![]()
本文为约10740字,建议阅读15分钟
本文介
绍了如何基于 PyTorch 的业务模型快速迁移成 OneFlow 的模型,并进行大幅度的训练/推理性能优化、部署上线。
![]()
要想炼丹爽得飞起,就要选择一个顺手的炉子。作为 AI 工程师日常必不可缺的「炼丹炉」,「PyTorch 还是 TensorFlow?」已成为知乎、Reddit 等炼丹师出没之地每年都会讨论的热门话题。
业界流传一种说法:PyTorch 适合学术界,TensorFlow 适合工业界。毕竟,PyTorch 是用户最喜欢的框架,API 非常友好,Eager 模式让模型搭建和调试过程变得更加容易,不过,它的静态图编译和部署体验还不令人满意。TensorFlow 恰恰相反,静态编译和部署功能很完备,不过其调试体验让人欲哭无泪。
那么问题来了:
鱼和熊掌真的不可兼得吗
?未必,来自北京的一流科技团队推出的开源深度学习框架 OneFlow 已经做到了。
等等,OneFlow 一直主打分布式和高性能,易用性也能和 PyTorch一样吗?听说过 OneFlow 的人一定会发出这样的疑问。
没错,从 2016 年底立项之日起,OneFlow 就是为大规模分布式而生,特色之一就是静态图机制,2020 年 7 月在 GitHub 上开源时还不支持动态图。不过,OneFlow 团队用一年多时间自研了动态图引擎, OneFlow 0.7 版本已支持和 PyTorch 一模一样的 Eager 体验,也就是说,OneFlow 实现了同时支持动态图和静态图。不仅如此,OneFlow 编程 API 完全和 PyTorch 兼容,常见深度学习模型只需修改一行 import oneflow as torch 就可以把 PyTorch 写的模型在 OneFlow 上跑起来。
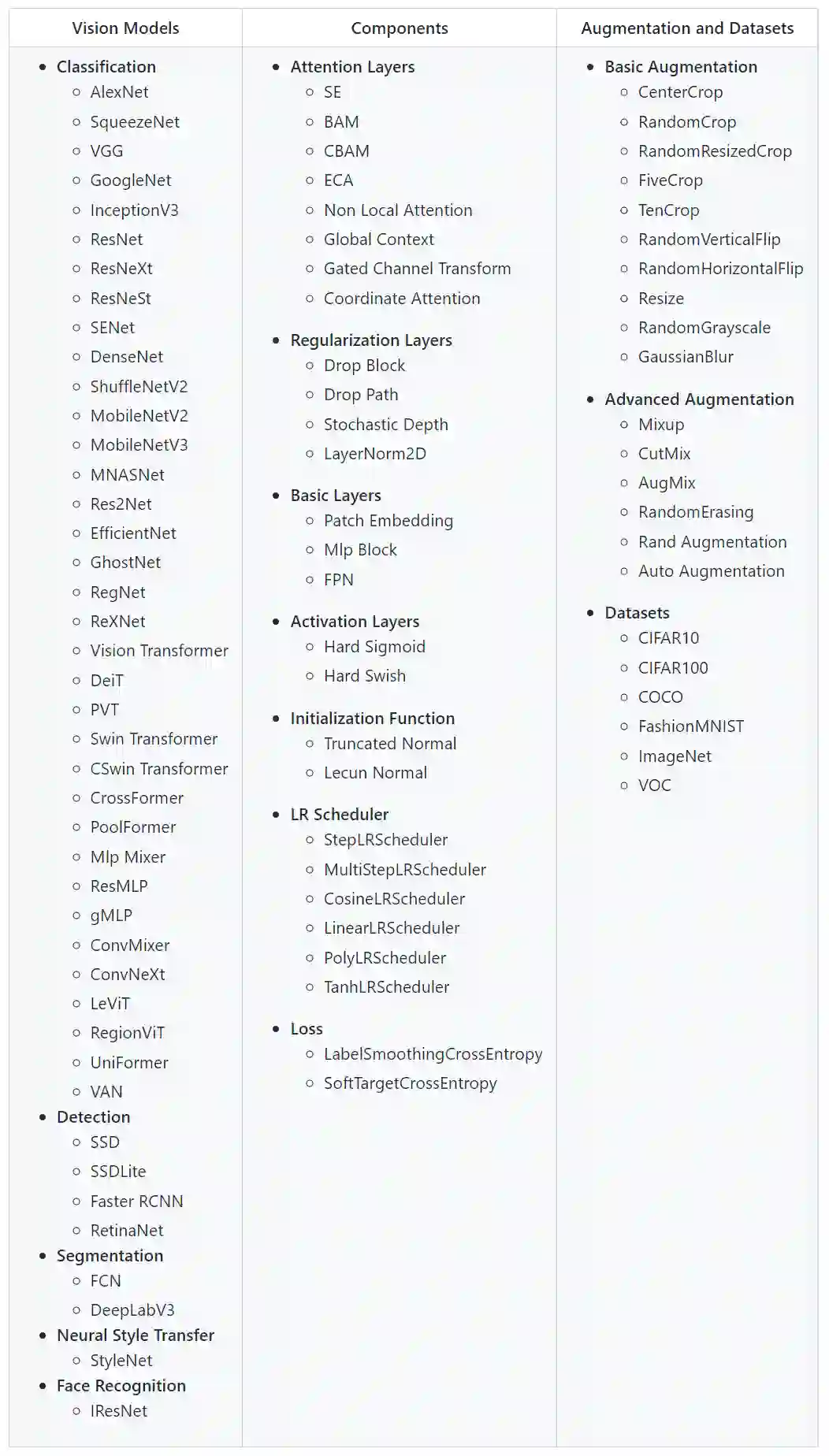
不妨先到 OneFlow 视觉模型库 flowvision 看一看:https://github.com/Oneflow-Inc/vision ,这个模型库已经支持计算机视觉领域图像分类、分割和检测等方向的经典 SOTA 模型 (见下表),这些模型都可以通过 import torch as flow 或 import oneflow as torch 实现自由切换。
![]()
OneFlow 和 PyTorch 兼容之后,用户可以像使用 PyTorch 一样来使用 OneFlow ,对模型效果比较满意之后,可以继续使用 OneFlow 扩展到大规模分布式或使用静态图部署模型。听上去是不是 too good to be true?
在下面的案例中,一家头部通信公司基于 PyTorch 的业务模型快速方便地迁移成 OneFlow 的模型,并进行大幅度的训练/推理性能优化、部署上线,短短几天时间就让业务得以按时上线部署,且各项性能指标均大幅超出预期!
因业务发展需求,这家通信公司近期将上线一款基于深度学习的图像识别应用,该项目的业务需求有如下五个特点:
数据量大:数据库中有过亿级别的图片
模型简单:比较常规的分类模型
400 多张显卡,短期内无法扩容
对于训练/推理的吞吐有硬性指标
上线时间紧迫
用户基于市面上最流行的深度学习框架 PyTorch 搭建了业务模型,且跑通了正常训练流程,但是训练/推理都很慢,远远达不到目标(离上线 QPS 有 20 倍的差距),随着交付日期临近,整个团队深陷焦虑。
用户尝试了各种方案(基于已有实现进行优化)都无济于事,于是调研了其他深度学习框架,如 TensorFlow、OneFlow 等,发现 OneFlow (https://github.com/OneFlow-Inc/oneflow) 是加速 PyTorch 风格代码的最平滑框架。
具体而言,用户选择试用 OneFlow的
理由
主要有三点:
1、OneFlow 是众多深度学习框架中,API 与 PyTorch 兼容性最高的,这样方便工程师用最少的时间/人力成本,对已有项目代码进行迁移,减少学习成本。
2、OneFlow 动静转换十分方便,动态图(Eager)模式的代码简单改动几行就能转换为静态图(nn.Graph)模式。
3、OneFlow 在框架层面做了大量优化,nn.Graph 提供了简洁、丰富的性能优化选项,如算子融合(Kernel Fusion)、自动混合精度训练 (Auto Mixed Precision Training) 等。
于是,用户就开始尝试将已有代码迁移至 OneFlow,没想到,不到半天就搞定并跑起来了,迁移过程非常丝滑。
在 OneFlow 官方文档(https://docs.oneflow.org/master/index.html) 以及 OneFlow 研发团队的大力支持下,用户开展了以下工作:
将已有 PyTorch 的项目代码完全迁移到 OneFlow
将项目代码由动态图模式(Eager Mode)改造为静态图模式(Graph Mode)
开启 OneFlow Graph 模式下的各种优化选项并训练模型
用 Serving 模块部署模型上线
1. 一键迁移 PyTorch 模型转 OneFlow 模型:只需 import oneflow as torch 就够了
OneFlow 最新发布的 0.7.0 版本对 PyTorch 接口的兼容性有了进一步的完善。OneFlow 对已经支持的算子都能保证和 PyTorch 的接口在语义和结果上一致。于是用户就尝试了一下迁移模型脚本到 OneFlow。由于业务模型的主干网络是 resnet101,在迁移过程中,用户参考了官方文档(https://docs.oneflow.org/master/cookies/torch2flow.html)来迁移 ,发现只需要模型文件中与 torch 相关的 import 修改为 import oneflow as torch,就完成了模型代码的迁移工作。
在模型脚本迁移完毕之后,还需要验证模型迁移的正确性,看看精度是不是对齐了。
1)用户首先做了推理精度的验证,就是直接加载 PyTorch 训练好的模型然后验证推理精度,由于 OneFlow 对齐了 PyTorch 的接口,所以加载 PyTorch 的模型也非常方便,只需数行代码即可完成:
import torchvision.models as models_torchimport flowvision.models as models_flow
resnet101_torch = models_torch.resnet101(pretrained=True)resnet101_flow = models_flow.resnet101()
state_dict_torch = resnet101_torch.state_dict()state_dict_numpy = {key: value.detach().cpu().numpy() for key, value in state_dict_torch.items()}
resnet101_flow.load_state_dict(state_dict_numpy)
2)在验证完推理精度后接着就是验证训练流程,在对齐训练超参数之后,使用 OneFlow 训练模型的 loss 曲线和 PyTorch 的收敛曲线也一致,在小数据集上的精度完全一致。
2. 使用 OneFlow 的 nn.Graph 加速模型训练与推理性能
在验证完算法正确性后,就需要考虑如何加速执行了。如果使用现有的动态图模型直接部署,在现有的机器资源和时间限制内,使用最原始的代码实现还差约 20 倍的性能,短期内是一个不可能完成的任务。
用户决定双管齐下,在基于 PyTorch 做加速优化时,并行地使用 OneFlow 进行加速。最终结合「
动态转静态、算法逻辑约减、提高并行度、静态编译优化
」这四类技巧,最终单机执行达到了 25 倍以上的加速效果。
动态图转静态图执行后,得到了约 25% 的性能加速。
OneFlow 有个 ResNet50 的开源项目( https://github.com/Oneflow-Inc/models/tree/main/Vision/classification/image/resnet50 ),了解到单卡的执行效率已经做得很高,照猫画虎,这些优化技巧都可以用在 ResNet101 上。
OneFlow ResNet50 下做模型加速使用的是静态图 nn.Graph,类似 PyTorch 的 TorchScript。但OneFlow的优化功能做的更全面一些,运行时也是一个特有的服务于加速的 Actor Runtime。
nn.Graph 是一个面向对象风格的静态图类,它代表一个完整的静态计算图。对于预测任务,nn.Graph 可以只包括前向计算;对于训练任务,还可以包括后向计算和模型更新。
nn.Graph 的基础接口和 nn.Module 的行为比较类似,比如添加子 Module,自定义算法执行逻辑,调用以执行一次计算,保存模型等。被添加进入 nn.Graph 的 nn.Module 对象,在 nn.Graph 里执行时,就会采用静态图模式执行,如此动态图下的计算逻辑就可以被静态图直接复用,这样就实现了动静执行的切换。特殊一点的是,Optimizer 也可以添加进入静态图,这样前向、后向、模型更新可以被加入一个完整的静态图做联合优化。
下面的步骤把动态执行的 ResNet101Module 变成静态执行,使用方式和 nn.Module 类似,只需要声明、实例化、调用三个基本步骤。
1)声明一个静态图:主要包括两部分,先在初始化函数中添加要静态化的 nn.Module 和 Optimizer;然后在 build 函数中构图。
class ResNet101Graph(oneflow.nn.Graph): def __init__(self, input_shape, input_dtype=oneflow.float32): super().__init__() self.model = ResNet101Module(input_shape, input_dtype) self.loss_fn = ResNet101_loss_fn of_sgd = torch.optim.SGD(self.model.parameters(), lr=1.0, momentum=0.0) self.add_optimizer(of_sgd) _config_graph(self) def build(self, input): out = self.model(input) loss = self.loss_fn(out) loss.backward() return loss
2)实例化静态图:按普通的 Python Class 使用习惯去做初始化就好。
resnet101_graph = ResNet101Graph((args.batch_size, 3, img_shape[1], img_shape[0]))
3)调用静态图:类似 nn.Module 的调用方式,注意第一次调用会触发编译,所以第一次调用比后面的时间要长。
for i in range(m): loss = resnet101_graph(images)
把 ResNet101 的 nn.Module 的实例加入 nn.Graph 执行后,对比得到约 25% 的加速。
用户在把动态图代码迁移到静态图代码的过程中,因为需要考虑哪些部分要做静态化,所以对模型做了模块化的重构,但发现本任务中有些计算是做实验时遗留的,在部署时并不必要,顺便做了算法逻辑的约减:
总体而言,算法层次方面累积加速了 2.33 倍,事实证明,算法逻辑本身具有很大的优化空间,代码做好模块化,可以比较容易找到算法逻辑上的优化点。当然,这部分改善也适用于PyTorch。
这个思路也比较直接,在做完优化的基础上,用户观察到 GPU 的利用率只有 30%。此时 batch_size 为 1( BN 的某些参数和 batch 大小有关,原先用户担心扩大 batch_size 可能影响计算结果,事后证明这个担心是多余的,从理论推导和实验结果都证实,扩大 batch_size 并不影响计算结果),单进程,提高数据并行度是很值得尝试的方案。因此,用户尝试了提高 batch_size 和 多进程方案:
提高并行度的累积加速是 4.6 倍。增加并行度以充分利用多核、多设备,带来了最明显的加速效果。当然,这里的优化效果是用户迁移到 OneFlow 后实现的,在 PyTorch 上也可以做到。
做到以上优化后,GPU 利用率已经能比较稳定的保持在 90%,一般来说,已经没有太大优化空间了。但是,OneFlow nn.Graph 下还有一些自动的编译优化技术可以尝试。
比如利用自动混合精度做低精度计算、利用算子融合来减少访存开销等,这里最终带来了 64% 的加速,速度到了原来最好性能的 1.56 倍。
此前示例中提到的 _config_graph 函数就是在配置这些优化选项,具体如下:
def _config_graph(graph): if args.fp16: graph.config.enable_amp(True) if args.conv_try_run: graph.config.enable_cudnn_conv_heuristic_search_algo(False) if args.fuse_add_to_output: graph.config.allow_fuse_add_to_output(True) if args.fuse_pad_to_conv: graph.config.allow_fuse_pad_to_conv(True)
对于 ResNet101,batch_size 设置为 16,在 nn.Graph 无优化选项打开的基础上:
自动混合精度训练,自动将网络中的合适的算子由 FP32 单精度计算转换成 FP16 半精度浮点进行计算,不仅可以减少 GPU 显存占用,而且可以提升整体性能,在支持 Tensor Core 的 GPU 设备上还会使用 Tensor Core 进一步加速训练。
cudnn 的 convolution 算子包含多种算法,例如前向的算法(https://docs.nvidia.com/deeplearning/cudnn/api/index.html#cudnnConvolutionFwdAlgo_t)。不同的 input 和 filter 大小在不同的算法下有不同的性能表现,为了选择最佳算法,在调用 cudnn convolution 算子接口前,需要先调用 cudnn convolution searching algorithm 的接口。cudnn 提供了2种搜索模式:启发式搜索(https://docs.nvidia.com/deeplearning/cudnn/api/index.html#cudnnGetConvolutionForwardAlgorithm_v7)和试运行搜索(cudnnFindConvolutionForwardAlgorithm)(https://docs.nvidia.com/deeplearning/cudnn/api/index.html#cudnnFindConvolutionForwardAlgorithm)。
启发式搜索是通过一种「查表」的方式来搜寻最佳算法,cudnn 对不同的参数配置对应的最佳算法进行了预先定义,然后每次搜索时进行匹配得到结果。试运行搜索会传入实际的张量进行多次试运行,然后返回运行结果。搜索算法返回的结果都是不同算法的元信息及其所需耗时。
启发式搜索在搜索阶段不需额外分配内存,且能更快得到结果;而试运行搜索能得到更为全面和精确的结果,也即通常能更精确地找到最佳算法。启发式搜索在常见情形下可以得到与试运行搜索一致的结果,但在一些特殊参数配置下无法得到最佳结果。OneFlow 中默认启动了启发式搜索,但可通过 graph.config.enable_cudnn_conv_heuristic_search_algo(False) 接口关闭,关闭后使用的就是试运行搜索。
在 CNN 网络 Backbone 中有很多 convolution + pad 的组合,convolution 算子自身支持 pad 操作,自动将 pad 算子 fuse 到 convolution 算子上,可以省掉 pad 算子的开销,提升网络整体性能。
自动将网络中常见的访存密集型算子 Elementwise add 算子和上游的算子 fuse 起来,可以减少带宽使用,从而提升性能。对于 Elementwise add 算子来说,将其 fuse 到上一个算子,可以减少一次数据读写,有约 2/3 的性能提升。
另外 nn.Graph 可以很方便地支持使用 TensorRT 。本优化对象没有更新模型的需求,所以也适合使用 TensorRT 做加速。在 nn.Graph 无优化选项基础上, batch_size 设置为 16,新增自动混合精度、NHWC、使用 TensorRT 后端,可以提速 48%。
在这个模型里,只使用 TensorRT 后端比只使用 OneFlow 的静态图优化还差一点,可能的原因是, TensorRT 下的一些优化在 nn.Graph 里已经做了,所以没有带来额外收益。不过其实验起来还比较方便,编译一下带 TensorRT 的 OneFlow,再在 nn.Graph 下打开开关就可以,列出来作为参考:
def _config_graph(graph): if args.tensorrt: graph.config.enable_tensorrt(True)
以上记录了加速的主要过程,动态转静态加速约 1.25 倍、算法逻辑约减加速约 2.33 倍、提高并行度加速约 4.6 倍、静态编译优化加速约 1.6 倍,累积加速约 21 倍。中间有些小的优化点没有完全记录,
实际累积的加速效果达到了 25 倍以上
,超过了项目部署的 20 倍加速需求。
3. 使用 OneFlow-Serving,轻松将训练好的模型部署上线
当用户完成训练,得到最终的模型之后,接下来的一步就是模型部署。不同于模型训练时需要进行权重更新,部署时的权重固定不变,所以可以进行更激进的速度优化,例如 int8 量化、更广泛的 kernel fusion、constant folding 等等。
用户参考 OneFlow v0.7.0 提供了官方的 Serving 模块(https://github.com/Oneflow-Inc/serving),它是一个 NVIDIA Triton 的后端,集成了 OneFlow 内置的 XRT 模块,并提供了开箱即用的用户接口。只需使用下述方法就将训练好的 OneFlow 模型快速高效的部署起来:
为了将模型用于推理,在使用 nn.Graph 训练完成之后,需要构造一个只包含前向的 ResNet101InferenceGraph:
class ResNet101InferenceGraph(oneflow.nn.Graph): def __init__(self): super().__init__() self.model = resnet101_graph.model def build(self, input): return self.model(input) inference_graph = ResNet101InferenceGraph()
并以一个样例输入运行 inference_graph,触发 inference_graph 的计算图构建:
unused_output = inference_graph(flow.zeros(1, 3, 224, 224))
接下来就可以运行 flow.save 将 inference_graph 的计算图结构以及权重均保存在 "model" 文件夹下,以供部署使用:
flow.save(inference_graph, "model")
docker run --rm --runtime=nvidia --network=host -v$(pwd)/model:/models/resnet101/1 \ oneflowinc/oneflow-serving:nightly
由此可以启动一个部署着 ResNet101 模型的 Docker 容器。这里的 -v 很重要,它表示将当前目录下的 model 文件夹映射到容器内的 "/models/resnet101/1" 目录,其中 /models 是 Triton 读取模型的默认目录,Triton 会以该目录下的一级目录名("resnet101")作为模型名称,二级目录名("1")作为模型版本。
docker run --rm --runtime=nvidia --network=host -v$(pwd)/model:/models/resnet101/1 \ oneflowinc/oneflow-serving:nightly oneflow-serving --model-store /models --enable-tensorrt resnet101
模型就会通过 OneFlow 的 XRT 模块自动使用 TensorRT 进行推理,此外 OneFlow Serving 还支持类似的 “--enable-openvino”。
启动 Docker 容器后,运行下面的命令,就可以查看服务状态:
curl -v localhost:8000/v2/health/ready
返回值为 HTTP/1.1 200 OK,表示服务正在正常工作。
接下来就可以使用 Triton 的 C++ 或 Python SDK 实现向服务端发送请求并获取结果的逻辑了,例如一个最简单的客户端:
import numpy as npimport tritonclient.http as httpclientfrom PIL import Image triton_client = httpclient.InferenceServerClient(url='127.0.0.1:8000') image = Image.open("image.jpg")image = image.resize((224, 224))image = np.asarray(image)image = image / 255image = np.expand_dims(image, axis=0)image = np.transpose(image, axes=[0, 3, 1, 2])image = image.astype(np.float32) input = httpclient.InferInput('INPUT_0', image.shape, "FP32")input.set_data_from_numpy(image, binary_data=True)output_placeholder = httpclient.InferRequestedOutput('OUTPUT_0', binary_data=True, class_count=1)output = triton_client.infer("resnet101", inputs=[input], outputs=[output_placeholder]).as_numpy('OUTPUT_0')print(output)
$ python3 triton_client.py[b'3.630257:499']
在上述案例中,用户因时间紧迫没法做充分调研,抱着试试看的想法选择了 OneFlow,幸运的是,终于在极限压缩的项目周期里顺利完成了任务。
基于 OneFlow v0.7.0 ,用户轻松地将之前开发的 PyTorch 的业务模型代码一键迁移成 OneFlow 的模型代码,再经过简单加工就转成 OneFlow 的静态图 nn.Graph 模式,并利用 nn.Graph 丰富、高效、简洁的优化开关来快速大幅提升模型的训练速度,利用完善的周边工具链如 OneFlow-Serving 方便的进行线上部署。值得一提的是,用户还可以使用 OneFlow-ONNX 工具将 OneFlow 高效训练好的模型转成 ONNX 格式导入到其他框架中使用。
本文只介绍了借助和 PyTorch 的兼容性 OneFlow 帮助用户实现模型加速和部署的例子。OneFlow 原来的杀手锏功能“大规模分布式”还没有体现出来,未来,我们将进一步介绍 OneFlow 如何帮助习惯 PyTorch 的用户便捷地实现大规模预训练 Transformer 模型和搜索推荐广告领域需要的大规模 embedding 模型。