一周目:算法工程师开荒攻略


文章作者:陈然@Tubi
内容来源:比图科技
(Tubi 的产品)
Tubi 的内部系统随着时间发展已经成熟了很多,但大量重要的经验来自于系统搭建的早期。在这篇文章中,我们会分享一些实践的经验。
可能你刚刚作为第一位成员加入一个机器学习的团队,此时你可能会问自己:
“我现在要先做什么呢?我应该立刻直接开始研究最先进的深度/增强学习吗?”
不要,还没有到时候!
测量第一
尽管人人都希望看到东西尽快上线,但是现在研究那些复杂的模型还为时过早。此时更重要的是要搭建一个简单、端到端的实验系统,或者说 A/B 测试系统。
为什么呢?虽然机器学习能够带来非常惊艳的结果,很多时候和魔法无异!但人与人并不相同,对部分人效果好的算法可能对另外一部分人非常糟糕。因此,在新算法直接上线之前,非常有必要通过 A/B 测试来全面了解用户的反馈。
搭建一个基本的 A/B 测试系统并不复杂。现在有大量的开源库和付费的服务,你并不需要一切从头开始搭建。Tubi 早期的 A/B 测试系统也很基础,之后才慢慢成熟。
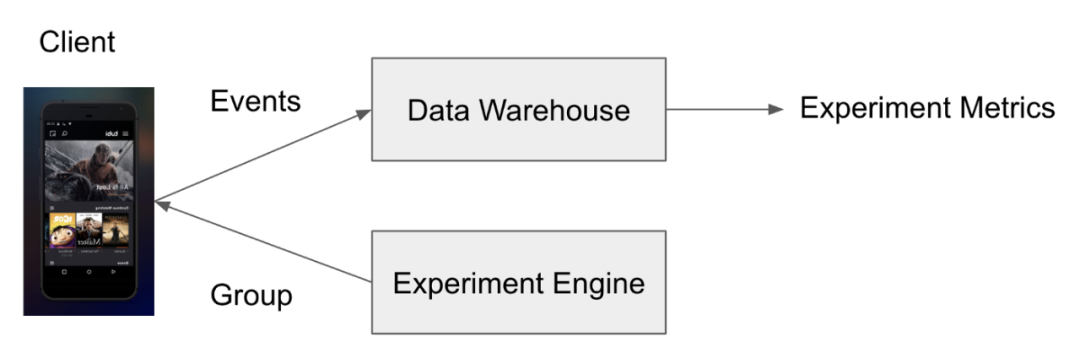
(简单的实验平台)
实验前先定上线计划
拥有一个 A/B 测试系统固然重要,更重要的是如何使用数据进行决策。我们看到的最常见的糟糕实践,就是在实验前没有一份上线计划(Action Plan)。虽然我们并不能预测未来,但这绝不是下面这类发言的借口:
“我们都不知道实验行不行得通,不如我们先上实验,看看结果,再分析一下,看情况决定。”
这是一个很糟糕的想法。如果一直这么做,那总会遇到很多实验部分指标为正,部分指标为负。这种情况下,不同团队的人就会为这些指标争论不休,无法上线。这样的情况有违 A/B 测试的初衷:实验带来更好的决策。
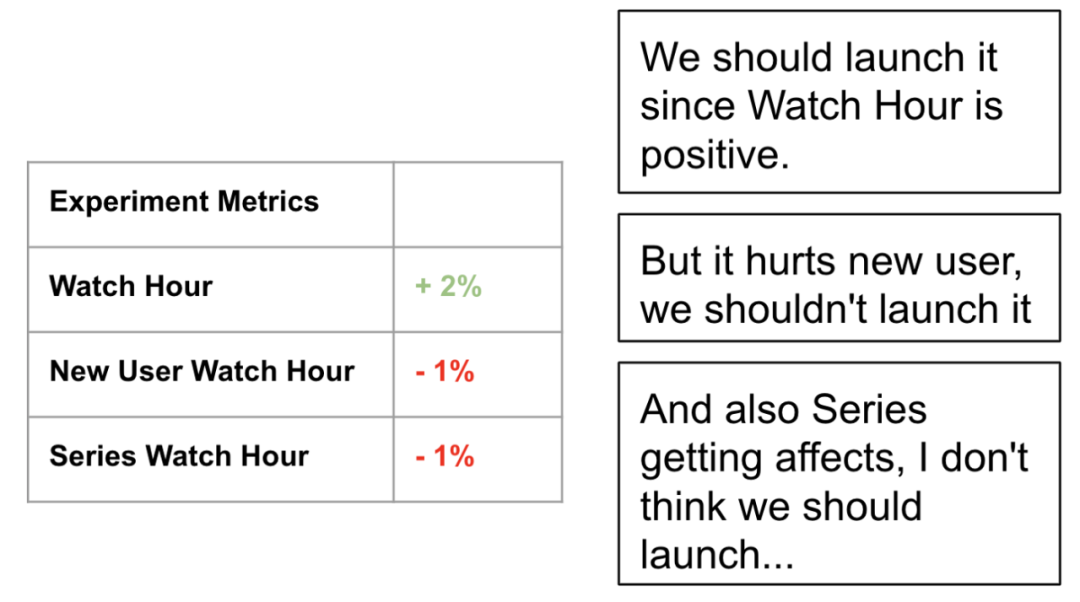
(实验后无止境的争论要不要上线)
解决这个问题的方法其实很简单:
首先制定一到两个决定上线的核心指标,再定一些用于迭代的次要指标;
在实验上线之前集体统一制定一个上线计划。这个上线计划应该非常简单明了:如果核心指标显著正向,或者核心指标中性,次要指标正向,则上线,否则不上线。
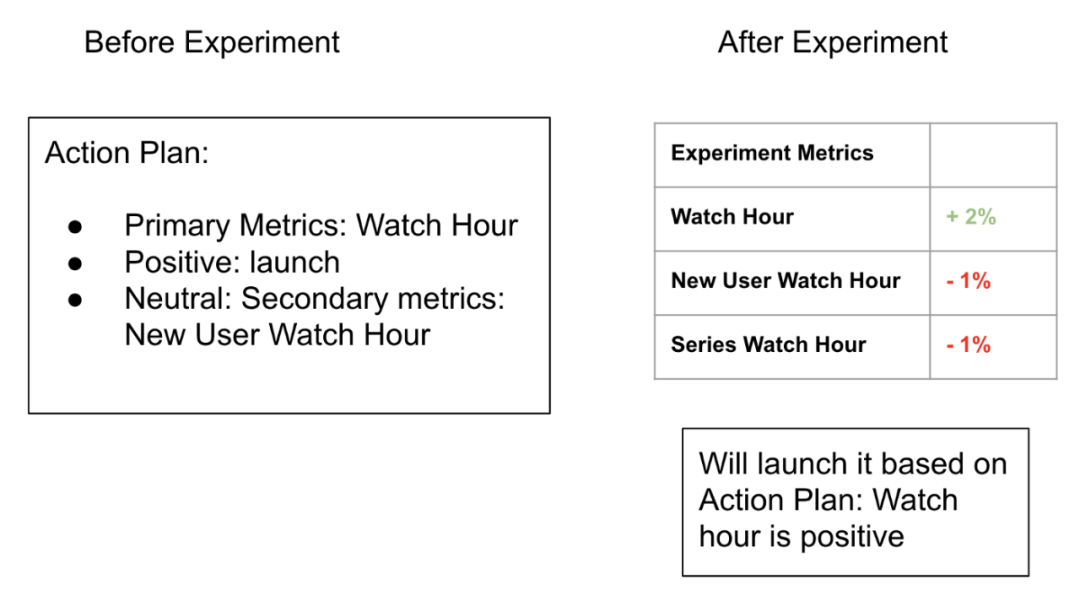
(实验前的上线计划示例)
通过这种方法,我们在实验前就能明确目标。一定上线计划确定,大家不会在实验之后争吵是否应该上线。
简单模型:相似度模型 + 热度模型
在上线了基本的 A/B 测试系统之后,你可能会开始考虑是否需要开始开发复杂的深度学习和增强学习系统。但是,现在依然为时尚早。
既然是团队的首位机器学习工程师,那此时公司其他的数据工程师和后端工程师的配合也一定很少,但需要算法支撑的应用却很多。当我们做这种决策的时候,非常需要计算 ROI (投资回报比)。此时最合适的算法,应该要容易上线,容易维护,并且能带来正向的结果。最好用简单的模型作为开始。
用热度排序
排序无处不在,最简单的一种排序方法,就是用热度排序。
热度的定义有很多种,在 Tubi 最简单的方法就是观看时长,比如一部电影过去一天、三天、七天的观看时长。我们发现使用近期的数据效果往往更好,比如使用过去一天的数据的效果就比过去七天的好。
还有一点很重要,就是在计算热度的时候一定要使用自然产生的热度,要去除因为推广、手动置顶等人工带来的热度,这样的效果往往也更好。
万物皆可 Embedding
另一种排序的方式就是利用 embedding,我们可以为系统中的每一类对象都生成 embedding,再利用相似度排序。用 Tubi 的例子来说:视频是整个生态系统的核心,我们可以首先为视频生成 embedding,再用它来表示其他的对象。
Apache Spark 中自带了两个非常强力的算法:word2vec 和 als (协同过滤),我们可以轻松地使用用户观看历史生成视频的 embedding。
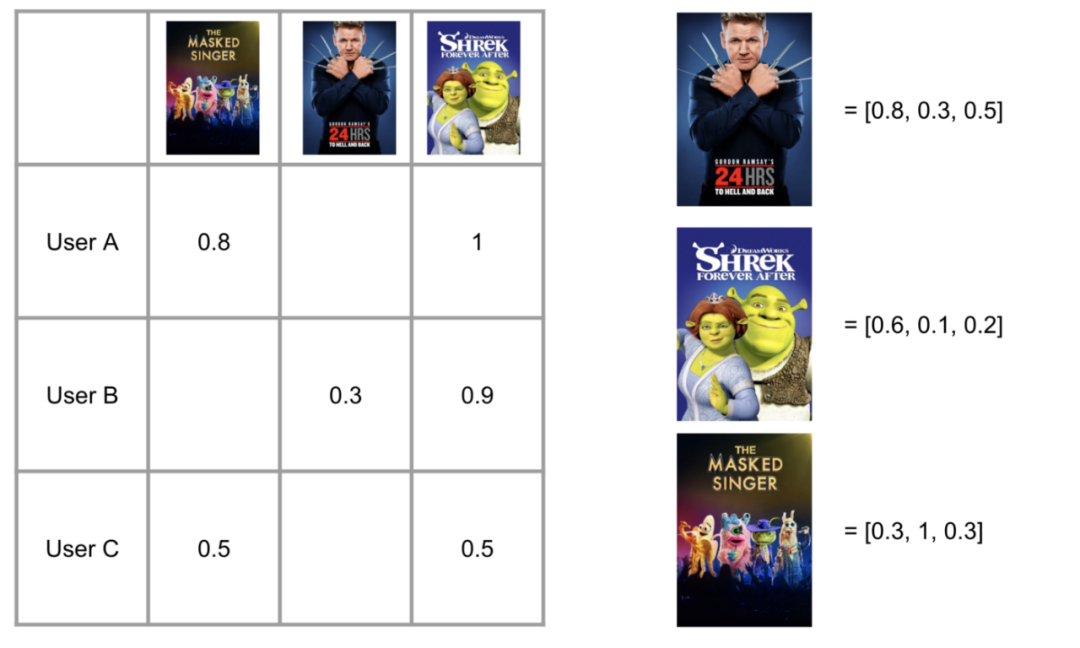
(通过协同过滤抽取视频 embedding)
一旦生成了视频 embedding,我们可以生成其他对象的 embedding。


通过这种方法,我们可以为各种其他的对象生成 embedding,比如用户、平台、邮政编码、电影种类之类的。一旦各种对象都有了 embedding,我们便可以计算余弦相似度了。有了这个相似度,我们便可以计算各类排序问题,比如:用户最喜欢观看的视频、平台、地理位置,或者最相似的城市、平台之类的。
迭代为王
一旦实现了一些基础的算法,你可能会开始尝试一些最领先的技术,比如增强学习之类的。虽然我们也在尝试类似的方向,但我们思考的方式略有不同。我们把更多的时间和精力都放在了另一个方向上:如何让迭代更快。我们发现快速的迭代收益最大。
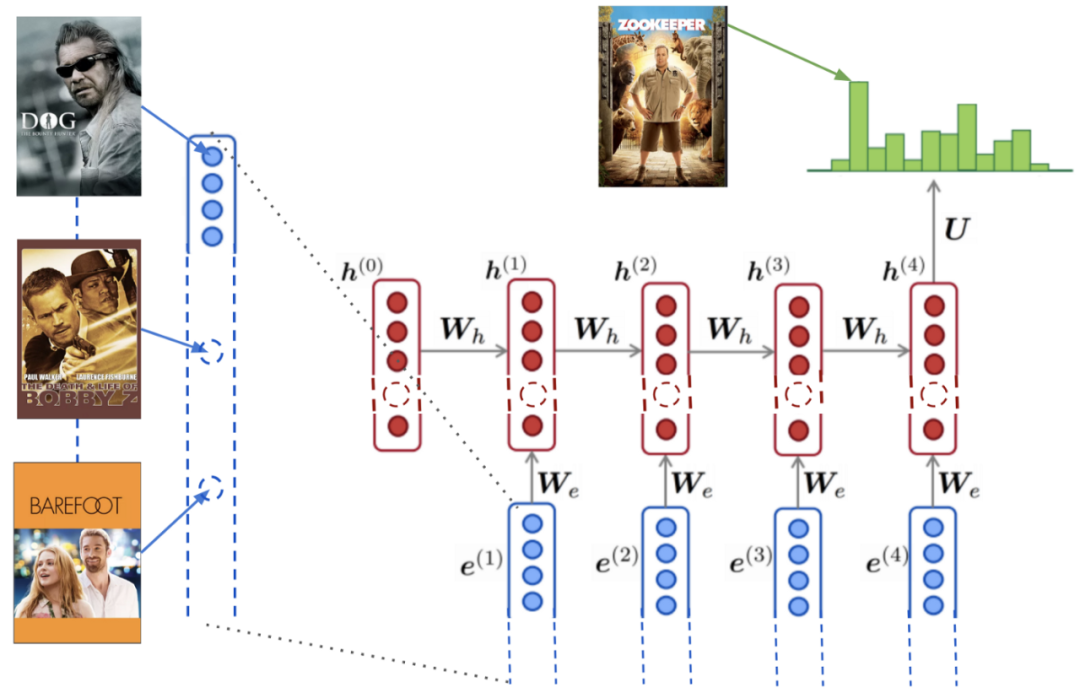
(在电影推荐中使用LSTM)
在机器学习的世界中有太多的想法和直觉了。我们都可以轻松地提出几十种值得尝试的方向:更多的特征、更深度的模型、不同的召回模型、不同的分层抽样、多目标优化、探索与利用等等。我们在做这些选择的时候需要考虑投资回报比,我们很容易估算成本,但是计算回报却很困难。
除非我们有很多先验知识,否则我们很难估算回报。然而,根据我们的实践,每个公司的问题都不太一样,其他公司中的最佳实践并不一定可以被轻易的迁移过来。我们需要一种方法来在公司内部积累经验:越多越好,越快越好。
在 Tubi 的实践中,我们让 A/B 测试的上线极度简单。我们机器学习算法的迭代计划几乎完全依赖我们从各类实验中获得的观察。在早期我们只有两到三名同学迭代核心算法的时候,我们可以做到一年至少上线 50 个实验。每一个实验都包含了全部的步骤:算法探索、实现、A/B 测试、最后的演讲和论文的撰写。基本不需要其他组的协助。
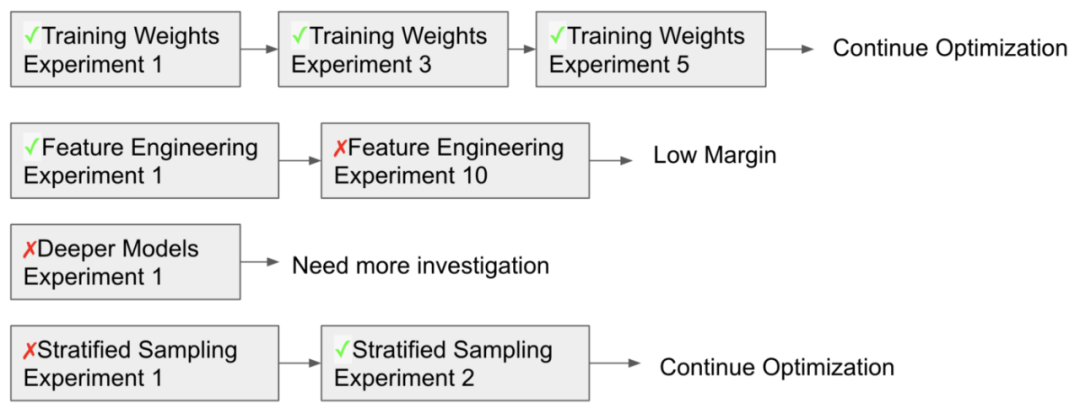
(利用实验来确定迭代的路线)
总结
在过去的几年中,我们积累了很多关于如何打造一个快速迭代的机器学习系统的经验。我们会在接下来的时间与大家分享。如果你对于通过实验迭代算法这个思路也充满激情,欢迎加入我们!
Tubi 拍了拍你,邀请你加入我们的大家庭!
目前开放的职位:
高级数据开发工程师
高级机器学习工程师
高级后端工程师 - Elixir 方向
高级后端工程师 - Scala 方向
高级 Android 工程师
高级 iOS 工程师
高级前端工程师
高级前端工程师 - 多媒体方向
高级 QA 工程师
更多职位细节请点击我们的官方网站:http://chinateam.tubi.tv/,或在 Boss 直聘搜索“比图科技”访问我们的招聘主页。
今天的分享就到这里,谢谢大家。
在文末分享、点赞、在看,给个3连击呗~
大数据架构论坛报名
12月19日,09:00-12:40,在DataFunTalk年终大会大数据架构论坛上,来自Tubi的资深数据工程师沈达老师将分享《Data Quality Architecture in Tubi》,感兴趣的小伙伴欢迎识别海报中的二维码报名:

文章推荐:
社群推荐:

关于我们:
DataFunTalk 专注于大数据、人工智能技术应用的分享与交流。发起于2017年,在北京、上海、深圳、杭州等城市举办超过100场线下沙龙、论坛及峰会,已邀请近600位专家和学者参与分享。其公众号 DataFunTalk 累计生产原创文章300+,百万+阅读,9万+精准粉丝。

🧐分享、点赞、在看,给个3连击呗!👇




