存量运营好工具:客户稳定度评分卡模型


导读
本文主要是介绍基于逻辑回归算法的稳定度评分模型实现流程,所选案例也详细展示了模型构建的整个流程及处理方法。

来源:原力大数据 丨作者:黄广山
数据猿官网 | www.datayuan.cn

今日头条丨一点资讯丨腾讯丨搜狐丨网易丨凤凰丨阿里UC大鱼丨新浪微博丨新浪看点丨百度百家丨博客中国丨趣头条丨腾讯云·云+社区

存量运营是企业针对现有客户,以提升 客户忠诚度,释放客户价值为目的的一系列经营方针和策略,是在当前人口红利和流量红利消失的情况下,企业十分重视的板块。本文将介绍其中一种策略——客户稳定度评分体系构建。
客户稳定度评分模型 是评分卡模型的一种,本质上是一种有监督的机器学习模型,是一种以分数衡量流失几率的一种手段,用来预测客户在未来一段时间流失的概率。
通过对客户的稳定度进行评分,可以对客户进行 分群,并针对不同稳定度的群体制定相应的营销维稳策略,为企业实现精细化运营提供决策依据。
评分卡模型在信贷管理领域广为人知,除此之外,它还被广泛的应用在市场营销、客户关系管理、账户管理等场景。下文将以我们原力大数据为运营商搭建的客户稳定度评分模型为例,介绍整个模型和应用实现过程。
准备工具
Python2.7编程环境,sklearn算法库及其他科学计算库
实现流程
Step1 数据准备
(1) 定义目标变量
正样本:即 低稳定度客户,指的是以当月在网客户为基数,4个月后非正常在网的手机客户,标记为1。
负样本:即 中高稳定度客户,指的是以当月在网客户为基数,4个月后仍正常在网的手机客户,标记为0。
(2) 收集数据
以5月在网客户为基数,以9月底客户是否正常在网给不同客户打上标签,仍然正常在网标记为0,非正常在网标记为1。取正例5万、反例10万进行建模。取5月在网客户的4月、5月数据作为历史数据,以2个月时间窗作为观察期。
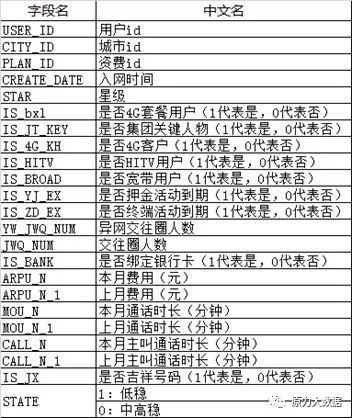
(3) 数据字段结果
取了以下23个字段数据,如表1 所示:
表1 字段解释
Step2 数据预处理
(1) 数据清洗
无效数据处理:删除无效字段、样例、缺失值,本次建模,共删除无效样例1.7万。
注意:资费ID字段是一个类别数超过2000的定性字段,容易过拟合,故删除;
数据转换:将入网时间字段转换为网龄(用NET_AGE字段表示,以月为单位),转换为机器可识别的类型;
缺失值处理:对定性特征(离散型特征)采用众数填充法,对定量特征(连续型特征)采用均值填充法,本例中,定量特征包括:NET_AGE 、YW_JWQ_NUM 、JWQ_NUM 、ARPU_N 、ARPU_N_1、MOU_N 、CALL_N 、CALL_N_1共计8个特征字段,其余特征字段均为定性特征;
(2) 定量变量筛选
定量特征筛选:通过相关系数法筛选定量特征,如表2 所示,表中为各数值特征与目标变量的相关系数,首先,删除与目标变量相关性低于0.3的特征:ARPU_N 、ARPU_N_1、YW_JWQ_NUM;
表2 特征字段及目标变量之间的相关系数矩阵
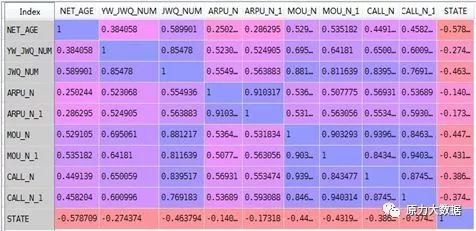
*字段说明:NET_AGE(网龄)、YM_JWQ_NUM(异网交往圈人数)、JWQ_NUM(交往圈人数)、APPU_N(本月费用)、APPU_N_1(上月费用)、MOU_N(本月通话时长)、MOU_N_1(上月通话时长)、CALL_N(本月主叫通话时长)、CALL_N_1(上月主叫通话时长)、STATE(1:低稳;0:中高稳)
共线性问题处理:共线性问题又称做多重线性问题,在应用逻辑回归模型时应尽量避免出现共线性问题,即特征之间出现强相关性(相关系数大于0.8)时只能保留一个特征。
可以看出MOU_N、MOU_N_1、CALL_N、CALL_N_1具有强相关性,删 .除CALL_N、CALL_N_1字段,合并MOU_N、MOU_N_1字段为 . MOU_AVG,表示本月及上月通话时长均值。
调整效果检测:经上述处理,得出调整后的相关系数矩阵,如表3所示。下表所示结果已经消除了共线性问题,并保留了与目标变量较为相关的特征字段。
表3 调整后的特征字段及目标变量之间的相关系数矩阵
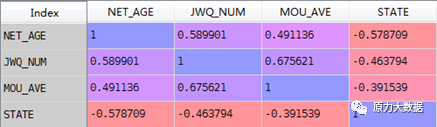
*字段说明:NET_AGE(网龄)、JWQ_NUM(交往圈人数)、MOU_AVE(本月和上月平均通话时长)、STATE(1:低稳;0:中高稳)
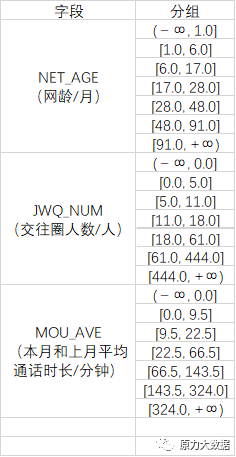
3) 定量变量分箱
离散化:构建稳定度评分模型时需要将定量变量(连续变量)进行离散化,本项目采用卡方分裂算法对筛选后的定量特征进行分箱处理,默认分为6组。
卡方分裂算法:卡方分裂算法是监督的、自底向上的(即基于合并的)数据离散化方法。它依赖于卡方检验:具有最小卡方值的相邻区间合并在一起,直到满足确定的停止准则;
其思想是对于精确的离散化,相对类频率在一个区
间内应当完全一致。如果两个相邻的区间具有非常类似的类分布,则这两个区间可以合并;否则,应当保持分开。而低卡方值表明它们具有相似的类分布。
定量变量分箱结果如表4:
表4 定量变量分箱结果
(4) 定性变量筛选
计算各个定性变量的IV值,删除小于0.1的变量:CITY_ID、IS_BXL、IS_BROAD、IS_JX、IS_YJ_EX共计5个字段;
(5) WOE转换
计算WOE值。
WOE:基于逻辑回归的评分卡模型一般需要先将所有变量进行WOE编码。它实际表示“当前分组中响应客户(标记为1的客户)占所有响应客户的比例”和“当前分组中没有响应的客户(标记为0的客户)占所有没有响应的客户的比例”的差异,WOE越大,差异越大。于逻辑回归的评分卡模型需要先将所有变量进行WOE编码。
WOE值如表5所示:
表5 WOE值计算结果
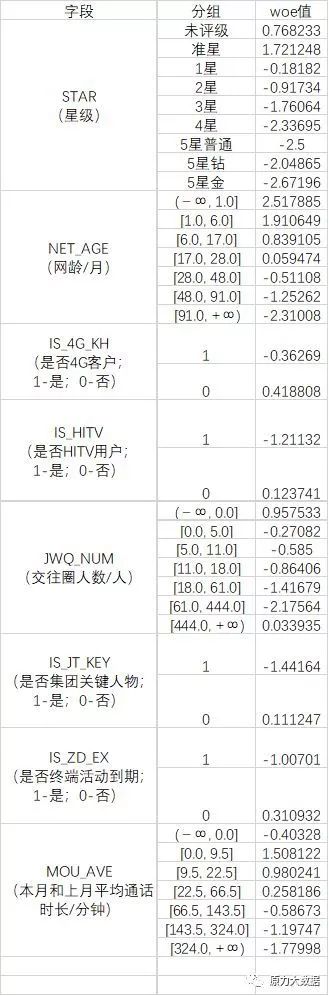
WOE其实描述了变量当前这个分组,对判断个体是否响应客户(流失客户)所起到的影响方向和大小。当WOE为正时,变量当前取值对判断个体是否会响应起到的正向的影响,反之亦然。WOE值大小,体现这个影响的大小。
如表中网龄NET_AGE字段,网龄小于28个月的分组WOE值都为正,表明网龄小于28个月的客户更有可能被判定为流失客户,网龄越小,WOE数值越大,表明可能性也越大。
6) 数据集划分
采用分层抽样,70%为训练集,30%为测试集。
Step3 模型训练
调用sklearn算法库中 逻辑回归算法,在已经预处理完毕的训练集上训练模型。
采用 网格搜索法,进行超参数调整,得到局部最优超参数;
储存拟合好的模型参数β0,β1,…,βn。
Step4 模型评估
评估分类模型在测试集上的表现,采用 AUC值 作为评估指标;
AUC(Area Under Curve)被定义为ROC曲线下与坐标轴围成的面积;其本质就是一个概率值。
结果:本次分类模型在测试集上测试的AUC值是 0.834,即Score值将正样本排在负样本前面的概率是 83.4%,模型效果较好。
Step5 生成客户稳定度评分表
通常,得分越高代表客户越稳定。在本项目中,将优比定义为 4:1(理论流失概率/理论正常概率),此时理论流失概率为80%,对应的分数定义为200分,双倍优比分数为50分,即用户得分每增加(或减少)50分,那么他的优比(理论流失概率/理论正常概率)将变成原来的0.5倍(或2倍)。
经过计算,本项目中的稳定度得分为:
Score = 300 –72.134*In(odds)
当odds等于1时,也就是理论流失概率等于50%时,Score = 300;
当odds等于0.5时,也就是理论流失概率等于33.3%时,Score = 350;
当odds等于0.25时,也就是理论流失概率等于20%时,Score = 400;
推荐当理论流失概率 ≥33.3% 时,即Score≤350 时,判定为低稳客户,当然,企业也可以根据需要自行根据客户的稳定度分数对客户进行分群。
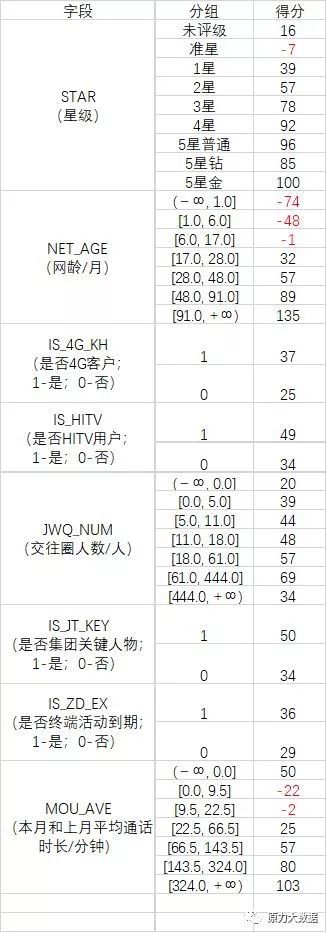
根据表5结果,把每个变量各个分组的woe值代入公式,可以计算得到最终的客户稳定度评分表,分数越高,代表客户越稳定;如下表所示:
表6 客户稳定度评分结果
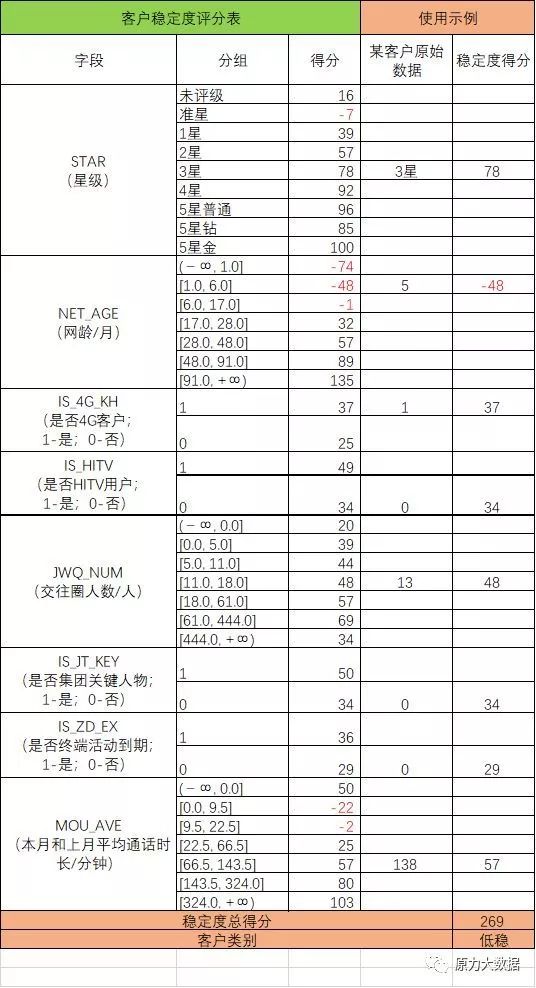
使上述评分表(表6)可对客户进行稳定度评分,通过该客户各个特征字段的得分加总,最终可得到客户的最终稳定度得分。如以下例子所示:
表7 客户稳定度评分应用示例
结语
本文主要是介绍基于逻辑回归算法的稳定度评分模型实现流程,所选案例也详细展示了模型构建的整个流程及处理方法。尽管模型表现良好,所选案例仍然存在以下不足之处:
(1) 选用数据维度稍显不足,可能会忽略掉一些对模型有较大影响的字段;
(2) 处理2个月数据时,为了消除共线性,只采用了简单的取均值方法处理,模型迭代时可以考虑采用更细致的特征工程方法,譬如,做差值,衍生出数据变化趋势字段;
考虑到数据的变化因素,稳定度评分体系构建之后应保持对模型效果的持续监控,当发现模型效果变差时,或者经过一定的时间周期后,需要使用最新的数据进行模型迭代,以保证模型的时效性、准确性。
本文作者
黄广山,原力大数据模型算法工程师。
原力大数据
原力大数据旨在为企业实现:管理、分析、激活企业大数据,发掘企业大数据金矿;洞察、连接、盘活企业存量客户,深度营销企业存量客户。
原力大数据专注于为企业提供基于大数据、云计算技术的数字化市场营销产品与服务,包括自主研发的原力MarTech(Marketing Technology营销技术)云平台、原力互联网商情云平台、企业大数据平台构建及软硬件集成、企业大数据平台规划咨询及相关专业服务。
原力MarTech云平台五大能力
1 企业自有大数据梳理、清洗、集成及建模,挖掘并积累高价值大数据资源;
2 全方位的企业经营分析可视化应用服务,涉及会员用户、营销渠道、营销商品、营销活动等;
3 用户行为数据分析,建立用户标签,提供千人千面的用户画像;
4 用户洞察、精准营销,提供针对用户的多渠道、全过程营销自动化能力;
5 营销效果实时数据分析评估,营销活动全过程持续迭代优化。