【全自动机器学习】ML 工程师屠龙利器,一键接收训练好的模型
1 新智元原创
作者:胡毅奇,南京大学 LAMDA 研究所
【新智元导读】机器学习系统有大量的超参数,在应用中需要依赖领域专家知识,并且有繁重的人工调参任务。现在,有一项工作希望让这些过程自动化,只需一个按钮,就能让你得到训练好的模型,这就是“自动机器学习”(autoML)。而自动机器学习的两大工具,Auto-weka 有可视化界面,只需轻点鼠标就能完成训练工作,auto-sklearn 也仅需数行代码便可构建可用的模型。操作如此简单,还不用担心训练后的模型不 work,是不是很值得上手试验一番?

某日出差,在出租上闲来无事和司机闲聊,告知其本人专业是人工智能,司机师傅顿时打开了话匣子:人工智能我知道,那个 AlphaGo 下围棋没有人能下得过它,吧啦吧啦吧啦......某次乘地铁,听见地铁上三五青年大谈深度神经网络。似乎一夜之间,机器学习飞入寻常百姓家,大有全民机器学习之势。
然而,若在街上拉住一位大爷说:我们来讨论一下 SVM 的机制吧,大爷必然挣脱开来大吼:不要耽误我买菜!机器学习算法纷繁复杂,No free lunch 理论告诉我们,每一个模型都有其偏好,对待不同的学习任务,都需用不同的模型来解决。一个算法工程师可能需要多年的修炼,才能熟练掌握各个算法的特性,在处理问题时,仍然需要使用各种 tricks,花费大量时间去调整模型,以求达到最好的效果。
计算机科学工作者本着能让计算机干就不要人费劲的原则,自然不能忍受这种重复繁琐的劳动。因此,自动机器学习(Automatic Machine Learning, AutoML)应运而生,它能自动完成算法和超参的选择。对于机器学习工程师来说,AutoML 能将他们从重复劳动中解脱出来;对于机器学习菜鸟来说,再也不用担心所选的模型不 work、超参不收敛,所需要做的只是接收训练好的模型。
AutoML 如同倚天剑屠龙刀一般,使机器学习工程师功力大增,但这样一件利器在不久之前似乎知晓的人并不多,2017 年 5 月 18 日,谷歌开发者大会(I/O)以“学会学习”(learning to learn)为口号,才将 AutoML 推到更多人的视野中来。其实,自动调参的工作早在 20 世纪末 21 世纪初就已经出现,每年的机器学习和人工智能的各大顶会上也频繁出现 AutoML 的身影。自 2014 年起,每年来自德国弗莱堡大学的 ML4AAD(Machine Learning for Automatic Algorithm Design)小组,均会在机器学习顶级会议 ICML 上组织 AutoML 的 workshop,这是来自全球的 AutoML 工作者集中交流的舞台。近年,谷歌、MIT 等世界知名企业高校也纷纷发表文章,加入到此领域中。
既然 AutoML 发展了多年,也不能光打雷不下雨,AutoML 的产品早已上线,auto-weka[1](2013年)、auto-sklearn[2](2015年) 是其中的代表,这两个工具均是 ML4AAD 组的产品。此小组的 leader 是 Frank Hutter 博士,此人博士期间的研究方向即是 AutoML,但是大多成果均和自动超参选择有关,博士毕业后转战贝叶斯优化领域,为 SMAC 算法的主要作者,之后成功的将贝叶斯优化技术应用在 AutoML 领域,不断推出成熟的 AutoML 产品,可谓根正苗红。
本文就按时间为顺序,以成果为线索,分别对 auto-weka、auto-sklearn 这两大自动机器学习工具,以及谷歌大脑和 MIT 在今年 ICLR 上发表的工作进行介绍。其中,详细介绍 auto-weka、auto-sklearn 和谷歌大脑的工作,简略介绍 MIT 的工作。
贝叶斯优化是非梯度优化的代表,因为不需要知道梯度信息,也不需要优化问题,具有良好的数学性质,所以适用范围比梯度优化更加广泛,常常被用来求解复杂的优化问题。
贝叶斯优化与 autoML 的两大工具 auto-weka、auto-sklearn 有着密不可分的关系。机器学习能自动化的原因在于其算法过程遵循固定的步骤,一般来说为数据处理、特征选择、模型选择和超参优化。Auto-weka 和 auto-sklearn 中,便将机器学习过程归约成了算法选择和超参优化(Combined Algorithm Selection and Hyper-parameter optimization,CASH)问题。
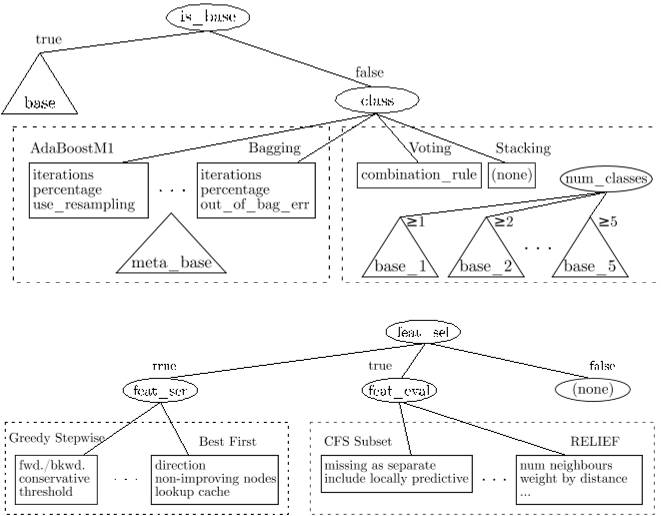
图1:auto-weka 算法选择树状图
CASH 用一个树形结构(如图1 所示)刻画机器学习中算法选择和超参设置的步骤,每一种算法的组合和超参的选择对应为一个采样,用 k 折交叉验证的错误率作为评价指标。SMAC 是基于随机森林的贝叶斯优化算法,结构和优化设置上均契合 CASH 问题,当仁不让的肩负起优化 CASH 的责任。SMAC 也出色地完成了这一任务,在ChaLearn AutoML challenge 竞赛中,auto-sklearn 分别获得了 auto 单元与 tweakathon tracks 单元的冠军。
Auto-weka 和 auto-sklearn 分别对应了 java 和 python 环境,两者的调用也十分简单,如图 2、3 所示。Auto-weka 有可视化界面,只需轻点鼠标就能完成训练工作,auto-sklearn 也仅需数行代码便可构建可用的模型。操作如此简单,还不用担心训练后的模型不 work,是不是很值得上手试验一番?
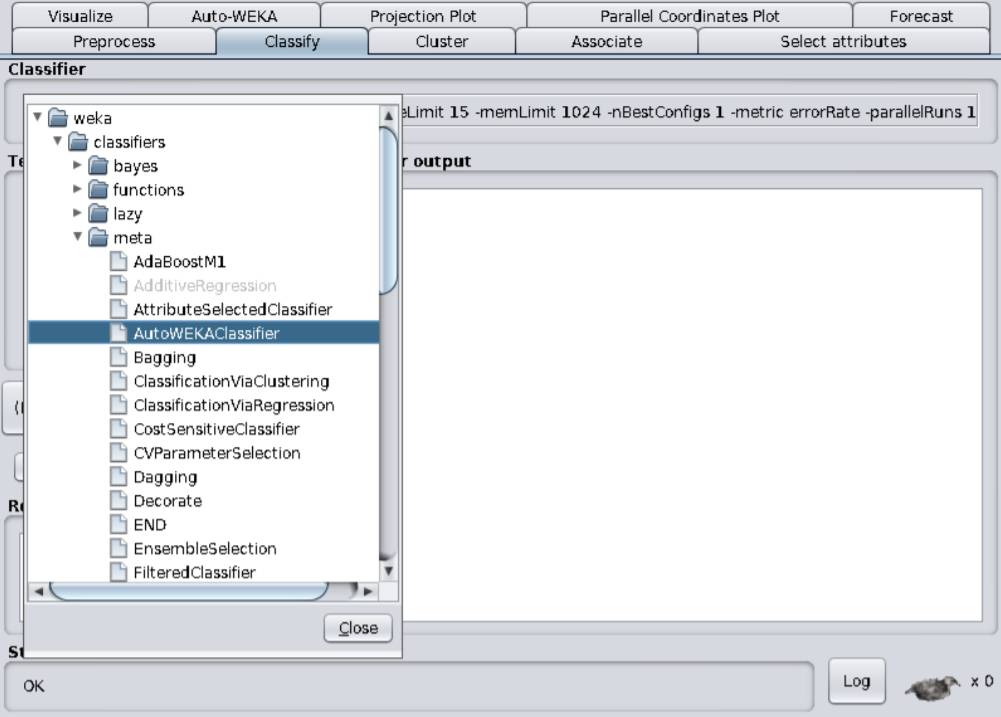
图2:auto-weka 可视化界面
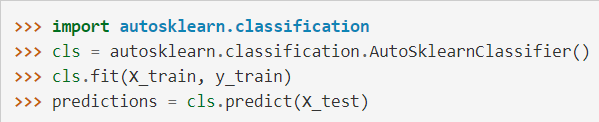
图3:auto-sklearn 调用代码
将 AutoML 归约成一个优化问题,然后用非梯度优化算法直接求解,是通向自动机器学习的一种思路。ICLR 2017上谷歌大脑的工作“Neural Architecture Search with Reinforcement Learning”[3]结合深度学习和强化学习,给我们提供了另外一种解决此问题的方法。
1. 谷歌大脑:用强化学习生成子网络
在谷歌大脑的工作中,待生成的神经网络被称为子网络,子网络中每一层的结构被看作是时间序列上某一个时刻的输出结果,这样一个 controller(用一个 RNN 网络来表示),就可以用来生成子网络每一层上的结构(图4 所示),子网络训练后在验证集上的准确率作为该子网络的评价。
于是,问题就转化为优化 controller 的权重,使其能生成子网络的准确率尽可能大。但是,优化 controller 权重时梯度无法直接获得,此时需要借助强化学习方法获得梯度。如果将 controller 对每一层的结构预测视为一个动作,这样准确率就可以视为一组动作之后的奖赏值,可用 REINFORCE 规则估计出 controller 的梯度,用于更新权重生成下一个子网络。
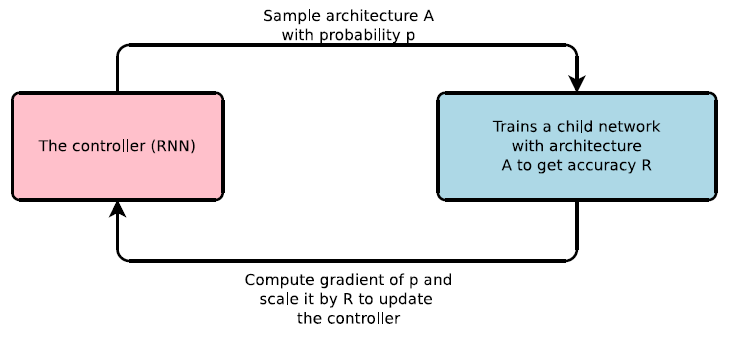
图4:controller 生成子网络示意图
值得注意的是,每个子网络训练的计算开销都十分巨大,此工作中采用了异步并行的方法加速子网络的训练,这样就大大增加了对计算资源的需求,在 CIFAR-10 上生成 CNN 结构的实验中,谷歌大脑便使用了 800 个 GPU 来完成训练工作。在实验中,此方法被用来自动生成 CNN、RNN 等网络结构,生成的网络泛化能力与人工设计的网络结构相当,但是规模要略小于人工网络,说明了方法的有效性。
同时,此方法在生成子网络时需要预先设定好网络的深度(controller 的步数),而且每一层中结构也是从预先给定的候选结构中选择,所以欠缺了生成网络的灵活度。
2. MIT:用 Q-learning 生成 CNN
无独有偶,同在 ICLR 2017 上 MIT 的研究者,在“Designing Neural Network Architectures using Reinforcement Learning” [4]中,也利用强化学习技术自动生成了 CNN 结构。
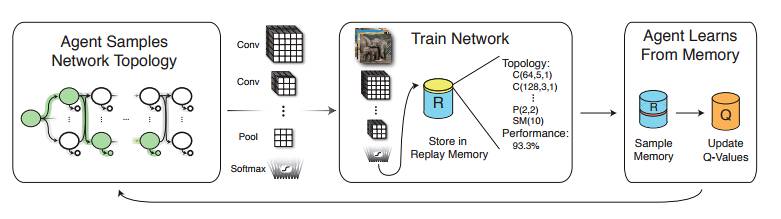
图5:用 Q-learning 生成 CNN 示意图
此工作也是通过逐层生成的方式得到网络结构,与谷歌大脑不同的是,在此工作中,将前一层的网络结构视为一个状态,将预测下一层的结构视为一个动作,将网络在验证数据集上的准确率视为奖赏值,用 Q-learning 的方法不断完善 Q 函数,最终给出验证正确率高的动作预测,生成泛化性能好的网络结构。
诸如 Auto-sklearn 的工具数年前就已经问世,但却没有被机器学习科学家广泛使用,其中一个原因是,模型的好坏很大程度取决于训练模型之前对数据的清洗工作。正如 Keras 之父 Francois Chollet 所说:“数据清洗工作很难自动进行,它通常需要专业领域的知识以及对工程师想要实现的工作有明确且高度的理解。”
因此,即使在算法和超参选择上做得足够出色,AutoML 工具得到的还仅是一个好的模型,并非足够好的模型。自然,这样的结果是不能令精益求精的机器学习科学家满意的。深度网络的出现改变了这一现象,谷歌大脑在其 ICLR 2017 论文中指出:“深度网络已经成功将机器学习范式从特征设计转向网络结构设计。”
摆脱了数据清洗的困扰,AutoML 似乎能在其擅长的结构搜索上挣脱束缚,大放异彩。其实不然,AutoML 的搜索依赖于对网络结构或算法组合的评价,当前的大部分工作中均将 k 折交叉验证错误率作为评价准则,结构和算法稍作改变均要重新训练,时间和计算开销十分巨大,导致搜索不够彻底,也会影响 AutoML 的效果,以至于谷歌大脑在其工作中“大动干戈”,使用了 800 个 GPU 完成加速模型训练工作。如何在模型发生变化时消除计算冗余,高效地得到模型的评价指标,也是 AutoML 亟待解决的问题。
AutoML目前面临诸多困难,但是随着 GPU 的大规模使用,新一代计算设备 TPU 的出现,硬件性能大幅增长,在技术上,深度学习的成熟和强化学习的发展也为 AutoML 注入了新活力。
让机器学会学习才是 AutoML 的终极目标,每向此目标靠近一步,均是机器学习技术的突破。一旦困难得以解决,AutoML 的实现将解放广大机器学习工程师的劳动力,大幅降低机器学习的门槛。但是如 Francois Chollet 所说,“机器学习工程师的工作不会消失,相反,工程师将在价值链上走高”,这也是 AutoML 魅力所在,它体现了机器学习工程师的价值,这点也吸引着工程师们为之不断奋斗。
【南京大学副教授俞扬专访】AutoML 全自动机器学习
为了更好地理解“自动机器学习”(AutoML),新智元特地采访了南京大学计算机科学与技术系副教授俞扬博士。
俞扬博士主要研究领域为人工智能、机器学习、演化计算、数据挖掘。发表论文 40 余篇,包括多篇 Artificial Intelligence、IJCAI、AAAI、NIPS、KDD等人工智能、机器学习和数据挖掘国际顶级期刊和顶级会议论文,研究成果获得IDEAL'16 Best Paper、KDD'12 Best Poster、GECCO'11 Best Theory Paper、PAKDD'08 Best Paper、PAKDD’06 数据挖掘竞赛冠军等论文和竞赛奖。获 2017 年江苏省计算机学会青年科技奖。
俞扬博士共同发起并主办了亚洲强化学习系列研讨会(AWRL)、中国演化计算与学习系列研讨会(ECOLE)。由于非梯度优化在自动机器学习中所起到的关键作用,自动机器学习也是他近来的研究兴趣点之一。
1. 新智元:有好几个概念都提到了“学会学习”(learning to learn),除了自动机器学习(autoML),还有“元学习”(meta-learning)、“终身机器学习”(lifelong machine learning)。AutoML 和终身机器学习、元学习之间的关系是什么呢?
俞扬:经典机器学习主要考虑对给定的数据集进行学习。这几个概念都表达了对机器学习系统更智能更有效的期望,不仅可以学习一个给定的数据集,还能跨环境,更好地处理不同的学习任务。“元学习”(Meta-learning)是源自教育心理学的一个词,原本表示对于个人学习行为的控制。在机器学习领域,早在 1976 年左右,J. Rice 关于算法选择的研究就引入了元学习概念,上世纪 90 年代兴起了一批元学习研究工作,例如 Giraud-Carrier 认为,元学习是关于理解学习机制与具体的学习上下文的交互关系。可以看出,元学习中学习分为两层,上层抽取和学习“元知识”,并指导下层在具体环境中的学习。元学习是一个定义很宽泛的领域,“learning to learn” 则是元学习的通俗易懂的说法,例如 C. Finn 最近介绍 learning to learn 的博客中就是在回顾元学习。
终身机器学习则更关注机器处于与人相似的环境中,即面临一个又一个的学习任务,例如 UCI 的刘兵(B. Liu)教授在终身学习 tutorial 中介绍,终身机器学习保留以往结果、抽象知识、并用来帮助未来的学习和问题求解。在 AAAI 终身机器学习研讨会中,列举了的主要任务包括发现数据的高层表达、知识迁移、知识库维护,以及结合外来指导信息等。
自动机器学习最近得到了越来越多的关注。从科学问题上看,自动机器学习属于元学习,然而自动机器学习更多是受到来自应用需求的驱动:机器学习系统有大量的超参数,在应用中需要依赖领域专家知识,并且有繁重的人工调参工作。自动机器学习则希望将这些繁重的工作自动完成,例如 Auto-Weka 项目,仅提供了一个“自动学习”按钮,实现“一键学习”。
2. 新智元:机器学习在多大程度上可以自动?全自动机器学习实现后的人机交互会是怎样的?
俞扬:一个机器学习系统可能包含数据预处理、特征抽取、模型学习等环节,每一个环节都有多种算法可以选择,每一种算法又有多种超参数可以调节,模型学习算法还存在递归嵌套的可能。自动机器学习在所有可能中寻找一个较好的算法组合及其超参数,面临巨大且复杂的搜索空间。同时,对于每种算法组合和超参数选择的评价,通常需要完成一次学习过程,花费的时间和计算成本极高,因此自动机器学习还面临评价代价高昂的困难。另外,巨大的算法配置空间增加了数据过拟合风险,对准确评价一种配置的泛化能力(即真实的预测精度)造成困难。
总的来说,自动机器学习面临空间巨大、评价昂贵、测试不准等困难,目前还难以做到理想的全自动。在已有的自动机器学习工具中,对搜索空间进行了限制,使得在较小的空间中可以对不太大的数据进行自动算法和超参数选择。全自动机器学习实现后,人机交互会非常简单,就如同 Auto-Weka 已经展示出来的一样,用户只要输入数据,然后“一键学习”,等待学习结果。
3. 新智元:您预计自动机器学习领域未来 3 到 5 年会得到怎样的发展?
俞扬:如果能更好的处理空间巨大、评价昂贵、测试不准等困难,可以预见自动机器学习将获得更强的性能。目前已经可以看到针对每一个问题有一些新的技术发展,例如自动机器学习主要依赖非梯度优化,非梯度优化方法近年在理论和效率上都得到了提高。未来 3 到 5 年,随着技术和计算设备的升级,对于较小的常见类型数据,自动机器学习有望能取得超过人工配置的学习效果。
参考文献:
Thornton C, Hutter F, Hoos H H, et al. 2013. Auto-WEKA: Combined selection and hyperparameter optimization of classification algorithms. In Proceedings of the 19th ACM SIGKDD international conference on Knowledge discovery and data mining, 847-855.
Feurer M, Klein A, Eggensperger K, et al. 2015. Efficient and robust automated machine learning. In Advances in Neural Information Processing Systems, 2962-2970.
Zoph B, Le Q V. 2016. Neural architecture search with reinforcement learning. arXiv preprint, 1611.01578.
Baker B, Gupta O, Naik N, et al. 2016. Designing neural network architectures using reinforcement learning. arXiv preprint, 1611.02167.
附录:
ML4AAD AutoML链接:http://www.ml4aad.org/
Auto-weka链接:http://www.cs.ubc.ca/labs/beta/Projects/autoweka/
Auto-sklearn链接:http://www.cs.ubc.ca/labs/beta/Projects/autoweka/
【号外】新智元正在进行新一轮招聘,飞往智能宇宙的最美飞船,还有N个座位
点击阅读原文可查看职位详情,期待你的加入~


