如何使用 Google 的 AutoAugment 改进图像分类器

本文为 AI 研习社编译的技术博客,原标题 :
How to improve your image classifier with Google’s AutoAugment
作者 | Philip Popien
翻译 | 敬爱的勇哥 编辑 | 王立鱼
原文链接:
https://towardsdatascience.com/how-to-improve-your-image-classifier-with-googles-autoaugment-77643f0be0c9
注:本文的相关链接请访问文末【阅读原文】
通过使用优化的数据增强方法,在CIFAR-10、CIFAR-100、SVHN和ImageNet上得到了目前最好的结果。您可以从这里找到和使用它们。

在ImageNet上得到的最好的增强效果,
源自:https://arxiv.org/abs/1805.09501v1
AutoML——使用机器学习来改进机器学习设计(如体系结构或优化器)的想法——已经来到了数据增强的领域。本文将解释什么是数据增强,谷歌AutoAugment如何搜索最佳增强策略,以及如何将这些策略应用到您自己的图像分类问题。
数据增强(Data Augmentation)
数据增强意味着在训练机器学习模型时,对输入数据随机的应用各种变换。这种人为地扩大训练数据,可以生成更多可能的输入数据。它还有助于防止过度拟合,因为网络几乎从来不会看到完全相同的两次输入然后仅仅记住它们。典型的图像数据增强技术包括从输入图像中随机裁剪部分,水平翻转,应用仿射变换,如平移、旋转或剪切等。

源自:https://github.com/aleju/imgaug
事实上,正如 AutoAugment 作者所指出的,近年来在ImageNet挑战赛上,人们为寻找更好的网络结构投入了大量的精力,但是数据增强技术,基本上与Krizhevsky等人在2012年为AlexNet设计的方法相同,或者只有一些微小的变化。
现状
选择使用哪些数据增强的通用做法,是首先提出适合对应数据集的不同假设,然后进行试验。你可以从随机剪切、随机调整大小或者水平翻转开始,因为它们几乎总是有效的,并且还可以尝试诸如小尺度的旋转等。由于重复训练带来的验证集性能的随机波动,很难确定这些增加的旋转是否提高了模型性能,因为您可以从两次不同的训练中获得随机的改进,而这些改进并不是因为使用了数据增强。
通常来说,由于我们实验的高度不确定性,并且也没有时间或资源来严格测试所有的可能组合,所以我们放弃了搜索最好的方法,或者坚持使用某些固定的增强策略,而不知道它们是否有很大的贡献。但是,如果有一种可以迁移有用数据的增强技术,就像我们在迁移学习中从预先训练的模型中迁移参数一样,那会怎样呢?
从数据中学习增强策略
AutoAugment的思想是在强化学习(RL)的帮助下学习给定数据集的最佳增强策略。由于在图片上应用和组合转换的方法非常多,所以它们对可选择的方法增加了一些限制。一个主要策略由5个子策略组成,每个子策略依次应用2个图像操作,每个图像操作都有两个参数:应用它的概率和操作的幅值(70%的概率执行旋转30度的操作)
这种策略在训练时是如何应用在图片上的呢?对于我们当前批次的每张图片,首先随机均匀地选择一个子策略,然后应用该子策略。让我们来看一个包含5个子策略的示例,这些子策略应用于SVHN数据集中的图片:

对SVHN图像应用一些最佳增强的例子。
源自:https://arxiv.org/abs/1805.09501v1
子策略1在x的方向上,以90%的概率执行力度为7的剪裁。然后,有20%的概率,对图像的颜色进行翻转。子策略4以90%的概率对图像进行颜色反转,然后在10次中有6次进行颜色直方图均衡化。操作的次数是固定的,但是由于子策略的随机性和操作存在的概率,对于单个图像也可能有很多的增强结果。
让我们看看AutoAugment RL模型的搜索空间。他们考虑了16种操作:14种来自Python图像库PIL,比如旋转、颜色反转和一些不太知名的操作,比如色调分离(减少像素位)和过度曝光(将颜色反转到某个阈值以上),再加上裁剪和采样(类似于Mixup)这些数据增强领域的新方法。增加11个离散概率值(0.0,0.1,…,1)和从0到9共10个等间距的幅值,这相当于对某一个子策略有(16 * 11 * 10)²种可能性,如果同时有五个子策略,则共有(16 * 11 * 10)¹⁰≈2.9 * 10³²种可能 。需要强化学习来帮忙了!
如何训练AutoAugment ?
AutoAugment像NASNet一样训练——一个源自Google的用于搜索最优图像分类模型结构的增强学习方法。它的训练方法如下:我们有一个控制器,它决定当前哪个增强策略看起来最好,并通过在特定数据集的一个子集上运行子实验来测试该策略的泛化能力。在子实验完成后,采用策略梯度法(Proximal policy Optimization algorithm, PPO),以验证集的准确度作为更新信号对控制器进行更新。解释PPO超出了本文的范围,但是我们可以更详细地看看控制器和子模型实验。
控制器(controller)
控制器以Softmax输出要应用于哪个操作决策。然后,该决策作为输入传递到控制器的下一步,这是因为控制器是一个RNN(对于NASNet,使用了一个包含100个隐藏单元的LSTM)。然后控制器决定应用哪个幅值的操作。第三步是选择概率。因此,控制器拥有所有其他操作的上下文、早期的概率和幅值,以便做出最佳的下一个选择。(这是一个说明性的例子,因为这篇论文目前并没有告诉我们选择操作、大小和概率的顺序)。
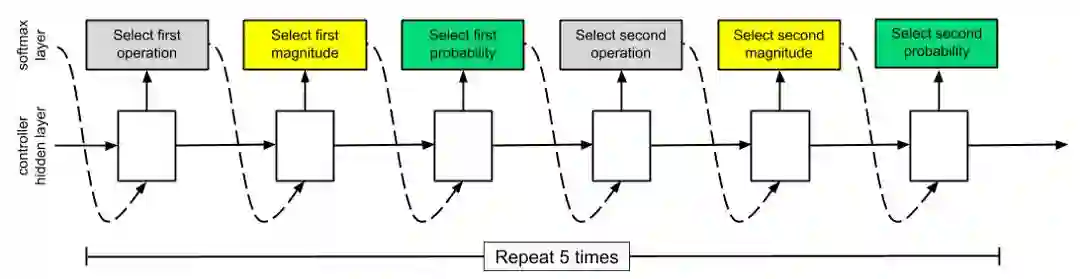
控制器模型架构 源自:https://arxiv.org/abs/1707.07012
总共有30个softmax预测值,因为有5个子策略,每个子策略需要在两个操作、大小和概率(5 * 2 * 3 = 30)中做出两个选择。
子模型(child model)
我们如何告诉控制器哪些策略选择得好,哪些没有真正提高性能(例如将亮度设为零)?为此,我们使用当前增强策略在子神经网络上进行泛化实验。实验结束后,对RNN控制器的权值进行更新,以验证集的准确度作为更新信号。当最后将整体最佳的5个策略(每个策略包含5个子策略)合并到最终策略(现在包含25个子策略)中时,共将执行15,000次迭代。最后的这个策略是用于该数据集所有数据的策略。
实验结果
正如副标题已经给出的那样,AutoAugment提升了CIFAR-10、CIFAR-100、SVHN、ImageNet等数据集上的最优结果。此外,还有一些特别有趣的细节:
CIFAR-10和ImageNet数据集上的最佳策略主要是基于颜色的转换。对于SVHN数据集,与CIFAR-10相比,AutoAugment选择了完全不同的转换:剪切图像和反转颜色,这对于门牌号是很有意义的。
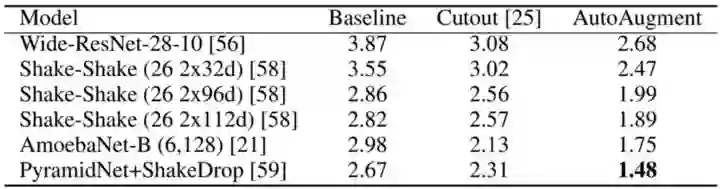
CIFAR-10测试集上的错误率,越低越好,
源自:https://arxiv.org/abs/1805.09501v1

ImageNet验证集上Top-1/Top-5的错误率,越低越好,
源自:https://arxiv.org/abs/1805.09501v1
在数据很少的情况下,使用autoaugmented的效果会更好。这是数据增强技术的预期效果。
在CIFAR-10上发现的最佳增强策略可以将CIFAR-100的错误率从12.19%提高到10.67%。

CIFAR-100测试集的错误率,
源自:https://arxiv.org/abs/1805.09501v1
将ImageNet上的最终策略应用在5个不同的较难的数据集,可以显著提高最终的准确度。这是通过数据增强而不是权值的迁移学习得到的结果。这些结果是从零开始训练Inception v4,而不是从ImageNet微调权重时得到的。

FGVC测试集上Top-1错误率(%)。Inception v4是从零开始训练,没有应用最佳ImageNet增强策略。源自:https://arxiv.org/abs/1805.09501v1
两个迁移学习
如果我们想要解决图像分类问题,通常使用来自ImageNet预训练的权重初始化模型,然后对这些权重进行微调。我们刚刚看到,使用AutoAugment的最佳ImageNet策略,同时从零开始训练,也有类似的正效果。如果我们同时使用这两种方法:在使用ImageNet AutoAugment 策略时微调ImageNet的权重?这些优化的效果会叠加起来,为我们解决新的图像分类问题提供新的最佳方法吗?
为了回答这个问题,我使用了相同的5个FGVC数据集(Oxford 102 Flowers, Caltech-101, Oxford- iiit Pets, FGVC Aircraft和Stanford Cars),对Inception v4进行微调,使用或不使用来自AutoAugment的ImageNet策略。
实验设置:
在GPU上以batch size为32训练一个Inception v4网络,SGD的momentum设为0.9,学习率设为0.01。
如果验证集的准确度在5个epoch内没有增加,则学习率减半。如果验证集上的准确度在3*5=15个周期内没有提高,就停止训练。
使用这个repo中预训练的ImageNet权值,只有最后的输出层被替换来表示数据集的不同类。从一开始,所有层都是可训练的。
如AutoAugment论文中所写的那样,输入图像的尺寸为448x448。
两种微调场景都使用随机水平翻转和随机大小裁剪作为基础数据增强。选择随机调整大小的最小剪切百分比,基于小的ResNet18验证集的效果而定。
ImageNet 的AutoAugment策略是在随机裁剪大小后施加。不过实验表明,在剪切前还是剪切后施加都无关紧要。
选择这些超参数后,最终的模型在训练集和验证集的组合上进行训练,并在测试集中进行测试。为了保证测试结果的稳定性,采用该方法训练了5个模型,并对测试结果进行平均。
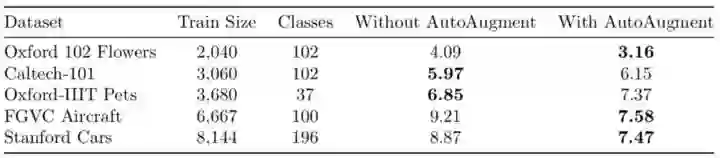
对FGVC测试集上5次Top-1错误率结果进行平均。Inception v4通过对ImageNet权重进行微调,使用和不使用AutoAugment ImageNet策略。有趣的是,在5个数据集中,只有3个数据集的微调结果比从上面AutoAugment论文中从零开始训练的结果更好。正如在“Do Better ImageNet Models Transfer Better”中讨论的那样,微调似乎不会在所有情况下都提升模型性能。 https://arxiv.org/abs/1805.08974
将最佳的ImageNet增强策略应用于不同的数据集,可以将5个数据集中的3个的错误率平均降低18.7%。在另外两个数据集上,错误率平均增加了5.3%。
这些结果表明,当需要对ImageNet权重进行微调时,应该尝试额外应用ImageNet AutoAugment策略。通常情况下,基本上都可以额外获得显著的改进。
如何将AutoAugment策略应用于您的问题
我在本文附录中创建了一个包含最佳ImageNet、CIFAR-10和SVHN策略的repo。一些实现细节还不明确,但我正在与作者联系,一旦我知道更多细节,我将会在这个repo里及时更新。
将ImageNet策略的随机子策略通过PIL应用搭配图像上,可以如下:
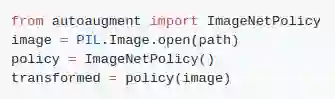
要将它应用到PyTorch,您可以这样做:

结论
AutoML再次展现:对于给定数据集,最好的数据增强操作是可学习的,甚至可以迁移到类似的数据集中。这只是许多可能的自动优化数据增强方法中的一个。提高学习此类策略的效率是另一种令人兴奋的方法,目的是使任何人都能够使用这些技术(无需使用GPU服务器群)。ENAS表明这是可行的。
把这个新方法应用到你自己的问题上吧,祝你好运!如有错误和疑问,请发邮件至philip@popien.net联系我。
感谢Avinash C Mishra和Tom Voltz。
想要继续查看该篇文章相关链接和参考文献?
点击底部【阅读原文】即可访问:
https://ai.yanxishe.com/page/TextTranslation/1649
附:上周 赠书福利 的中奖结果。恭喜以下几位朋友获得《MXNet深度学习实战:计算机视觉算法实现》一本。稍晚些时候会收到服务通知,敬请留意。
滑动查看更多内容




<< 滑动查看更多栏目 >>




