Git 内部原理之 Git 对象
(点击上方公众号,可快速关注)
来源:彭金金 ,
jingsam.github.io/2018/06/03/git-objects.html
最近在读《Pro Git》这本书,其中有一章讲Git的内部原理,写得非常好,读完之后对于Git的理解会提升到一个新的层次。今后,我会写一系列的关于Git内部原理的文章,以帮助读者加深对Git的认识。内容主要参考《Pro Git》这本书,但不同的是,我会对内容进行重新组织,以使大家更容易理解。
这篇文章的主题的Git对象。
从根本上来讲,Git是一个内容寻址的文件系统,其次才是一个版本控制系统。记住这点,对于理解Git的内部原理及其重要。所谓“内容寻址的文件系统”,意思是根据文件内容的hash码来定位文件。这就意味着同样内容的文件,在这个文件系统中会指向同一个位置,不会重复存储。
Git对象包含三种:数据对象、树对象、提交对象。Git文件系统的设计思路与linux文件系统相似,即将文件的内容与文件的属性分开存储,文件内容以“装满字节的袋子”存储在文件系统中,文件名、所有者、权限等文件属性信息则另外开辟区域进行存储。在Git中,数据对象相当于文件内容,树对象相当于文件目录树,提交对象则是对文件系统的快照。
下面的章节,会分别对每种对象进行说明。开始说明之前,先初始化一个Git文件系统:
$ mkdir git-test
$ cd git-test
$ git init
接下来的操作都会在git-test这个目录中进行。
数据对象
数据对象是文件的内容,不包括文件名、权限等信息。Git会根据文件内容计算出一个hash值,以hash值作为文件索引存储在Git文件系统中。由于相同的文件内容的hash值是一样的,因此Git将同样内容的文件只会存储一次。git hash-object可以用来计算文件内容的hash值,并将生成的数据对象存储到Git文件系统中:
$ echo 'version 1' | git hash-object -w --stdin
83baae61804e65cc73a7201a7252750c76066a30
$ echo 'version 2' | git hash-object -w --stdin
1f7a7a472abf3dd9643fd615f6da379c4acb3e3a
$ echo 'new file' | git hash-object -w --stdin
fa49b077972391ad58037050f2a75f74e3671e92
上面示例中,-w表示将数据对象写入到Git文件系统中,如果不加这个选项,那么只计算文件的hash值而不写入;--stdin表示从标准输入中获取文件内容,当然也可以指定一个文件路径代替此选项。
上面讲数据对象写入到Git文件系统中,那如何读取数据对象呢?git cat-file可以用来实现所有Git对象的读取,包括数据对象、树对象、提交对象的查看:
$ git cat-file -p 83baae61804e65cc73a7201a7252750c76066a30
version 1
$ git cat-file -t 83baae61804e65cc73a7201a7252750c76066a30
blob
上面示例中,-p表示查看Git对象的内容,-t表示查看Git对象的类型。
通过这一节,我们能够对Git文件系统中的数据对象进行读写。但是,我们需要记住每一个数据对象的hash值,才能访问到Git文件系统中的任意数据对象,这显然是不现实的。数据对象只是解决了文件内容存储的问题,而文件名的存储则需要通过下一节的树对象来解决。
树对象
树对象是文件目录树,记录了文件获取目录的名称、类型、模式信息。使用git update-index可以为数据对象指定名称和模式,然后使用git write-tree将树对象写入到Git文件系统中:
$ git update-index --add --cacheinfo 100644 83baae61804e65cc73a7201a7252750c76066a30 test.txt
$ git write-tree
d8329fc1cc938780ffdd9f94e0d364e0ea74f579
--add表示新增文件名,如果第一次添加某一文件名,必须使用此选项;--cacheinfo <mode> <object> <path>是要添加的数据对象的模式、hash值和路径,<path>意味着为数据对象不仅可以指定单纯的文件名,也可以使用路径。另外要注意的是,使用git update-index添加完文件后,一定要使用git write-tree写入到Git文件系统中,否则只会存在于index区域。
树对象仍然可以使用git cat-file查看:
$ git cat-file -p d8329fc1cc938780ffdd9f94e0d364e0ea74f579
100644 blob 83baae61804e65cc73a7201a7252750c76066a30 test.txt
$ git cat-file -t d8329fc1cc938780ffdd9f94e0d364e0ea74f579
tree
上面表示这个树对象只有test.txt这个文件,接下来我们将version 2的数据对象指定为test.txt,并添加一个新文件new.txt:
$ git update-index --cacheinfo 100644 1f7a7a472abf3dd9643fd615f6da379c4acb3e3a test.txt
$ git update-index --add --cacheinfo 100644 fa49b077972391ad58037050f2a75f74e3671e92 new.txt
$ git write-tree
0155eb4229851634a0f03eb265b69f5a2d56f341
查看树对象0155eb,可以发现这个树对象有两个文件了:
$ git cat-file -p 0155eb4229851634a0f03eb265b69f5a2d56f341
100644 blob fa49b077972391ad58037050f2a75f74e3671e92 new.txt
100644 blob 1f7a7a472abf3dd9643fd615f6da379c4acb3e3a test.txt
我们甚至可以使用git read-tree,将已添加的树对象读取出来,作为当前树的子树:
$ git read-tree --prefix=bak d8329fc1cc938780ffdd9f94e0d364e0ea74f579
$ git write-tree
3c4e9cd789d88d8d89c1073707c3585e41b0e614
--prefix表示把子树对象放到哪个目录下。查看树对象,可以发现当前树对象有一个文件夹和两个文件:
$ git cat-file -p 3c4e9cd789d88d8d89c1073707c3585e41b0e614
040000 tree d8329fc1cc938780ffdd9f94e0d364e0ea74f579 bak
100644 blob fa49b077972391ad58037050f2a75f74e3671e92 new.txt
100644 blob 1f7a7a472abf3dd9643fd615f6da379c4acb3e3a test.txt
最终,整个树对象的结构如下图:
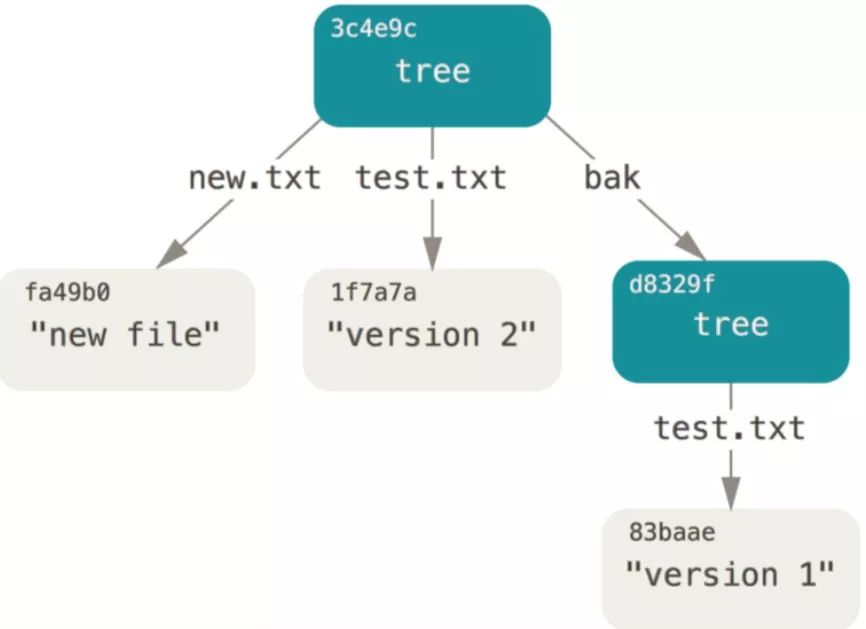
树对象解决了文件名的问题,而且,由于我们是分阶段提交树对象的,树对象可以看做是开发阶段源代码目录树的一次次快照,因此我们可以是用树对象作为源代码版本管理。但是,这里仍然有问题需要解决,即我们需要记住每个树对象的hash值,才能找到个阶段的源代码文件目录树。在源代码版本控制中,我们还需要知道谁提交了代码、什么时候提交的、提交的说明信息等,接下来的提交对象就是为了解决这个问题的。
提交对象
提交对象是用来保存提交的作者、时间、说明这些信息的,可以使用git commit-tree来将提交对象写入到Git文件系统中:
$ echo 'first commit' | git commit-tree d8329fc1cc938780ffdd9f94e0d364e0ea74f579
db1d6f137952f2b24e3c85724ebd7528587a067a
上面commit-tree除了要指定提交的树对象,也要提供提交说明,至于提交的作者和时间,则是根据环境变量自动生成,并不需要指定。这里需要提醒一点的是,读者在测试时,得到的提交对象hash值一般和这里不一样,这是因为提交的作者和时间是因人而异的。
提交对象的查看,也是使用git cat-file:
$ git cat-file -p db1d6f137952f2b24e3c85724ebd7528587a067a
tree d8329fc1cc938780ffdd9f94e0d364e0ea74f579
author jingsam <jing-sam@qq.com> 1528022503 +0800
committer jingsam <jing-sam@qq.com> 1528022503 +0800
first commit
上面是属于首次提交,那么接下来的提交还需要指定使用-p指定父提交对象,这样代码版本才能成为一条时间线:
$ echo 'second commit' | git commit-tree 0155eb4229851634a0f03eb265b69f5a2d56f341 -p db1d6f137952f2b24e3c85724ebd7528587a067a
d4d2c6cffb408d978cb6f1eb6cfc70e977378a5c
使用git cat-file查看一下新的提交对象,可以看到相比于第一次提交,多了parent部分:
$ git cat-file -p d4d2c6cffb408d978cb6f1eb6cfc70e977378a5c
tree 0155eb4229851634a0f03eb265b69f5a2d56f341
parent db1d6f137952f2b24e3c85724ebd7528587a067a
author jingsam <jing-sam@qq.com> 1528022722 +0800
committer jingsam <jing-sam@qq.com> 1528022722 +0800
second commit
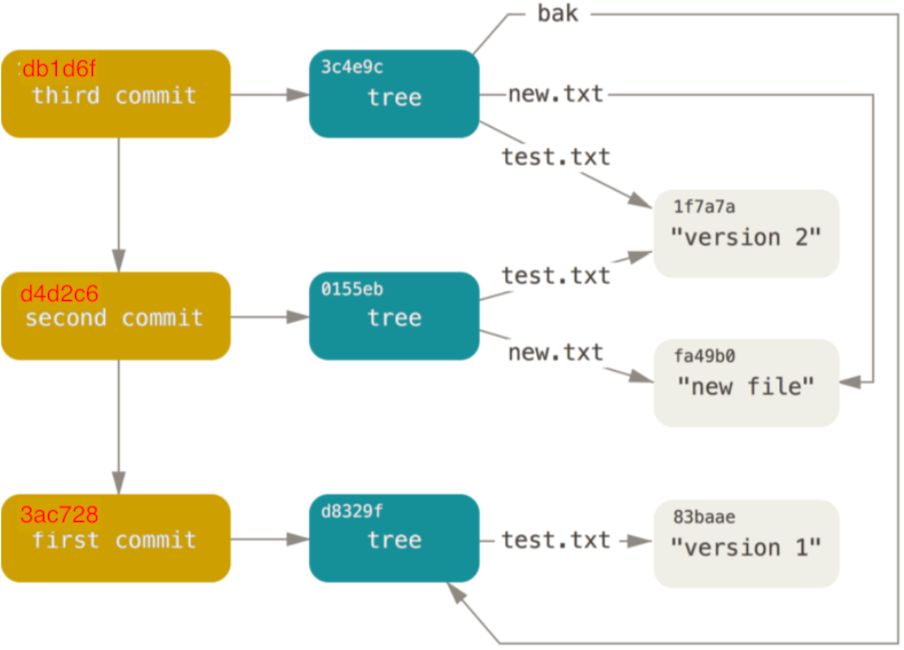
最后,我们再将树对象3c4e9c提交:
$ echo 'third commit' | git commit-tree 3c4e9cd789d88d8d89c1073707c3585e41b0e614 -p d4d2c6cffb408d978cb6f1eb6cfc70e977378a5c
3ac728ac62f0a7b5ac201fd3ed1f69165df8be31
使用git log可以查看整个提交历史:
2 files changed, 2 insertions(+), 1 deletion(-)
commit db1d6f137952f2b24e3c85724ebd7528587a067a
Author: jingsam <jing-sam@qq.com>
Date: Sun Jun 3 18:41:43 2018 +0800
first commit
test.txt | 1 +
1 file changed, 1 insertion(+)
最终的提交对象的结构如下图:
总结
Git中的数据对象解决了数据存储的问题,树对象解决了文件名存储问题,提交对象解决了提交信息的存储问题。从Git设计中可以看出,Linus对一个源代码版本控制系统做了很好的抽象和解耦,每种对象解决的问题都很明确,相比于使用一种数据结构,无疑更灵活和更易维护。每种Git对象都有一个hash值,这个值是怎么计算出来的?Git的各种对象是如何存储的?这些问题将在下一篇文章中讲解。
【关于投稿】
如果大家有原创好文投稿,请直接给公号发送留言。
① 留言格式:
【投稿】+《 文章标题》+ 文章链接
② 示例:
【投稿】《不要自称是程序员,我十多年的 IT 职场总结》:http://blog.jobbole.com/94148/
③ 最后请附上您的个人简介哈~
看完本文有收获?请转发分享给更多人
关注「ImportNew」,提升Java技能