实锤举报!复旦硕士被爆「英译中」9年前顶会论文(附对比)

新智元报道
新智元报道
来源:知乎
编辑:好困 小咸鱼
【新智元导读】近日,又有一起学术不端行为被网友举报,作者竟是复旦大学重点实验室的研究生?相比于此前内容的一比一复刻,这次则是对9年前顶会论文来了一个「英译中」。

教科书般的「英译中」


摘要


引言


问题描述





实验分析
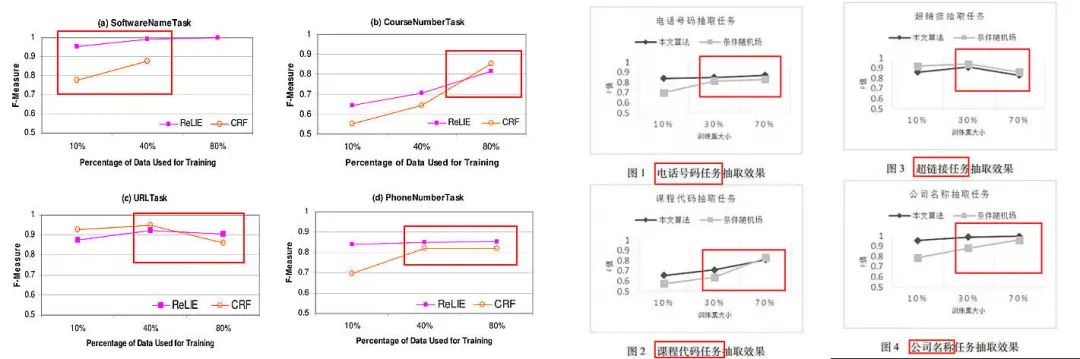



出于对科研的敬畏
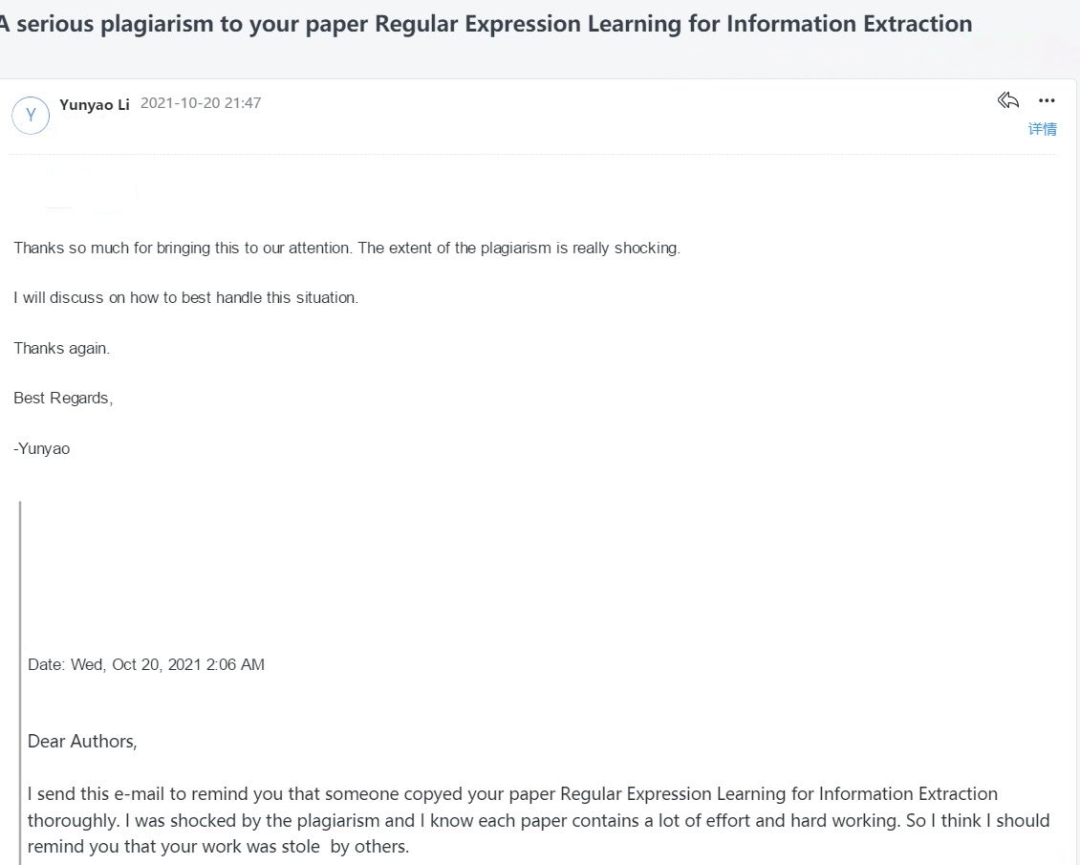


网友力挺
网友力挺


参考资料:
https://www.zhihu.com/question/493606496/answer/2183263738
https://aclanthology.org/D08-1003/
http://www.shcas.net/jsjyup/pdf/2017/2/基于正则表达式构建学习的网页信息抽取方法.pdf

登录查看更多
相关内容

Arxiv
0+阅读 · 2022年4月19日
Arxiv
0+阅读 · 2022年4月19日





相关VIP内容
相关资讯
相关论文
Arxiv
0+阅读 · 2022年4月19日
Arxiv
0+阅读 · 2022年4月19日