CVPR2020 | 大规模人脸表情识别(附源代码)
点击蓝字关注我们


扫码关注我们
公众号 : 计算机视觉战队
扫码回复:人脸表情,获取链接

今天我们推送一篇关于人脸识别的文献,目前被CVPR2020录为最佳人脸识别框架之一。这次“计算机视觉研究院”简洁给大家分析,后续我们会分享具体代码实现功能,有兴趣的同学请持续关注!

概述

从事人脸领域的你,都知道:由于面部表情的模糊性、图像的低质量以及注释者的主观性,对大规模面部表情数据集进行标注是非常困难的事情。
这些不确定性成为了深度学习时代大规模面部表情识别的关键挑战之一。为了解决这个问题,本次投稿的作者提出了一种简单而有效的Self Cure Network(SCN),它能有效地抑制不确定性,防止深度网络对某些面部图像的过度拟合。具体来说,主要通过两种方法:
小批量上的自注意力机制(self-attention machanism),对每个训练样本加权,进行等级正则化(ranking regularization);
仔通过细的重新标注机制(careful relabeling machanism),在排名最低的组中修改这些样本的标签。
简单说下背景
面部表情是人类传达情感状态和意图的最自然、最有力和最普遍的信号之一。自动识别面部表情对于帮助计算机理解人类行为并与其交互也很重要。在过去的几十年里,研究人员利用算法和大规模数据集在面部表情识别(FER)方面取得了重大进展,在实验室或野外可以收集数据集,如CK+、MMI、Oulu-CASIA、SFEW/AFEW、FERPlus、EmotioNet、RAF-DB等。
然而,对于从互联网上收集的大规模FER数据集,由于注释者的主观性以及模糊的野外面部图像所造成的不确定性,极难高质量地进行注释。


Self-Cure Network
于是作者就提出了SCN,主要由三个关键模块组成:self-attention importance weighting、rangking regularization和nosie relabeling。
在给定一批图像的情况下,首先利用主干CNN提取人脸特征。然后,self-attention importance weighting模块学习每个图像的权重,以捕获样本重要度进行损失加权。不确定的面部图像将被赋予较低的权重。接着,rangking regularization模块将这些权重按降序排列,并将其分为两组,并通过强制两个组的平均权重之间存在margin来对这两个组进行正则化(Rangk Regularization Loss(RR-Loss))。rangking regularization模块确保第一个模块学习有意义的权重来突出某些样本(如:可靠的标注)和抑制不确定样本(如:模糊的标注)。
最后一个模块是careful relabeling模块,它试图通过将最大预测概率与给定标签的概率进行比较来重新标记来自底层组的这些样本。如果一个样本的最大预测概率高于给定的带有边缘阈值的标签,则将该样本分配给一个伪标签。此外,由于不确定的主要证据是不正确的/噪声注释问题,从互联网上提取了一个极端噪声的FER数据集,称为WebEmotion,来研究SCN对极端不确定性的影响。
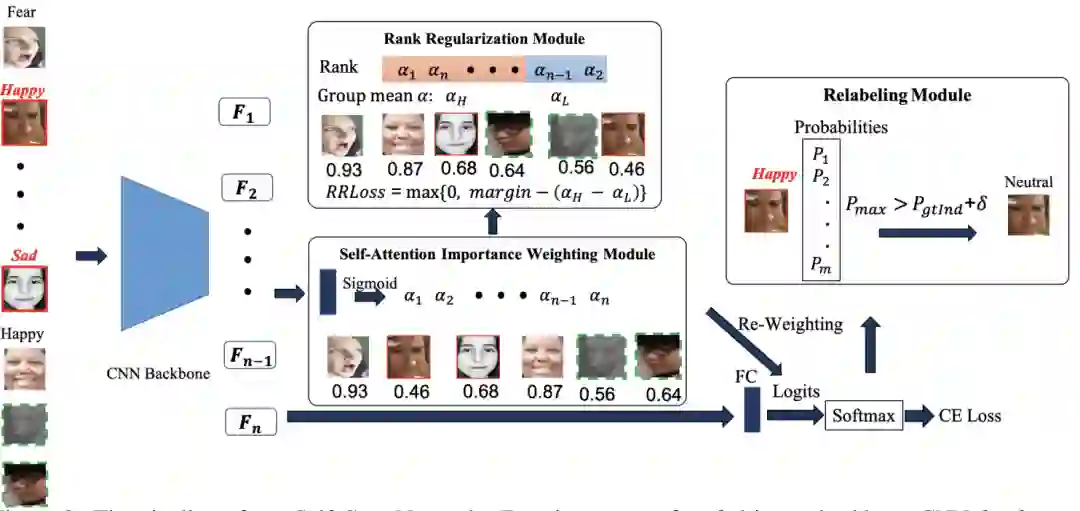
整个SCN可以端到端的方式进行训练,并且可以很容易地添加到任何CNN的主干网络中。
Self-Attention Importance Weighting
实际上就是采用一个含有FC层和sigmoid激活函数的网络来对每个图像预测权重,具体如下:
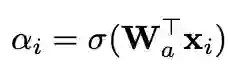
αi是第i个样本的importance weight。
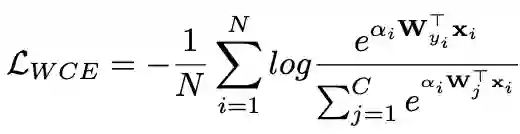
Rank Regularization
上述模块中的 self-attention weights可以在(0,1)中任意值,为了明确地约束不确定样本的重要性,作者精心设计了一个rank regularization模块来正则化注意权重。在rank regularization模块中,首先将学习到的注意权重按降序排序,然后将它们分成两组,比率β。rank regularization保证了高重要群体的平均注意权重高于具有margin的低重要群体。在形式上为此定义了一个rank regularization损失(RR-Loss),如下所示:
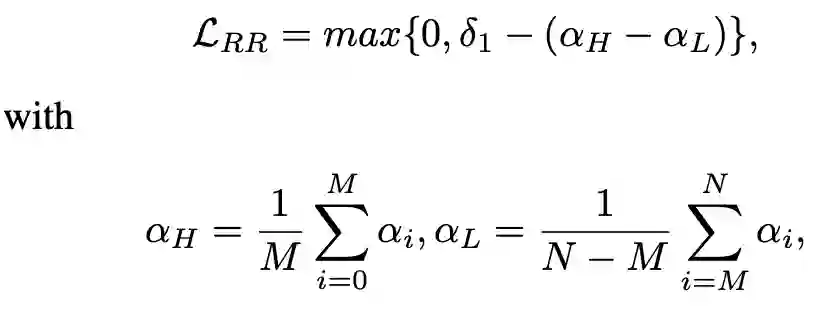
Relabeling
在rank regularization等模块中,每个小批量被分成两组,即高重要性和低重要性群体。实验发现,不确定的样本通常具有较低的重要性权重,因此一个直观的想法是设计一种重新标记这些样本的策略。
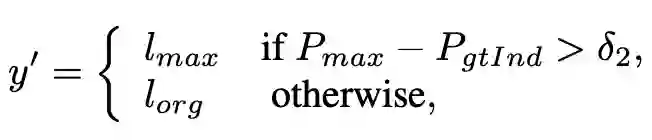
具体跑代码的试验参数设置,后期我们讲解实践的时候,一起说,这次我们先说说作者的实验结果及分析。
实验结果分析

Visualization of the learned importance weights in SCN
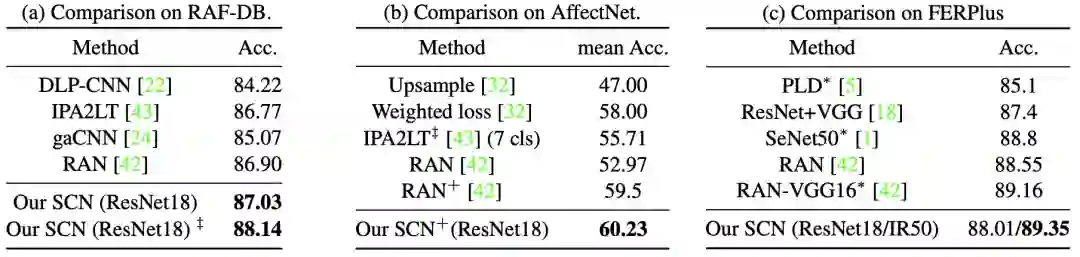
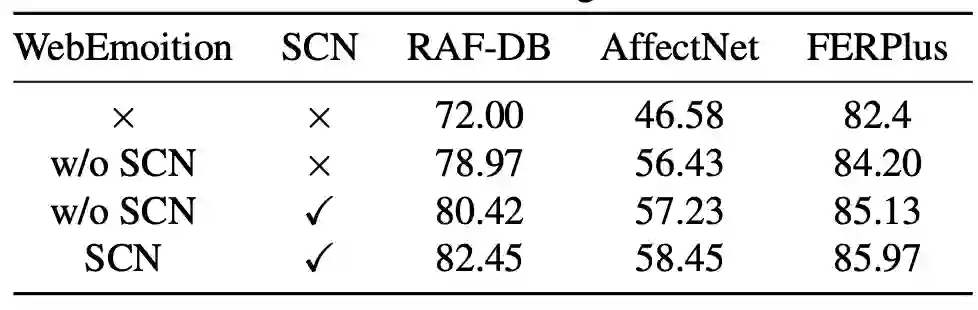
在synthetic noisy FER数据集中的评价如下:
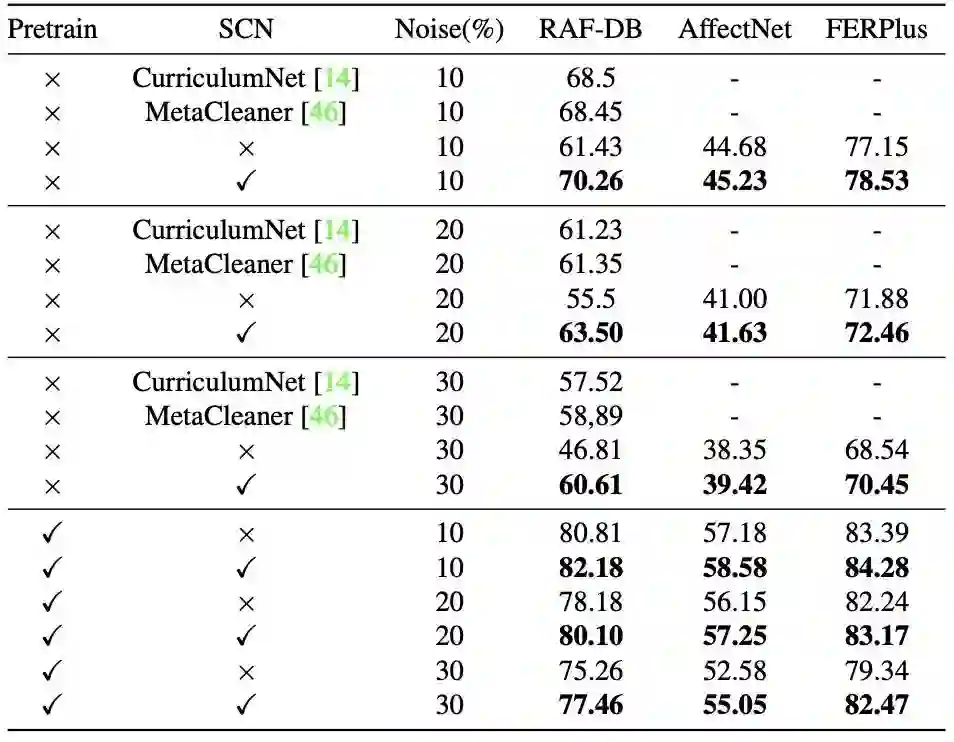
WebEmotion数据集

在WebEmotion数据集中预训练的影响如下:
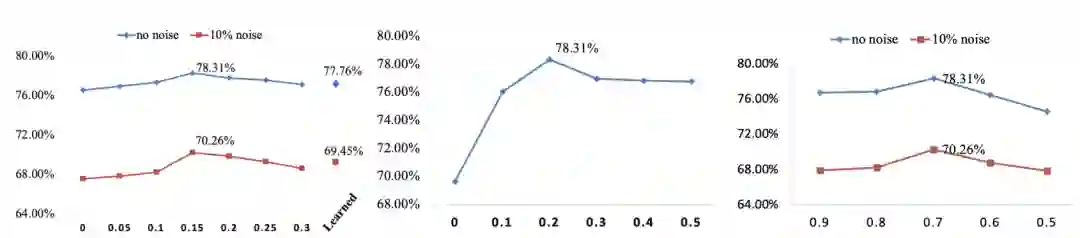
Evaluation of the margin δ1 and δ2, and the ratio β on the RAF-DB dataset