商汤ICCV论文解读:自然场景下文字检测的几何归一化网络(GNNets)
点击上方“CVer”,选择加"星标"或“置顶”
重磅干货,第一时间送达

编辑:Amusi

今年的ICCV,商汤科技及联合实验室共有57篇论文入选ICCV 2019(包含11篇Oral),同时在Open Images、COCO、LVIS等13项重要竞赛中夺冠!

本文简要介绍商汤科技研究团队在ICCV2019上录用的一篇文章:Geometry NormalizationNetworks for Accurate Scene Text Detection(GNNets),针对自然场景下文字检测的几何归一化网络。该文章通过对待处理图像的特征图进行几何变换,从而将待处理图像中几何分布差异较大的文本框归一化到一定的几何分布范围内,提高了自然场景下文本检测的效果。
论文链接:https://arxiv.org/abs/1909.00794
一、研究背景
随着深度学习的迅速发展,计算机视觉技术对实际生产具有影响越来越重要的影响。对图像中的文本进行检测和识别,有助于计算机理解视觉内容。由于卷积神经网络(CNN)方法的通用性,自然场景文本检测受益于常规物体检测而快速发展。但由于自然场景中的文本在实际应用场景中具有较大的几何变化(例如宽高比或文字方向),所以其自身仍存在巨大的挑战。对于尺度变化问题,现有方法一般通过使用一个检测头(detection header)对不同层级的特征进行检测,利用NMS融合结果后作为输出或者使用类似FPN [1]的网络将多尺度特征融合然后进行文本检测。对于角度变化问题,现有方法一般通过直接回归文本框角度或使用对方向敏感的卷积来预测任意方向。但目前的方法中要求检测头(detection header)需要学习到文字巨大的几何差异或者检测头(detectionheader)仅在所有训练样本中一个子集进行学习,这可能导致性能欠佳。
作者研究了几何分布对场景文本检测的影响,发现基于CNN的检测器只能捕获有限的文本几何分布,但充分利用所有训练的样本可以提高其泛化能力。为了解决上述难题,作者提出了一种新颖的几何规范化模块(GNM)。每个自然场景图片中的文本实例可以通过GNM归一化到一定的几何分布范围内。这样所有训练样本均被归一化为有限的分布,因此可以有效地训练一个共享的文本检测头。本文提出的GNM是通用的,可以直接将该模块插入到任何基于CNN的文本检测器中。为了验证提出方法的有效性,作者针对文字方向的差异性新建了一个测试集(Benchmark)并发布。
二、方法描述

Fig.1. Overall architecture.
Fig. 1是GNNets的整体网络结构图。总体网络结构由Backbone,GNM,SharedText Detection Header组成。通过Backbone提取的特征图会被输入到具有多个分支的几何规范化模块(GNM)中,每个分支由一个尺度归一化单元(SNU)Fs和方向归一化单元(ONU)Fo组成。SNU有两个不同比例的尺归一化单位(S,S1/2)和四个方向归一化单位(O,Or,Of,Or + f)。通过SNU和ONU的不同组合,GNM会生成不同的几何归一化特征图,这些特征图将被输入到一个共享文本检测标头中。
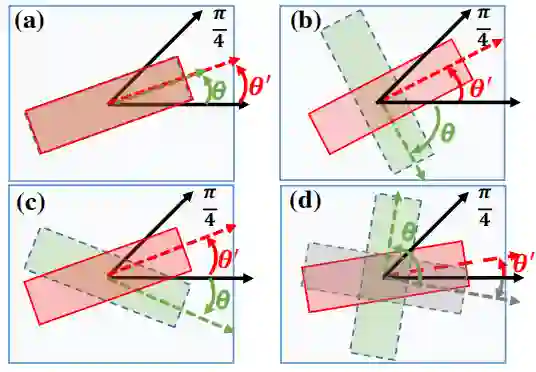
Fig.2. ONU.
Fig.2是作者提出的ONU模块的示意图。通过应用ONU可以更改文本框方向。如图所示“绿色”框是原始框,“灰色”框是转换过程中的中间框,“红色”框是ONU的输出的结果框。θ和θ’分别是原始框和结果框的角度。(a),(b),(c)和(d)分别是O,Or,Of,Or + f的过程的示意图。由上图可以简单明了的表示ONU具有将[0,π/4],[-π/2,-π/4],[-π/4,0]和[π/4,π/2]角度的文本转换为在[0,π/4]角度的文本。
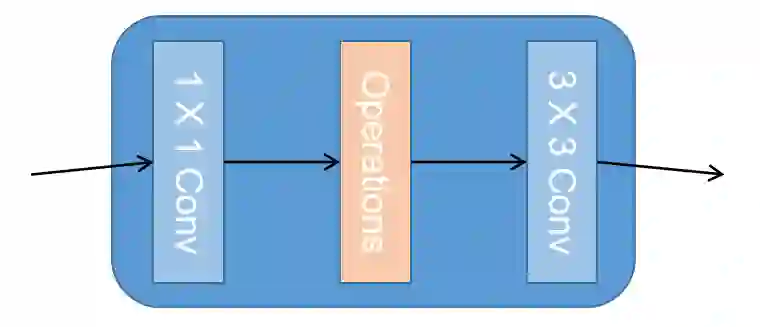
Fig.3. Architecture of GNM.
Fig. 3展示了GNM在网络中的结构设置。对于SNU中的S使用1x1的卷积操作和3x3的卷积操作;S1/2使用1X1的卷积,步长为2的下采样以及3x3的卷积。对于ONU中的O,Or,Of,Or + f中的Operations则分别采用不操作,旋转feature maps,翻转feature maps和旋转后再翻转feature maps。
由于多分支网络的影响,作者提出了一个针对GNNets的抽样训练策略。在训练期间,作者随机采样一个文本实例,并通过旋转和调整大小7次来对其进行扩充,以使GNM的每个分支在每批次中都具有有效的文本实例用于训练。这样可以对GNM的所有分支进行统一训练。并且在训练过程中如果文本实例不在预先设定的几何区间内,则忽略分支中的该文本实例。在测试过程中,作者将GNM中所有分支输出文本框相应地反向投影到原始比例和方向。不在分支预先设定的几何区间内的文本框会被丢弃。其余的文本框通过NMS合并。
三、实验结果
Table 1. Comparison with the state-of-the-art methods onboth ICDAR 2015 and ICDAR 2017 MLT.
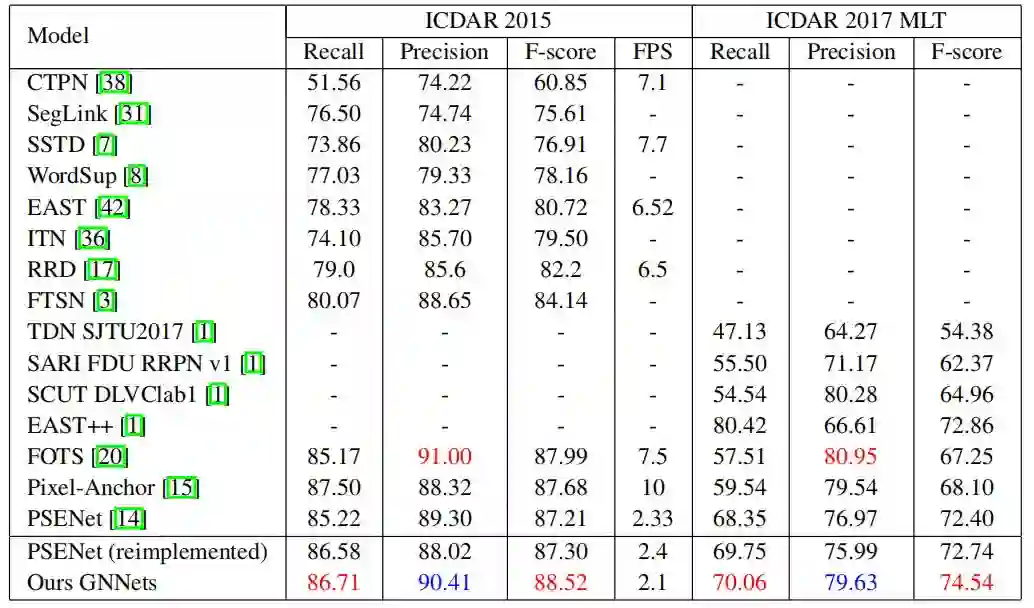
与原始的PSENet[2] 相比,作者提出的GNNets在ICDAR 2015[3]和ICDAR 2017 MLT [4]上分别实现了约1.3%和2.1%的性能提升。与ICDAR2015上的EAST[5]和ITN [6]相比,GNNet的F-score比它们分别高出8%和9%。与FTSN [7]相比,获得了4.5%的性能提升。GNNets在ICDAR 2015上的表现优于FOTS [8],在ICDAR 2017 MLT上的F-score更超出其7.3%。并且FOTS使用了文字识别的数据。在单尺度测试中,作者提出的GNNets在ICDAR 2015和ICDAR2017 MLT上均达到了state-of-the-art的性能。Fig. 5可视化了GNNets和其他文本检测方法在ICDAR 2015和ICDAR 2017 MLT上的检测结果。

Fig.5. Qualitative results on ICDAR2015 and ICDAR 2017 MLT. The right column shows GNNets results.
四、总结及讨论
1. 在本文中,作者提出了一种新颖的几何归一化模块(GNM)以生成多个几何感知特征图。并且GNM是通用的,可以应用到任何基于CNN的检测器中,以构建端到端的几何归一化网络(GNNet)。实验表明,GNNet在检测几何分布较大的文本实例方面相较于baseline表现出出色的性能。并且,GNNet在两个文字检测主流的数据集上较最新的方法获得了显著的性能提升。
2. 文中研究了几何分布对场景文本检测的影响,发现基于CNN的检测器只能捕获有限的文本几何分布,但充分利用所有训练的样本可以提高其泛化能力,对后续文字检测以及其他相关领域有启发性影响。
3. 综上所述,文本检测是OCR任务的首要前提,但自然场景下文字的字体变化、悬殊的宽高比、任意角度给检测任务带来巨大的挑战,本文为我们提出了目前研究方向上忽略的点,并提供了一个新颖的解决方法,但是相较于常规物体检测,文本检测领域仍然有其特殊性以及较大的提升空间。
参考文献
[1] Tsung-Yi Lin, Piotr Dollar, Ross Girshick, Kaiming He, Bharath Hariharan,and Serge Belongie. Feature Pyramid Networks for Object Detection. In CVPR,2017.
[2] Xiang Li, Wenhai Wang, Wenbo Hou, Ruo-Ze Liu, Tong Lu, and Jian Yang. ShapeRobust Text Detection with Progressive Scale Expansion Network. arXiv preprintarXiv:1806.02559, 2018.
[3] Dimosthenis Karatzas, Lluis Gomez-Bigorda, Anguelos Nicolaou, Suman Ghosh,Andrew Bagdanov, Masakazu Iwamura, Jiri Matas, Lukas Neumann, Vijay RamaseshanChandrasekhar, Shijian Lu, and Others. ICDAR 2015 Competition on RobustReading. In ICDAR, 2015.
[4] ICDAR2017 Competition on Multi-Lingual Scene Text Detection and ScriptIdentification. http://rrc.cvc.uab.es/?ch=8&com=introduction, 2017.
[5] Xinyu Zhou, Cong Yao, He Wen, Yuzhi Wang, Shuchang Zhou, Weiran He, andJiajun Liang. EAST: An Efficient and Accurate Scene Text Detector. In CVPR,2017.
[6] Fangfang Wang, Liming Zhao, Xi Li, Xinchao Wang, and Dacheng Tao.Geometry-Aware Scene Text Detection with Instance Transformation Network. InCVPR, 2018.
[7] Yuchen Dai, Zheng Huang, Yuting Gao, Youxuan Xu, Kai Chen, Jie Guo, andWeidong Qiu. Fused Text Segmentation Networks for Multi-Oriented Scene TextDetection. In ICPR, 2018.
[8] Xuebo Liu, Ding Liang, Shi Yan, Dagui Chen, Yu Qiao, and Junjie Yan. Fots:Fast Oriented Text Spotting with a Unified Network. In CVPR, 2018.
重磅!CVer-场景文本检测交流群已成立
扫码可添加CVer助手,可申请加入CVer-场景文本检测交流群。一定要备注:研究方向+地点+学校/公司+昵称(如场景文本检测+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群

▲长按加群

▲长按关注我们
麻烦给我一个在看!