Azure如何利用机器学习“预知”虚拟机故障?

编者按:云服务的一大优势,是使用户无需担心如何管理硬件资源和处理硬件故障。然而,如果云服务发生了硬件故障,该怎么办?现在,得益于微软亚洲研究院最新磁盘故障预测和节点故障预测的研究成果(论文见文末),Azure能够“预知”云服务中的硬盘故障,提前发出警示,并进行用户可控制的自动迁移流程,最大程度地减少硬件故障的影响。
对于运行虚拟机的云服务器来说,硬件故障是一个无法回避的问题。除了硬盘故障,超时、容积大小、分区和延迟错误,都可能带来文件操作失败、虚拟机未响应等问题,导致云服务出现中断。
而现在,Azure可以“预知”硬件故障的发生,并在维护和更新前,对虚拟机进行可控的自动实时迁移,使因故障发生导致的停用时间大大缩减,每月可减少约1000小时的停用时间。
故障预测的难点在于,发生故障的设备越少,故障预测就越困难,因为每一台设备发生故障的概率都很低,是小概率事件。而且过多的误报会使未出现故障的硬件也被停用,从而增加Azure的运营成本。因此,对生产环境中的预测性能有更高的要求。
Azure通过机器学习来预测硬盘和整个集群节点发生故障的可能性,目前可预测的故障包括驱动器故障、I / O延迟问题、内存故障和CPU频率问题。
Azure云硬盘错误预测系统(Cloud Disk Error Forecasting System),综合使用标准硬盘SMART监控数据和系统级事件数据,采用机器学习算法训练预测模型来预测硬盘故障。
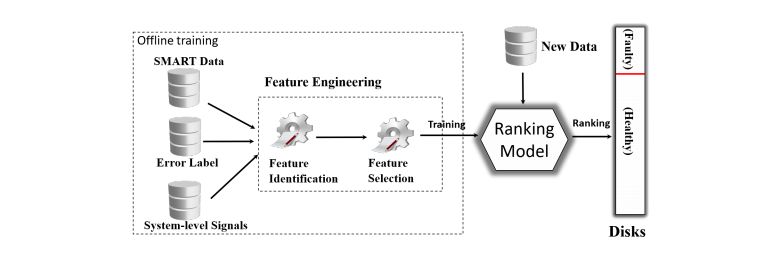
Azure云硬盘错误预测系统框架
约有450种不同的数据可能与硬盘故障相关,但不是所有数据都能帮助Azure进行错误预测,比如,通电时间(Power-On Hours)对预测的帮助相对较小,但重新分配的分区数量(Reallocated sectors count)不断增加,就表明硬盘有故障。一般来说,在硬盘故障前的15-16天,硬盘错误就开始出现,并且一般在故障前的最后一周,重新分配的分区数量会增加三倍,设备重置次数会增加十倍。
来自不同制造商的硬盘可能有不同的故障特征和模式,甚至同一制造商的不同型号的硬盘也会有所差异。另一方面的差异来自工作负载的强度,这会影响到故障在预测后多快的时间里发生,比如在高强度的工作负载下,出现故障迹象的磁盘可能很快就会发生故障,但在硬盘驱动的工作负载较少的服务器中,同样的硬盘可能仍然可以继续运转几周到几个月。因此,机器学习的训练数据系统必须从不同类型的任务中采集。
除了云硬盘错误预测系统,一个类似的机器学习系统能为Azure预测计算节点的故障。两个系统采取的预警方式都是按硬件故障的可能性大小从高到低进行排序,而不是直接判定某个硬件是否会发生故障。这也更符合实际生产环境中故障处理的需要。Azure会停止将新的虚拟机部署在故障可能性最高的系统上,并自动选择最佳节点对正在运行的虚拟机进行实时迁移,随后停止服务,进行检测。
Azure将在不影响工作负载的情况下进行实时迁移,在几分钟内将包括内存、磁盘状态、网络连接等在内的整个虚拟机复制到新节点,根据迁移信息量的不同,耗时1-30分钟不等。完成后,原始节点和新节点上的虚拟机将同时挂起(suspended),实时迁移代理会将任何尚未传送的状态信息复制过去。停用状态也取决于迁移的信息量,通常只持续几秒钟。
如果一些工作负载对性能的要求很高,复制过程可能依然会对它产生一些影响。比如,有些应用程序连几秒的暂停也无法允许,有些应用程序则无法进行实时迁移,比如HPC、内存优化、GPU优化和存储优化等特殊的专用机型,或是早期Azure上部署的A系列虚拟机。你可能要进行重新设置(refactor),并用PaaS服务而非虚拟机来处理这部分工作。
在这种情况下,Scheduled Events服务将为用户提供通知,警告硬件可能出现故障,虚拟机将被实时迁移或进行维护。如果用户使用了比较便宜的低优先级虚拟机,而它将被替换为更高优先级的虚拟机,Scheduled Events也会发出警告。
Scheduled Events将对虚拟机暂停、重新部署、由于低优先级被删除、自行设定的重新启动发出通知。如果虚拟机重新部署,它将至少提前10分钟发出警告,如果虚拟机暂停并重新启动,则至少提前15分钟。而如果是由于故障预测引发的实时迁移和重新部署,Scheduled Events将提前几天发送通知,同时服务将尝试以各种方式延迟故障。
举个例子,预测系统发现一个硬盘的故障概率很高,并且将破坏在该节点上运行的5台虚拟机。Azure在做出预测11分钟后就启动了实时迁移,让这5台虚拟机的停用时间控制在0.1-1.6秒之间。随后,Azure团队停止了该节点的服务并进行检测,在压力测试中,磁盘在第一次预警的4小时21分钟后发生了故障。
Scheduled Event的通知内容将包括预测到故障的时间,以及暂不迁移虚拟机的时间段(假设硬件在此期间不会发生故障)。如果Azure检测到更多来自该节点的异常信号,将会通知可能的暂停、实时迁移等信息。
在收到故障预测后,用户将有足够的时间做出反应,包括检查虚拟机是否可恢复、移除连接、转移故障、将其从负载平衡器池中剔除,或者做好关闭工作负载的准备工作。在完成准备后,用户可以在Scheduled Event中批准实时迁移,Azure将尽快进行迁移,帮助用户摆脱性能下降的硬件。即使无法调整虚拟机,也可以通过Scheduled Event安排快照,或减少虚拟机上运行的任务,从而最大程度地免受硬件故障的影响。
相关论文
1.Improving Service Availability of Cloud Systems by Predicting Disk Error. Yong Xu, Kaixin Sui, Randolph Yao, Hongyu Zhang, Qingwei Lin, Yingnong Dang, Peng Li, Keceng Jiang, Wenchi Zhang, Jian-Guang Lou, Murali Chintalapati, Dongmei Zhang USENIX ATC 2018 | July 2018

长按扫码,查看论文
2.Predicting Node Failure in Cloud Service Systems. Qingwei Lin, Ken Hsieh, Yingnong Dang, Hongyu Zhang, Kaixin Sui, Yong Xu, Jian-Guang Lou, Chenggang Li, Youjiang Wu, Randolph Yao, Murali Chintalapati, Dongmei Zhang ESEC/FSE 2018 | November 2018

长按扫码,查看论文
你也许还想看:



感谢你关注“微软研究院AI头条”,我们期待你的留言和投稿,共建交流平台。来稿请寄:msraai@microsoft.com。





