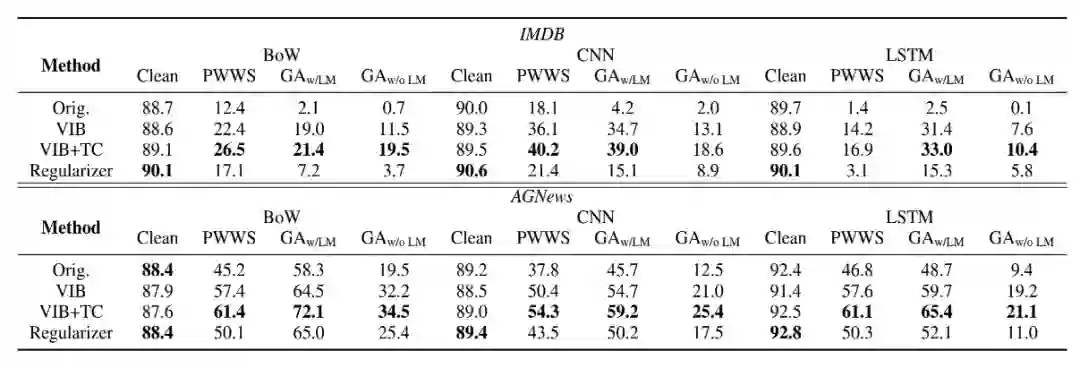
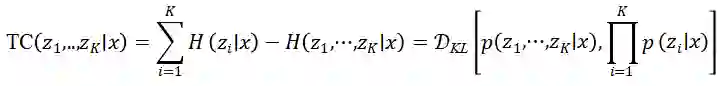在人脸识别和目标检测越来越普及的今天,如果说有一件衣服能让你在AI 检测系统中“消失无形”,请不要感到惊讶。由MIT-IBM Watson AI Lab研究者联合研发的这款基于对抗样本设计的T-shirt[3],如下图所示,可以让你无形穿梭于图像识别系统之间。该研究指出在客观的物理世界系统中同样难以避免这样的问题,也旨在引起大家对当下深度神经网络的安全问题的重视。
C. Szegedy et al., “Intriguing properties of neural networks,” presented at the 2nd International Conference on Learning Representations, ICLR 2014, Feb. 2014, Accessed: Mar. 24, 2021. [Online].
[2]
B. Biggio et al., “Evasion Attacks against Machine Learning at Test Time,” ECML PKDD 3, vol. 7908, pp. 387–402, 2013, doi: 10.1007/978-3-642-40994-3_25.
[3]
K. Xu et al., “Adversarial T-shirt! Evading Person Detectors in A Physical World,” Eur. Conf. Comput. Vis., Jul. 2020, Accessed: Mar. 24, 2021. [Online]. Available: http://arxiv.org/abs/1910.11099.
[4]
M. Cheng, W. Wei, and C.-J. Hsieh, “Evaluating and Enhancing the Robustness of Dialogue Systems: A Case Study on a Negotiation Agent,” in Proceedings of the 2019 Conference of the North, Minneapolis, Minnesota, 2019, pp. 3325–3335, doi: 10.18653/v1/n19-1336.
[5]
E. Dinan, S. Humeau, B. Chintagunta, and J. Weston, “Build it Break it Fix it for Dialogue Safety: Robustness from Adversarial Human Attack,” in Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 2019, pp. 4536–4545, doi: 10.18653/v1/D19-1461.
[6]
A. Einolghozati, S. Gupta, M. Mohit, and R. Shah, “Improving Robustness of Task Oriented Dialog Systems,” ArXiv191105153 Cs, Nov. 2019, Accessed: Jun. 27, 2020. [Online]. Available: http://arxiv.org/abs/1911.05153.
[7]
R. Jia and P. Liang, “Adversarial Examples for Evaluating Reading Comprehension Systems,” presented at the Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, Jul. 2017, Accessed: Jun. 27, 2020. [Online]. Available: http://arxiv.org/abs/1707.07328.
[8]
W. E. Zhang, Q. Z. Sheng, A. Alhazmi, and C. Li, “Adversarial Attacks on Deep-learning Models in Natural Language Processing: A Survey,” ACM Trans. Intell. Syst. Technol., vol. 11, no. 3, pp. 1–41, May 2020, doi: 10.1145/3374217.
[9]
M. T. Ribeiro, T. Wu, C. Guestrin, and S. Singh, “Beyond Accuracy: Behavioral Testing of NLP models with CheckList,” May 2020, pp. 4902--4912, Accessed: Jan. 08, 2021. [Online]. Available: http://arxiv.org/abs/2005.04118.
[10]
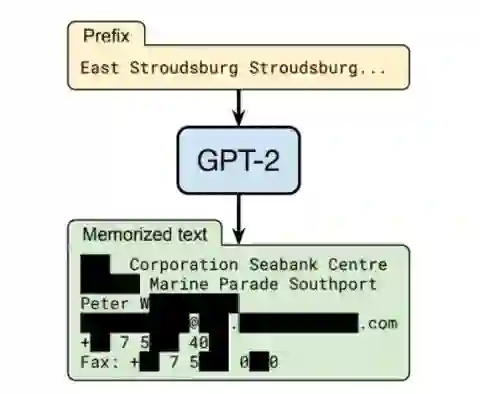
N. Carlini et al., “Extracting Training Data from Large Language Models,” ArXiv201207805 Cs, Dec. 2020, Accessed: Dec. 18, 2020. [Online]. Available: http://arxiv.org/abs/2012.07805.
[11]
M. Cheng, J. Yi, P.-Y. Chen, H. Zhang, and C.-J. Hsieh, “Seq2Sick: Evaluating the Robustness of Sequence-to-Sequence Models with Adversarial Examples,” in Proceedings of the AAAI Conference on Artificial Intelligence, Apr. 2020, vol. 34, pp. 3601–3608, Accessed: Jun. 27, 2020. [Online].
[12]
Z. Shi, H. Zhang, K.-W. Chang, M. Huang, and C.-J. Hsieh, “Robustness Verification for Transformers,” presented at the International Conference on Learning Representations, Feb. 2020, Accessed: Mar. 28, 2021. [Online]. Available: https://arxiv.org/abs/2002.06622v2.
[13]
B. Barrett, A. Camuto, M. Willetts, and T. Rainforth, “Certifiably Robust Variational Autoencoders,” ArXiv210207559 Cs Stat, Feb. 2021, Accessed: Mar. 09, 2021. [Online]. Available: http://arxiv.org/abs/2102.07559.
[14]
T. Gui et al., “TextFlint: Unified Multilingual Robustness Evaluation Toolkit for Natural Language Processing,” ArXiv210311441 Cs, Mar. 2021, Accessed: Mar. 26, 2021. [Online]. Available: http://arxiv.org/abs/2103.11441.
[15]
V. Behzadan and A. Munir, “Vulnerability of Deep Reinforcement Learning to Policy Induction Attacks,” ArXiv170104143 Cs, Jan. 2017, Accessed: Apr. 01, 2021. [Online]. Available: http://arxiv.org/abs/1701.04143.
[16]
H. Dai et al., “Adversarial Attack on Graph Structured Data,” ArXiv180602371 Cs Stat, Jun. 2018, Accessed: Mar. 24, 2021. [Online]. Available: http://arxiv.org/abs/1806.02371.
[17]
N. Papernot, P. McDaniel, and I. Goodfellow, “Transferability in Machine Learning: from Phenomena to Black-Box Attacks using Adversarial Samples,” ArXiv160507277 Cs, May 2016, Accessed: Mar. 29, 2021. [Online]. Available: http://arxiv.org/abs/1605.07277.
[18]
张钹, 朱军, and 苏航, “迈向第三代人工智能,” 中国科学:信息科学, vol. 50, no. 09, pp. 1281–1302, 2020, doi: 10.1360/zf2010-40-9-1281.
[19]
I. J. Goodfellow, J. Shlens, and C. Szegedy, “Explaining and Harnessing Adversarial Examples,” ArXiv14126572 Cs Stat, Mar. 2015, Accessed: Mar. 24, 2021. [Online]. Available: http://arxiv.org/abs/1412.6572.
[20]
S.-M. Moosavi-Dezfooli, A. Fawzi, O. Fawzi, and P. Frossard, “Universal adversarial perturbations,” ArXiv161008401 Cs Stat, Mar. 2017, Accessed: Mar. 24, 2021. [Online]. Available: http://arxiv.org/abs/1610.08401.
[21]
Y. Dong, F. Bao, H. Su, and J. Zhu, “Towards Interpretable Deep Neural Networks by Leveraging Adversarial Examples,” ArXiv190109035 Cs Stat, Jan. 2019, Accessed: Jul. 05, 2020. [Online]. Available: http://arxiv.org/abs/1901.09035.
[22]
A. Ilyas, S. Santurkar, D. Tsipras, L. Engstrom, B. Tran, and A. Madry, “Adversarial Examples Are Not Bugs, They Are Features,” ArXiv190502175 Cs Stat, Aug. 2019, Accessed: Jun. 27, 2020. [Online]. Available: http://arxiv.org/abs/1905.02175.
[23]
A. Noack, I. Ahern, D. Dou, and B. Li, “An Empirical Study on the Relation Between Network Interpretability and Adversarial Robustness,” SN Comput. Sci., vol. 2, no. 1, p. 32, Feb. 2021, doi: 10.1007/s42979-020-00390-x.
[24]
B. Schölkopf et al., “Towards Causal Representation Learning,” ArXiv210211107 Cs, Feb. 2021, Accessed: Mar. 25, 2021. [Online]. Available: http://arxiv.org/abs/2102.11107.
[25]
A. Raghunathan, S. M. Xie, F. Yang, J. Duchi, and P. Liang, “Understanding and Mitigating the Tradeoff Between Robustness and Accuracy,” ArXiv200210716 Cs Stat, Feb. 2020, Accessed: Jun. 27, 2020. [Online]. Available: http://arxiv.org/abs/2002.10716.
[26]
Y. Li, T. Baldwin, and T. Cohn, “What’s in a Domain? Learning Domain-Robust Text Representations using Adversarial Training,” in Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 2 (Short Papers), New Orleans, Louisiana, 2018, pp. 474–479, doi: 10.18653/v1/N18-2076.
[27]
C. Zhu, Y. Cheng, Z. Gan, S. Sun, T. Goldstein, and J. Liu, “FreeLB: Enhanced Adversarial Training for Natural Language Understanding,” ArXiv190911764 Cs, Apr. 2020, Accessed: Mar. 31, 2021. [Online]. Available: http://arxiv.org/abs/1909.11764.
[28]
D. Pruthi, B. Dhingra, and Z. C. Lipton, “Combating Adversarial Misspellings with Robust Word Recognition,” in Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 2019, pp. 5582–5591, doi: 10.18653/v1/P19-1561.
[29]
Y. Zhou, J.-Y. Jiang, K.-W. Chang, and W. Wang, “Learning to Discriminate Perturbations for Blocking Adversarial Attacks in Text Classification,” in Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 2019, pp. 4903–4912, doi: 10.18653/v1/D19-1496.
[30]
N. Papernot, P. McDaniel, X. Wu, S. Jha, and A. Swami, “Distillation as a Defense to Adversarial Perturbations against Deep Neural Networks,” ArXiv151104508 Cs Stat, Mar. 2016, Accessed: Mar. 28, 2021. [Online]. Available: http://arxiv.org/abs/1511.04508.
[31]
A. Malinin and M. Gales, “Reverse KL-Divergence Training of Prior Networks: Improved Uncertainty and Adversarial Robustness,” p. 12.
[32]
X. Wang et al., “Protecting Neural Networks with Hierarchical Random Switching: Towards Better Robustness-Accuracy Trade-off for Stochastic Defenses,” in Proceedings of the Twenty-Eighth International Joint Conference on Artificial Intelligence, Macao, China, Aug. 2019, pp. 6013–6019, doi: 10.24963/ijcai.2019/833.
[33]
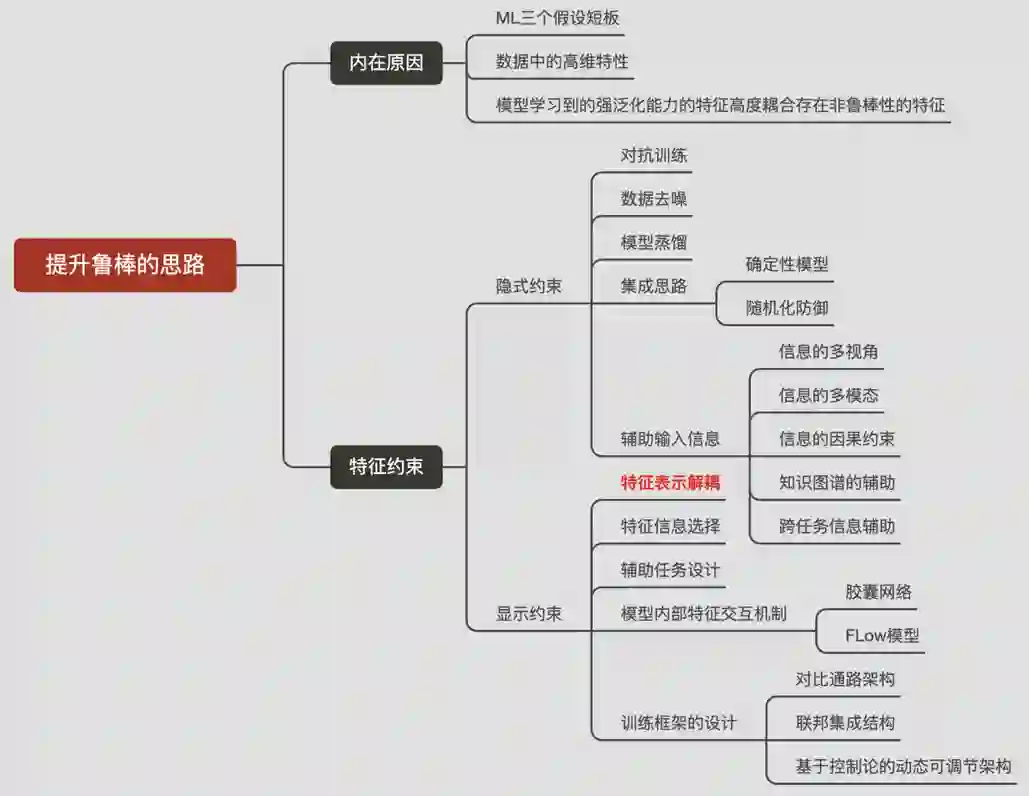
J. Wu, X. Li, X. Ao, Y. Meng, F. Wu, and J. Li, “Improving Robustness and Generality of NLP Models Using Disentangled Representations,” ArXiv200909587 Cs, Sep. 2020, Accessed: Sep. 30, 2020. [Online]. Available: http://arxiv.org/abs/2009.09587.
[34]
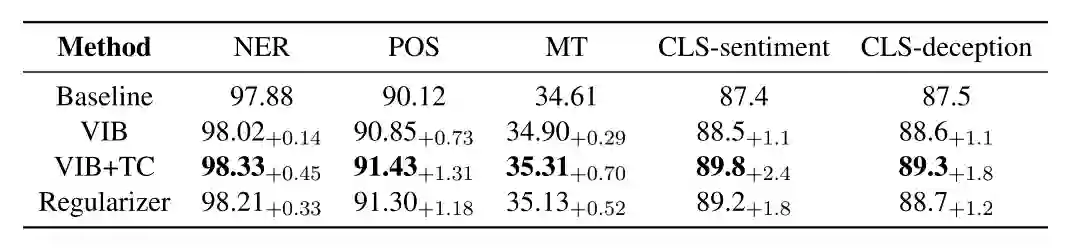
B. Wang et al., “INFOBERT: IMPROVING ROBUSTNESS OF LANGUAGE MODELS FROM AN INFORMATION THEORETIC PERSPECTIVE,” p. 21, 2021.
[35]
S. Sabour, N. Frosst, and G. E. Hinton, “Dynamic Routing Between Capsules,” ArXiv171009829 Cs, Nov. 2017, Accessed: Mar. 25, 2021. [Online]. Available: http://arxiv.org/abs/1710.09829.
[36]
A. Goyal et al., “Coordination Among Neural Modules Through a Shared Global Workspace,” ArXiv210301197 Cs Stat, Mar. 2021, Accessed: Mar. 21, 2021. [Online]. Available: http://arxiv.org/abs/2103.01197.
[37]
T. Pan, Y. Song, T. Yang, W. Jiang, and W. Liu, “VideoMoCo: Contrastive Video Representation Learning with Temporally Adversarial Examples,” ArXiv210305905 Cs, Mar. 2021, Accessed: Mar. 21, 2021. [Online]. Available: http://arxiv.org/abs/2103.05905.
[38]
T. Chen, S. Kornblith, M. Norouzi, and G. Hinton, “A Simple Framework for Contrastive Learning of Visual Representations,” p. 11.
[39]
N. Tishby, F. C. Pereira, and W. Bialek, “The information bottleneck method,” arXiv:physics/0004057, Apr. 2000, Accessed: Mar. 11, 2021. [Online]. Available: http://arxiv.org/abs/physics/0004057.
[40]
M. Alzantot, Y. Sharma, A. Elgohary, B.-J. Ho, M. Srivastava, and K.-W. Chang, “Generating Natural Language Adversarial Examples,” ArXiv180407998 Cs, Sep. 2018, Accessed: Jun. 27, 2020. [Online]. Available: http://arxiv.org/abs/1804.07998.
[41]
S. Ren, Y. Deng, K. He, and W. Che, “Generating Natural Language Adversarial Examples through Probability Weighted Word Saliency,” p. 13, doi: 10.18653/v1/P19-1103.
[42]
S. Chopra, R. Hadsell, and Y. LeCun, “Learning a Similarity Metric Discriminatively, with Application to Face Verification,” in 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 2005, vol. 1, pp. 539–546, doi: 10.1109/CVPR.2005.202.
[43]
E. Denton and V. Birodkar, “Unsupervised Learning of Disentangled Representations from Video,” ArXiv Cs Stat, May 2017, Accessed: Apr. 03, 2021. [Online]. Available: http://arxiv.org/abs/1705.10915.
[44]
L. Kong, C. de M. d’Autume, W. Ling, L. Yu, Z. Dai, and D. Yogatama, “A Mutual Information Maximization Perspective of Language Representation Learning,” ArXiv191008350 Cs, Nov. 2019, Accessed: Mar. 30, 2021. [Online]. Available: http://arxiv.org/abs/1910.08350.
[45]
K. Aas, C. Czado, A. Frigessi, and H. Bakken, “Pair-copula constructions of multiple dependence,” Insur. Math. Econ., vol. 44, no. 2, pp. 182–198, Apr. 2009, doi: 10.1016/j.insmatheco.2007.02.001.
[46]
K. Xu, C. Li, J. Zhu, and B. Zhang, “Understanding and Stabilizing GANs’ Training Dynamics using Control Theory,” in International Conference on Machine Learning, pp. 10566–10575.