转载公众号 | 数字化领航
OpenKG地址:http://openkg.cn/dataset/network-communication
文章作者:新华三集团
出品平台:数字化领航
![]()
OpenKG是中国中文信息学会语言与知识计算专业委员会所倡导的开放知识图谱社区项目。旨在推动以中文为基础的知识图谱数据、算法和工具的开源和开放工作。近期,紫光股份旗下新华三集团在OpenKG上创建资源池(http://openkg.cn/dataset/network-communication)并贡献网络通信行业知识图谱。
新华三集团
上传的知识库,主要是面向行业产品领域,包括:
产品类型、系列、型号、规格指标、场景配置、组网方案、运维指导等方面词法以及常识类知识。
这些知识可以直接用新华三的图数据引擎HKG进行知识的导入、管理、计算。
也可经过简单的模板转换后存储到任意图或者关系型数据库。
行业知识获取之初存在着诸多挑战。
虽然拥有大量的数据,但是这些数据结构化程度不高,大量有价值的知识更多是存在于非结构化的文本中。
这些数据专业性强、术语繁多,从理解上来看与通用语言理解存在很深的鸿沟,从逻辑上来看场景又十分复杂。
而在当时,开源的电子信息或者网络通信行业词库知识为零,常识知识为零,带标注可训练的数据为零。
而要实现该行业的知识抽取,就必须在众多困难中不断破冰。
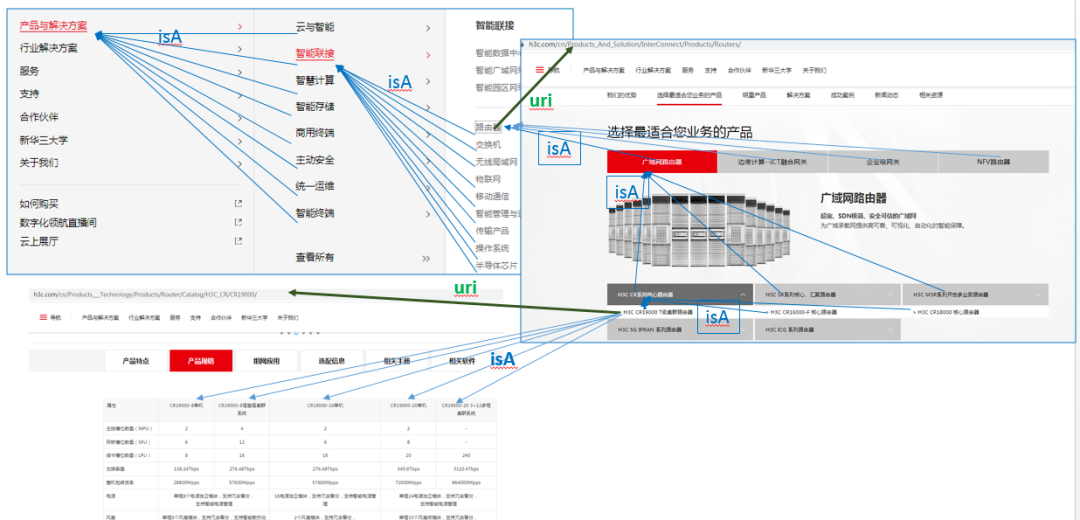
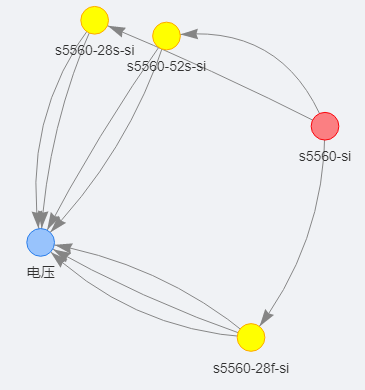
知识处理一定是一个从易到难,从粗到细、从人工到自动的过程。首先,为了构建一个初始的知识库,首要的目标是数据结构化。资料管理通常是树形结构,如新华三官网,以树状结构梳理了产品类型-产品系列-规格型号的关系,在产品规格型号一页,又以表格记录了产品的各种软硬件规格描述。所以,可以使用爬虫系统收集和解析产品之间“isA”和“sameAs”的关系,以无监督+词向量的方式对齐了产品规格特性,最终以模板映射到图上三元组关系。
![]()
![]()
然后再采用各种手段进行知识扩充。包括无监督算法进行数据海选后专家标注小样本数据然后再采用半监督方式进行知识增强,当知识规模十分庞大的时候,可逐步实现自动大量标注,从而实现各种基于深度学习的知识自动化抽取能力。
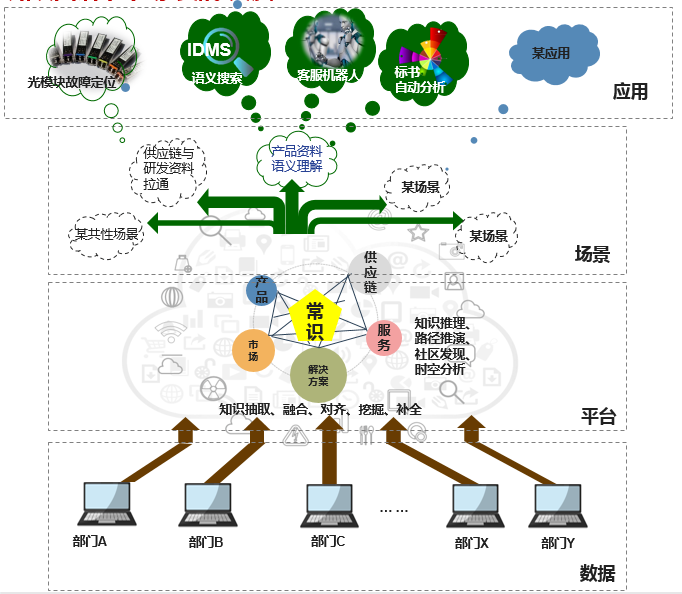
以新华三集团为例,这种面向全产业链多发展的企业,若拥有一个知识大脑,可以做到从市场到解决方案到研发到供应链,从芯片到云到网、边、端的知识全面拉通。而构建数字大脑的基础,首先需要行业常识库(http://openkg.cn/dataset/network-communication),这个常识库可以从词汇及理解每一个环境的行业要素。相当于以常识库为纽带,全面支撑起“物-料-人-法-环”的各类关系。当各环节部门众包自己的数据,数据经过与核心常识库的实体、本体进行融合、对齐、消歧,知识大脑认知能力逐渐提升,最终形成的知识网络将时数据能量将务必巨大。
![]()
![]()
在行业搜索引擎或者智能问答领域中,当没有行业知识库时,通用搜索引擎几乎只能通过字符串命中的方式进行搜索召回。这将带来很多理解偏差。尤其是在实体识别、意图识别、专业推理等方面。
在行业场景中存在着大量同名实体,比如说”vxlan”,它既是一种网络形式、也是配置命令、也是设备规格特性。有了网络常识库,解释NLP语义分析技术,便可以识别类似这样的词汇在当前语境中所表达的含义。
行业场景中,不通的人员个体对同一名词的表述不一样。比如对于“irf3.1组网”,有人以“纵向堆叠”口语化表达,有人以“802.1br”协议代指,甚至有人以“1br”组网相关协议简称代指。但是如果机器没有相关常识库,则对于以上类似的案例无法做到一致理解。而网络常识库利用具有“isA”同等功能的属性整理了众多行业同义词,可以在机器中通过“实体对齐”环节帮助机器理解相关行业词汇。
如果用户提问“s12500设备板卡类型都有哪些?”,若数据库上相关记录是“数据中心框式设备单板大全”。这会造成什么问题呢?就是明明数据库里有问题,但是由于用户输入的关键字和数据库记录的倒排索引词汇覆盖率非常低而导致正确答案会无法被命中召回。怎么解决这个问题呢?给底层搜索逻辑关联“行业知识库”。之前正是由于机器没有“知识”,从而无法理解“s12500”是一款“数据中心框式设备”,也无法理解“单板”是“板卡”。但有了“行业知识库”的存在,便可以嫁接语言表达鸿沟,提升语义理解能力。
专业场景的意图识别可以通过基于槽填充的模板解析,本知识库有(“xx本体”-“属于”-“槽”)和(“槽”-“属于”-“意图”)的本体关系。其中“槽”是多个本体的上位概念,比如:“产品类型槽”包含“交换机”、“路由器”、“服务器”、“存储”、“无线”、“操作系统”、“新网络产品”等多个概念。“意图”是多个“槽”的上位概念,比如“产品筛选意图”包含“产品类型槽”、“规格属性槽”、“计算逻辑槽”、“计算单位槽”等多个槽位概念。有了这样的通信行业搜索意图识别模板知识库,在相关专业自然语言搜索前预处理阶段,“命名实体识别”、“槽识别”、“意图识别”等环节一气呵成快速完成。
如果用户提问“某款交换机支持直流供电吗?”,对于传统的FAQ机器人,如果机器人没有记录这条问答对儿知识将无法回答用户问题。而拥有了“常识库”的机器人,他不但能回答这个问题,他还能告诉用户这款交换机的所有特性或者支持直流供电的所有交换机。
随着知识图谱在消费场景的成熟运用,能否赋能工业是对知识图谱提出的下一个任务命题,工业智能化的实现是知识图谱技术的重大使命。网络行业常识库总结了运维知识可用于指导设备级问题故障定位。这些知识包括实体级的。比如“xxx故障怎么排查”。也包括概念级的,即“流程图”本体,通过"iTask"来管理各个流程图实体,"rTaskSameas"管理流程图之间的等价关系,"iTaskNodes"管理每个流程图节点,"rTaskEdges"管理流程关系。该知识库使用者,可以基于这样的额本体定义来填充自己的流程图实例,从而将流程图映射到知识库指导工业推理。
足下起步谋千里之行,工业智能化才是整个行业的愿景,这一愿景的实现离不开整个行业甚至各行各业的支持。新华三集团愿意在这个探索过程中与开源开放世界对话,愿意并持续贡献行业知识,并致敬每一位同路行人!
OpenKG
OpenKG(中文开放知识图谱)旨在推动以中文为核心的知识图谱数据的开放、互联及众包,并促进知识图谱算法、工具及平台的开源开放。
![]()
点击阅读原文,进入 OpenKG 网站。