面试题:简单介绍下LR

简单介绍下LR
解析:
@rickjin:把LR从头到脚都给讲一遍。建模,现场数学推导,每种解法的原理,正则化,LR和maxent模型啥关系,lr为啥比线性回归好。
有不少会背答案的人,问逻辑细节就糊涂了。
原理都会? 那就问工程,并行化怎么做,有几种并行化方式,读过哪些开源的实现。
还会,那就准备收了吧,顺便逼问LR模型发展历史。
虽然逻辑斯蒂回归姓回归,不过其实它的真实身份是二分类器。
先弄清楚一个概念:线性分类器。
给定一些数据点,它们分别属于两个不同的类,现在要找到一个线性分类器把这些数据分成两类。
如果用x表示数据点,用y表示类别(y可以取1或者-1,分别代表两个不同的类),一个线性分类器的学习目标便是要在n维的数据空间中找到一个超平面(hyper plane),这个超平面的方程可以表示为( wT中的T代表转置):![]()
可能有读者对类别取1或-1有疑问,事实上,这个1或-1的分类标准起源于logistic回归。
Logistic回归目的是从特征学习出一个0/1分类模型,而这个模型是将特性的线性组合作为自变量,由于自变量的取值范围是负无穷到正无穷。
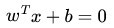
因此,使用logistic函数(或称作sigmoid函数)将自变量映射到(0,1)上,映射后的值被认为是属于y=1的概率。
假设函数
其中x是n维特征向量,函数g就是logistic函数。
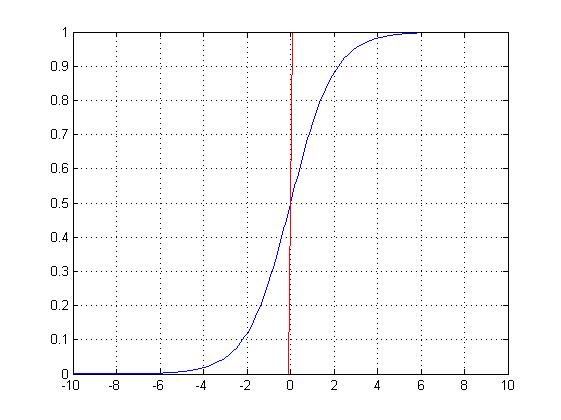
而的图像是
可以看到,将无穷映射到了(0,1)。
而假设函数就是特征属于y=1的概率。
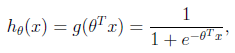
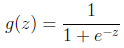 的图像是
的图像是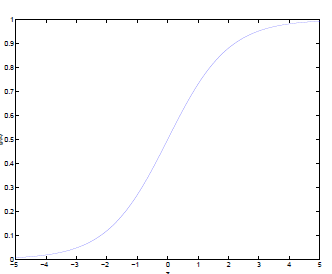
从而,当我们要判别一个新来的特征属于哪个类时,只需求即可,若大于0.5就是y=1的类,反之属于y=0类。
福利时间
VIP年会员+机械键盘+京东购物卡
及总价超千元的精品课程免费送!
↓快来扫它!直接领!↓



毕业/转行就拿50万+年薪!15位同学经验分享,他们怎么做到的?




登录查看更多
相关内容




相关VIP内容
相关资讯
相关论文