阿里定向广告新一代主模型:基于搜索的超长用户行为建模范式
机器之心编辑部
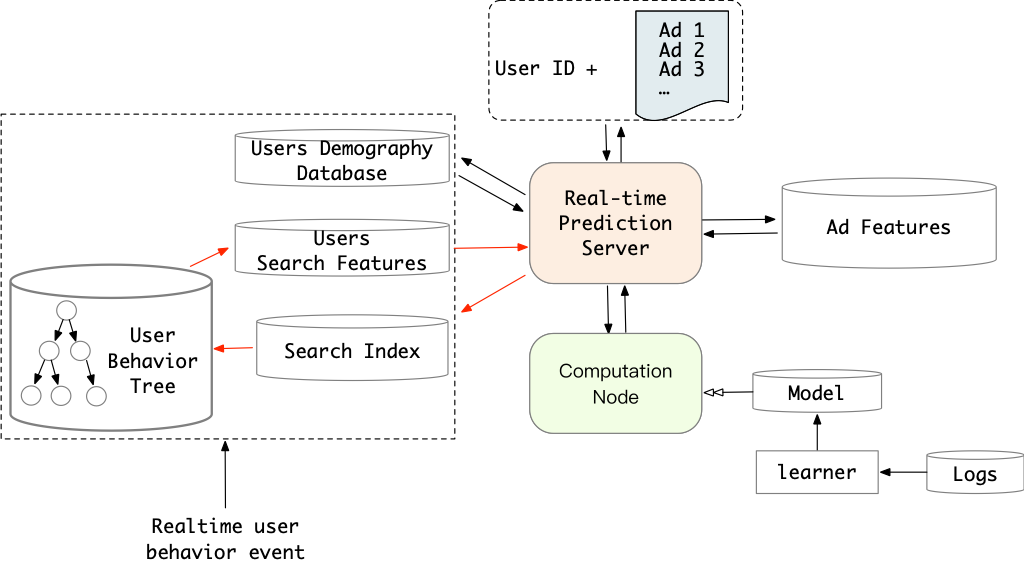
阿里提出并实现了一套基于搜索范式的超长用户行为建模新方法Search-based user Interest Model(SIM),用于解决工业级应用大规模的用户行为建模的挑战。



短期的行为不能代表用户,基于此的建模让用户很容易被近期热点和大多数所代表。
基于短期行为的算法无法建模用户长期以来坚持的兴趣,如品质、风格方面长期才能反映的喜好。
推荐系统大多数都是 data-driven 的,本就会形成数据闭环,而基于短期行为的推荐系统,可能会将自己的 “视野” 局限在一个非常窄的范围内。
动态数据分布捕获问题. 和一些静态数据研究问题不一样,工业界推荐系统要处理的问题并不是在一个固定的数据上去拟合一个确定的 ground truth。真实世界的系统中,CTR 预估面对的数据分布是在变化的,我们需要不停地根据最新的数据来更新模型的参数,让模型能适应近期数据的分布。这个需求和 encode 的思路存在天然的冲突。对行为序列的 encode 依赖哪个版本的参数?参数更新后需不需要去重新对行为序列进行 encode?
信息遗忘问题. 如果模型拟合的目标是当前样本,对当前样本有效的 encode 信息,这个 encode 结果并不一定对未来的样本有效,如何让模型能找到对用户 life-long 的行为序列进行 encode 并长期持续有效的方法?
建模噪声问题. 受限于实际系统使用,encode 的空间复杂度是有限的,源于问题 1 和问题 2,又会有新的问题,我们怎么在有限的 encode 空间内去建模用户 life-long 的行为序列,表达用户多个方面的兴趣。将用户的行为序列 encode 为一个固定的向量(或者矩阵,可以展开为向量),这个用户向量的表达能力是随向量的维度增加的。同时其空间复杂度以及后续的计算复杂度也几乎和向量维度线性相关。也就意味着这是一个表达能力受限的方法。
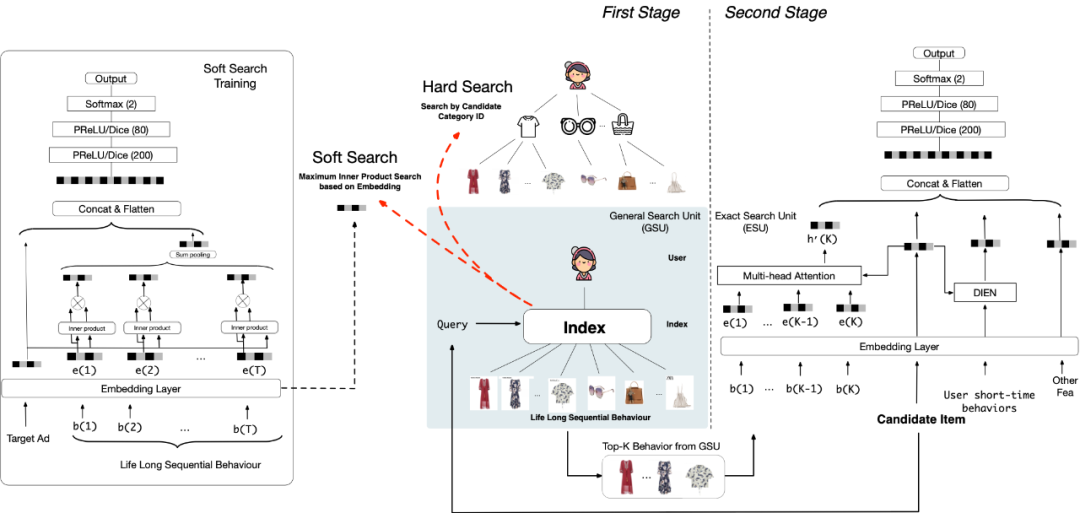
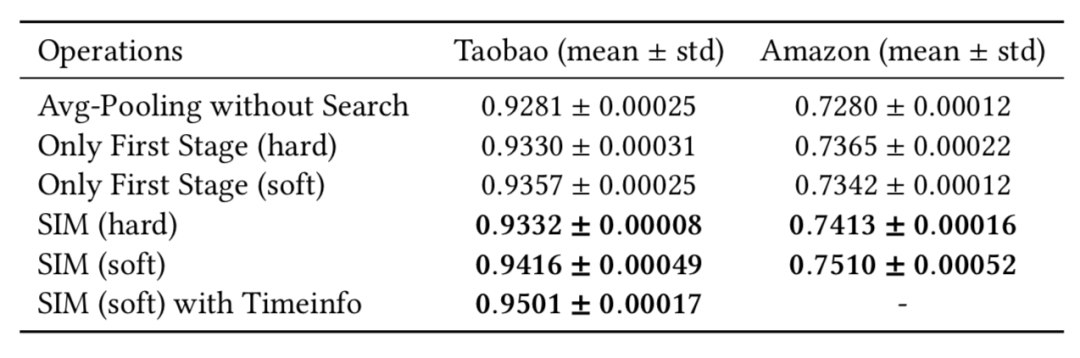
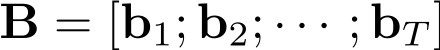 ,其中 b_i 代表了用户第 i 个行为,T 代表了行为长度。GSU 对于每一个用户行为计算一个相关性分数 r_i 。然后根据 r_i 从原始行为中选出 Top-K 相关的行为然后生成一个新的子序列
,其中 b_i 代表了用户第 i 个行为,T 代表了行为长度。GSU 对于每一个用户行为计算一个相关性分数 r_i 。然后根据 r_i 从原始行为中选出 Top-K 相关的行为然后生成一个新的子序列
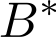 。r_i 的计算方式如下
。r_i 的计算方式如下
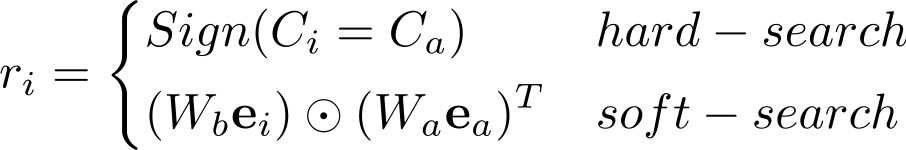
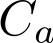 代表了候选广告类目,
代表了候选广告类目,
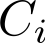 代表了第 i 个用户行为的类目。虽然 hard-search 是一种基于数据特性的一种比较直观的方案,但是它非常容易部署到实际工业界在线预估系统。在 Soft-search 中,我们将用户序列B
行为映射成为 embedding 表达
代表了第 i 个用户行为的类目。虽然 hard-search 是一种基于数据特性的一种比较直观的方案,但是它非常容易部署到实际工业界在线预估系统。在 Soft-search 中,我们将用户序列B
行为映射成为 embedding 表达
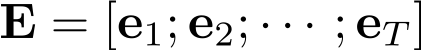 。W_b和W_a都是模型参数。其中e_a代表了候选广告 embedding,e_i代表了第 i 个用户行为 embedding。然后我们采用向量检索的方式来筛选出 top-K 和广告相关的用户行为。
作为输入。我们考虑到我们引入的是超长的用户行为序列,用户行为间横跨较长的时间。因此我们将每个用户行为引入了一个时间状态属性。我们引入用户行为时间和当前预估广告时间差
。W_b和W_a都是模型参数。其中e_a代表了候选广告 embedding,e_i代表了第 i 个用户行为 embedding。然后我们采用向量检索的方式来筛选出 top-K 和广告相关的用户行为。
作为输入。我们考虑到我们引入的是超长的用户行为序列,用户行为间横跨较长的时间。因此我们将每个用户行为引入了一个时间状态属性。我们引入用户行为时间和当前预估广告时间差
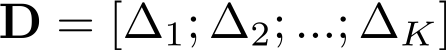 来表达每个行为的时间状态属性。最后我们利用一个 multi-head attention 结构来捕捉用户在广告上的动态的用户兴趣。其中第一阶段和第二阶段是采用交叉熵 loss 联合学习。Loss 函数如下:
来表达每个行为的时间状态属性。最后我们利用一个 multi-head attention 结构来捕捉用户在广告上的动态的用户兴趣。其中第一阶段和第二阶段是采用交叉熵 loss 联合学习。Loss 函数如下:
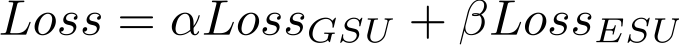
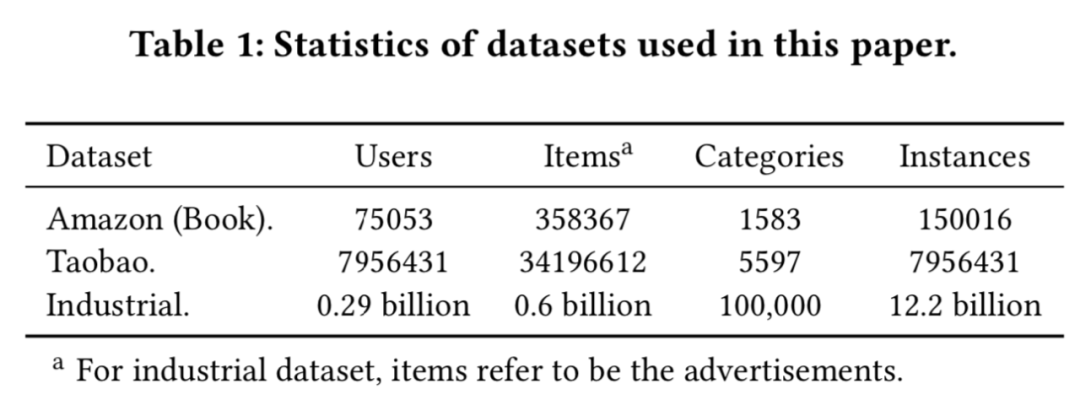
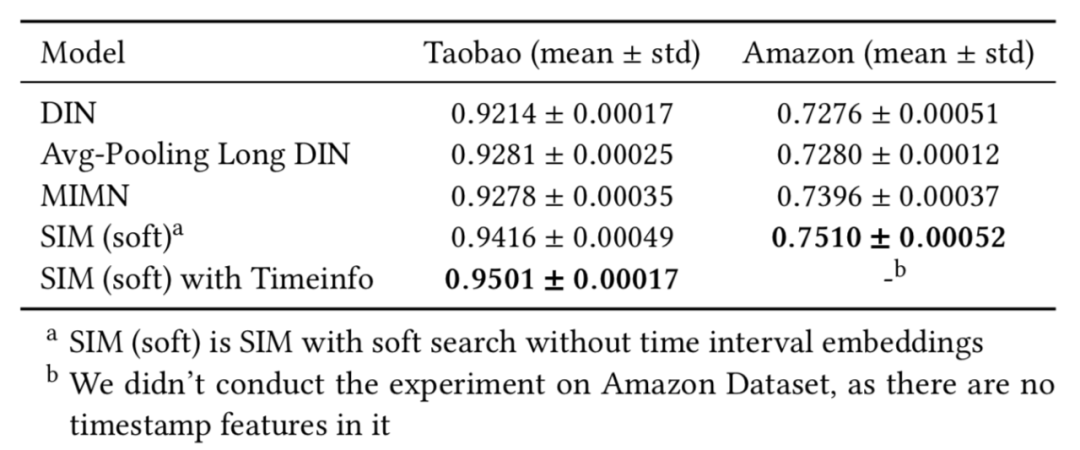
DIN:是我们早期的建模用户短期兴趣的模型。
Avg-Pooling Long DIN: 为了能分析长序列数据带来的价值,我们将长序列 avg pooling 处理后和 DIN 其他特征 concat 一起进行建模。
MIMN 是我们之前提出基于 memory-base 的长序列用户行为建模方法。
SIM(hard)是 GSU 采用 hard-search 的 SIM 方案。
SIM(soft)是 GSU 采用 soft-search 的 SIM 方案。
SIM(soft/hrad) with Timeinfo 是引入时间间隔属性的 SIM 方案。