文本。基于路径的知识图谱推理技术可以将知识图谱的图结构转化为一条序列化路径,从而更容易使用序列encoder(例如,RNN)进行编码表示。
使用图神经网络增强图表示 许多文本生成任务不需要推理过程,更关注对知识图谱上下文的理解。例如,文本摘要任务需要对知识图谱整体进行结构化的表示,促进相关实体之间的联系,以及对全局上下文(例如实体交互)的理解。文本生成模型可以在encoder和decoder两个方向使用图神经网络增强图表示。
对于encoder来说,最简单的借助GNN引入知识图谱的方法是通过实体向量增强单词的语义。一个预定义的实体链指函数: : 可以将输入序列中的单词映射到知识图谱上对应的实体节点。对于一个输入序列,所有链指的实体和他们 跳之内的邻居可以表示为上述的sequence-associated K-hop subgraph ,对于 上的每个实体,可以利用知识图谱结构和实体、边的特征学习到向量表示 ,然后通过 函数从所有实体节点表示学习子图表示,即 。对于decoder来说,可以利用子图表示增强初始隐状态,即 。经过知识图谱增强的decoder在每个时间步对子图使用注意力机制可以得到图感知的上下文向量,进而从子图中选择单词或实体进行生成。因为基于图级别的注意力可能会忽略细粒度的知识信息,因此许多工作开始采用层次化的图注意力机制。他们首先对检索的子图 使用注意力机制,然后对子图上的边 使用注意力机制,decoder隐状态计算如下: ,其中 表示图级别的上下文向量, 表示边级别的上下文向量。
4.3 依赖图增强的文本生成
一般而言,依赖图包括语法依赖图和语义依赖图。语法依赖图是一个有向无环图,表示单词之间的语法关系。例如,对于句子“The monkey eats a banana”,“monkey”是谓语“eats”的主语,“banana”则是宾语。利用单词之间的语法依赖关系可以增强序列表示,捕捉到长距离上的依赖关系。在文本生成中,语法依赖信息可以通过三种方式进行刻画:(i)线性表示:线性化语法依赖图然后使用序列模型,例如RNN,获取语法感知的表示;(ii)基于路径的表示:基于单词和中心位置的线性距离计算注意力权重;(iii)基于图的表示:使用图神经网络聚合依赖关系。语义依赖图表示句子中内容词之间的predicate-argument关系,不同的标注系统下具有多种表现模式(例如,DM)。语义依赖图上的节点可以通过semantic role labeling (SRL)和dependency parsing抽取得到,然后节点可以通过不同的关系进行连接。Jin等人提出一个语义依赖指导的摘要模型,堆叠多个encoder模块,这些encoder包括一个序列encoder和一个图encoder。其他工作也借助abstract meaning representation(AMR)作为语义图。
五、基于文本增强的文本生成
这里的文本指的是与输入序列相关,能够提供额外知识的文本,称为knowledge grounded text。这些文本不会出现在训练语料和结构化库(例如知识库和知识图谱)中,但是可以从在线资源中获取大量相关文本。这些在线资源包括百科全书(例如Wikipedia),社交媒体(例如Twitter),购物网站(例如Amazon reviews)。这些文本对于理解文本语义和上下文语境发挥重要的作用。例如,Wikipedia文章可以提供关于输入文本的解释和背景信息,Amazon reviews包含了许多商品相关问题的答案和意见,Tweets提供了关于某个事件人们的看法和观点。因此,这些文本通常会作为重要的知识信息帮助文本生成任务。下图9总结了目前利用文本增强文本生成的代表性工作。
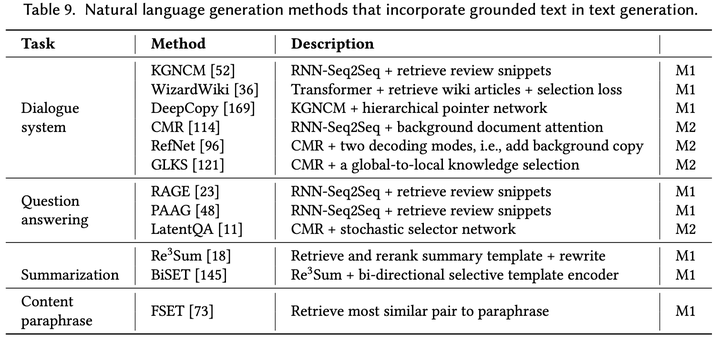
图 9
这些工作大概可以分为两类:
M1:利用检索信息指导生成:因为这些文本往往不会出现在训练语料中,一个想法就是从额外的来源检索出相关的文本,然后融入生成过程中。这个过程类似于设计一个针对知识图谱的获取和融入,区别是这些文本可以是无结构和有噪声的,而研究者需要设计知识选择和融入方法来克服这个问题。
M2:在回复生成中建模背景文本:背景文本有着更加全局和广泛的知识信息,可以用来生成富信息的对话回复,保证对话不偏离主题。围绕背景文本的对话称之为background based conversarion(BBC)。因此,在对话系统中,寻找合适的背景文本并基于这些文本生成回复是非常重要的。
下面具体介绍这两种方法。
利用检索信息指导生成 在对话系统和问答生成中,人们往往需要搜索额外需要的信息来进行回复和回答问题,但是数据集中往往缺乏这些信息。下面给出一个对话例子:
User input: "Going to Kusakabe tonight."
Reviews on Foursquare: "Consistently the best omakase in San Francisco."
Response given by vanilla Seq2Seq: "Have a great time!"
Golden Response: "You'll love it! Try omakase, the best in town."
虽然来自Seq2Seq模型的回复也合适,但与真实回复相比缺少有意义内容。为了增加与输入文本相关的事实信息,一个想法是检索包含背景信息的相关事实和评论片段。检索文本的方式有很多种,包括根据相关实体进行索引然后计算文本匹配度,以及使用一些统计方法(例如TF-IDF)给相关文本进行评分。
除了检索出相应文本片段,另一个方式是检索相关的文本模板。在文本摘要中,基于模板的方法往往假设与真实摘要相似的句子可以作为“模板”,指导摘要文本的生成。这些模板通常称之为soft template,区别于传统的基于规则的模板。基于soft template的摘要模型通常包括三个阶段:检索、重排和重写。检索是为了从摘要集合中返回若干候选模板,重排是从这些候选模板中选择最好的模板,重写则是借助输入文本和模板生成更加真实、信息丰富的摘要。与检索相应片段类似,可以根据模板和输入文档之间的相似性进行排序。重排模块则希望识别出尽可能与目标摘要 相似的最好模板,这里的相似度可以通过ROUGE进行计算。
在回复生成中建模背景文本 背景知识在人与人的对话中发挥着重要的作用,例如当谈论电影时,人们通常会回忆一些重要信息,包括电影的场面等,然后在之后对话合适的位置提及。因此,上述BBC任务的难点在于不仅需要定位背景片段中正确的语义单元,还需要在生成过程中合适的位置和事件插入这些背景信息。BBC模型需要根据生成的回复寻找合适的背景知识片段,因此BBC模型往往会设计阅读理解模块。阅读理解模块可以有效地将输入序列
编码为query,同时编码背景文本 B 为上下文
,然后计算decoder隐状态
和背景之间的上下文向量:

六、未来展望
综上所述,目前已有相当一部分工作致力于知识增强的文本生成研究。为了促进领域发展,目前仍然存在着许多开放问题等待解决,以及具有前景的未来方向。首先,设计更加有效的知识表示方法然后融入文本生成过程中仍然是这个研究方向最重要的趋势。其次,研究者们应该探索如何更广泛地发现知识,并将不同来源的多种形式的知识结合起来,以改进生成过程。例如,多任务学习可以实现知识表示和文本生成之间的相互增强与相互促进。
七、参考论文
[1] Bahdanau, D., Cho, K., & Bengio, Y. (2014). Neural machine translation by jointly learning to align and translate.arXiv preprint arXiv:1409.0473.
[2] Gu, J., Lu, Z., Li, H., & Li, V. O. (2016). Incorporating copying mechanism in sequence-to-sequence learning.arXiv preprint arXiv:1603.06393.
[3] See, A., Liu, P. J., & Manning, C. D. (2017). Get to the point: Summarization with pointer-generator networks.arXiv preprint arXiv:1704.04368.
[4] Sukhbaatar, S., Szlam, A., Weston, J., & Fergus, R. (2015). End-to-end memory networks.arXiv preprint arXiv:1503.08895.
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“KETG” 就可以获取《知识增强的文本生成研究进展》专知下载链接






