业界 | 专访达观数据CEO陈运文:文档审阅2.0时代到来
机器之心原创
作者:李泽南
利用机器学习技术审阅文档,生成摘要,提高文字工作效率是人工智能的重要发展方向。近日,达观数据推出了文档智能审阅系统 2.0 版,吸引了德勤、平安信托等众多公司的青睐。
在产品正式推出前,机器之心找到了达观数据的创始人和 CEO 陈运文,他向我们介绍了达观数据新版文档审阅系统背后的技术,同时也对自然语言处理(NLP)和人工智能技术的未来进行了展望。作为国内第一家将自动语义分析技术应用于行业中的人工智能公司,达观数据成立于 2015 年。这家公司旨在用文字语义自动分析技术为企业级客户提供文本自动抽取、审核、纠错、搜索、推荐、写作等智能软件系统。
该公司的 CEO 陈运文博士毕业于复旦大学,他同时也是上海市计算机学会多媒体分会副会长、国际计算机学会(ACM)和国际电子电器工程师学会(IEEE)高级会员,中国计算机学会(CCF)会员。他曾担任盛大文学首席数据官,腾讯文学高级总监、数据中心负责人,百度核心技术研发工程师等职务,曾带领团队多次获得 ACM 竞赛冠亚军。

达观数据创始人、CEO 陈运文博士
陈运文的职场经历,无论是百度的搜索引擎技术研发,还是盛大文学的数据负责人,都是在与数据打交道。他曾经研究利用技术挖掘数据提高公司的效率和收入,而在达观数据,他领导开发的技术力量已经可以剖析用户的海量数据,为更多企业提升收益。
达观数据是一家具有学术背景的公司,专注于将最新自然语言处理技术应用到具体场景中。「这件事情很难,但是我觉得特别有意思:我们面临着很多的技术挑战,有很多的工作要做,有困难才有动力。」陈运文表示。
文档审阅 2.0
在达观数据描绘的未来里,计算机并不会百分之百的代替人,它会作为人类的助手存在,对文档进行快速处理,补充人类的不足之处。人工智能算法可以发现人们容易忽略的错误。而人类在工作流程中的任务是复查计算机给出的结果,这样可以大幅度提高工作效率。
在金融等对于文本准确性要求很高的行业中,计算机具有快速处理数据的能力,对内容的复核,包括字词的复核都有天然的优势。
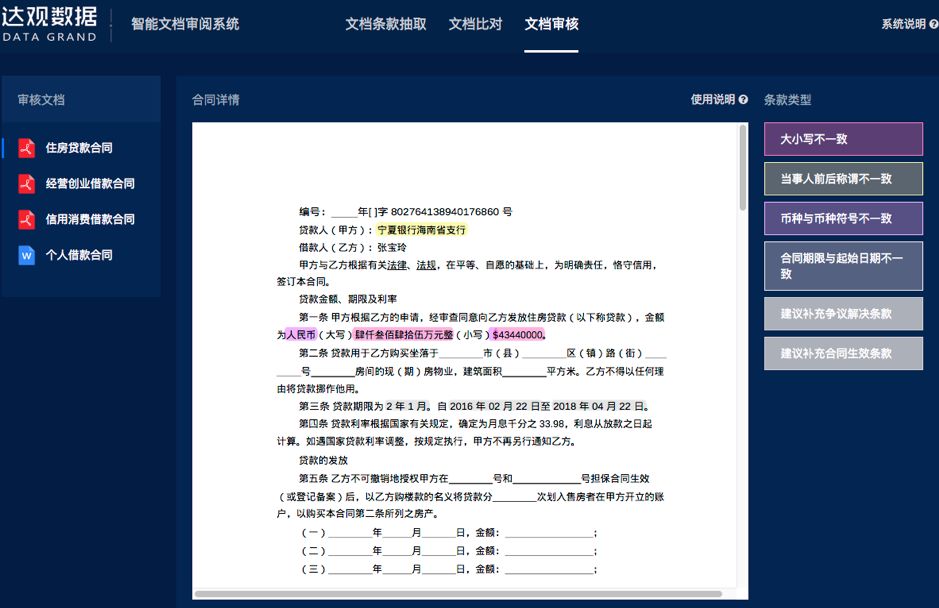
达观数据的文档智能审阅系统可以一键审核数十种常见风险。
在这个过程中,达观数据面临着很多挑战。「我们希望让计算机理解金融行业里的领域知识——『Know how』,」陈运文表示,「让算法和专业内容更加紧密地结合在一起。因此,我们投入了大量精力去了解和掌握金融行业员工日常的操作方式。我们需要把领域内的知识固化到软件系统内,这样软件才能像白领员工一样进行工作。」
陈运文表示,达观数据的语言处理模型在训练时使用了两部分数据,一部分是特定领域内的语料数据,包括行业中公开的语料数据、资料、专业术语等。公司技术人员已投入大量精力对数据进行了采集、归纳整理和分析。另一方面,达观数据的客户多年来也积累了大量高质量行业数据。通过高质量的数据训练算法,计算机系统会变得越来越聪明。据称,在一些具体操作中,达观数据的系统已具备了远超过普通人类的处理能力。
达观数据的文档审核系统在纠错算法和审核算法中采用了 LSTM 等技术,其 2.0 版还引入了迁移学习和增强学习。复杂的模型带来了更高的准确率,但也意味着计算成本的提升。而陈运文表示,即使在这样的情况下,计算机带来的便利性也大大超过了人力成本。
「深度学习、LSTM 等算法确实是比传统统计学习需要耗费更多的算力,」陈运文介绍道,「但另一方面,相比于高昂的人力成本来说。这些算法背后依赖的硬件成本即使在今天看来也并不高。由 GPU 组建的集群需要的成本比一群金融业白领的年薪要低得多。」
算力问题并不会成为实践面临的障碍。除了已有的效率优势之外,另一方面,硬件的成本每一年都在降低。达观数据认为,在未来,文本挖掘、自然语言处理的成本会降低到难以想象的地步——而要付给员工的工资只会不断增多。
在可用性方面,机器学习系统也有着自己的优势。在达观数据很多客户的专业领域内,培养一个专家需要很多年的时间,在此之后,经验和知识又很难迁移到其他人身上。而在今天,计算机软件系统一旦训练好,就具备了类似人类专家水平的能力,同时可以零成本地进行复制,服务更多人。
达观数据曾做过比较,现在一台服务器提供的工作能力基本相当于 15 个普通的员工。而随着硬件成本的下降,这个数字还将不断提高。现在一台服务器运行一年的成本可以是 2 万元以内。
在提高计算并行化效率上,达观数据的产品采用了 Mini batch 等新技术。同时,其模型也结合了 LSTM、CNN、统计学习等方法,通过独有的双层组合学习的方法,整个系统可充分发挥各种算法的优势,让算法的能力发挥到最大。
逐渐成型的市场
在技术以外,如何向传统公司推广人工智能产品也是摆在各家 AI 科技公司面前的难题。在达观数据看来,目前最困难的起始阶段已经过去。
「坦率地说,应该感谢媒体,它们过去三四年来对于人工智能进行了大量的宣传报道,」陈运文表示,「我们发现传统行业客户,不论是领导还是一线的员工,他们都对人工智能、大数据和信息化带来的价值有所了解。我们现在向客户介绍产品没有什么障碍,客户都很乐意去尝试先进的技术。」
但解决方案成型关键在于如何很好地解决客户面临的问题。
达观数据认为,今天中国的 AI 产业正处于历史上很好的一个时期——来自各行各业的客户们已经开始愿意接受新兴的技术——但这也意味着科技公司不能制造泡沫,必须打造优秀的产品,要让客户觉得产品配得上人工智能的称号。
在 NLP 的赛场上,一些科技巨头也在不断展示着自己的实力。面对竞争,陈运文认为国内 AI 公司的优势在于能够提供个性化的服务:「微软在 NLP 领域有着强大的技术实力,但中国本土的企业并不落后。我们的优势在于可以向客户提供贴身的服务。」达观数据在实践中发现,每一个客户的需求都有些许的差异——很难用一个通用化的模型来满足不同客户的个性化需求。
这家公司致力于为客户提供解决实际问题的系统,提供定制化方案,而不是通过一个大而全的平台,试图通过一个算法解决大量问题——这样很难把一个具体的问题解决的足够好。
目前达观数据的文档处理系统已经发展了大量客户,其中包括很多世界五百强的大型企业,金融行业、新闻媒体、法律行业和政府。如招商银行、平安信托、华泰证券等等金融领域的公司;以及华为、海尔等五百强企业里的标杆客户。这些客户、行业的特点是它们都会接触大量的文档资料。
达观数据文档处理系统下一步的推广目标是传媒行业、政府和事业单位。这些机构每天都面临着大量的文字处理工作,而目前为止,所有这些都需要耗费大量的人力,未来这家公司提供的系统将会大幅解放这些人力。
达观数据发现,很多发达地区的地方政府对于新技术具有很高的热情。比如行政审批,这几乎占到了政府部门 1/3 的工作量。这些工作目前都还是依靠大量的基层公务员来做的。达观数据预计,它们中的很大一部分,包括预审、材料检查等都可以在未来由计算机来承担。
技术优先的团队
基于公司的基因,陈运文为达观数据选择了面向企业客户的道路。经过三年多的发展,这家公司已形成了规模近 200 人的团队,其中研发团队占六成。这家公司有着浓厚的技术氛围,一直在不断发表介绍 NLP 技术的博客,举办算法大赛。
「我自己也在写技术博客!我们对于技术的态度非常开放:技术是要拿出来分享的。」陈运文表示,「我特别鼓励员工总结自己的经验和想法,把它写成文章发表出来,让所有文本挖掘的爱好者都能够看得见。这样对于整个产业都是有益的。」
达观数据有很多工程师都公开发表了技术博客,这些文章经常会填补国内在特定领域上技术文章的空白。

陈运文曾带队参加 ACM 数据竞赛并获奖。
陈运文也有着数据竞赛的情节。他曾作为队长组队参加过很多国际算法竞赛,并拿到过多个冠军。达观数据举办了自己的 NLP 数据竞赛:「达观杯」文本智能处理挑战赛。据介绍,今年的比赛已经吸引了 2000 余名参赛选手,成为了目前国内规模最大的文本挖掘比赛。达观数据认为,能够聚拢全国最具实力的文本挖掘爱好者共同解决一个问题,是一个很有意义的事情。
在 2017 年 4 月的 A 轮融资后,达观数据已经推出了多种产品,并迅速拓展了业务。陈运文本次还透露,达观数据即将在 2018 年第三个季度公布自己的 B 轮融资交易情况。这将成为中国目前为止自然语言处理领域内最大的融资之一。具体细节很快即将公布。
文本挖掘在中国,不仅是在技术上,还是在应用上都仍处于早期状态。在未来,达观数据的发展将会着力于两个方面,一方面继续加大技术上的投入:把中文的文本挖掘技术做深做透。而在应用方面,达观数据希望改变中国传统企业「人拉肩扛」的原始文本处理方式,为众多客户带来自动化。
「我们认为,大量的文字处理应用场景未来一定需要更好的工具、更自动化的手段,去帮助人们提高工作效率。」陈运文表示,「我们会开发更多的应用,部署到每个行业、每个客户身边。对于我们来说,未来还有很多工作要做。」作为一家专注于语义理解技术的 AI 企业,达观数据文档智能审阅系统 2.0 版本只是一个开始,这家公司还希望在未来向普通用户提供更多产品。
「也许等我们有足够的资源和力量的时候,会尝试推出一些面向消费者的文字处理工具。未来也许每一个中国的消费者,在头疼于文字处理中时,达观数据的系统可以为你们提供帮助。不管是写作、修订、审阅、分类,人工智能系统都能够大幅度提高人们的工作效率。」陈运文表示。

本文为机器之心原创,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com





