7 Papers | KDD2019最佳论文;AutoML SOTA 综述
机器之心整理
本周的看点是 KDD 2019 大会,分别有两篇研究赛道和应用赛道最佳论文被选入。 本周入选的其他论文都有架构或研究方法上新颖的点,如 CMU、加州大学圣迭戈分校等的基于语义的相似性的机器翻译论文、乔治亚理工联合 Facebook 和俄勒冈州立大学提出的多模态 BERT 模型等、提出反向传播替代方法 HSIC 瓶颈的论文等。
Network Density of States
Actions Speak Louder than Goals: Valuing Player Actions in Soccer
Beyond BLEU: Training Neural Machine Translation with Semantic Similarity
The HSIC Bottleneck: Deep Learning without Back-Propagation
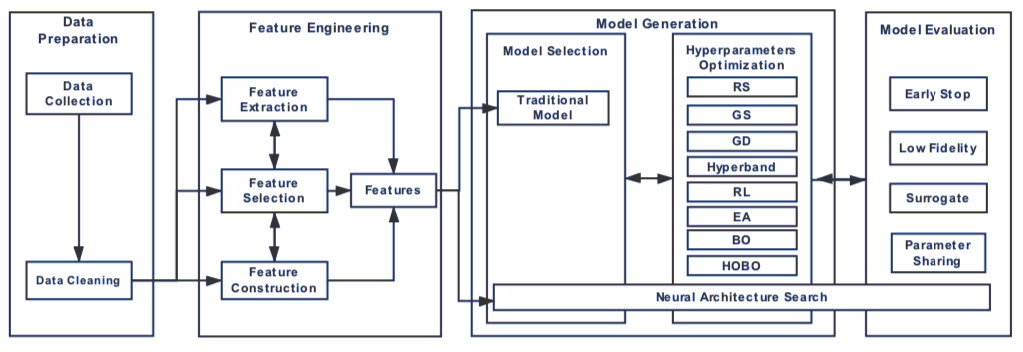
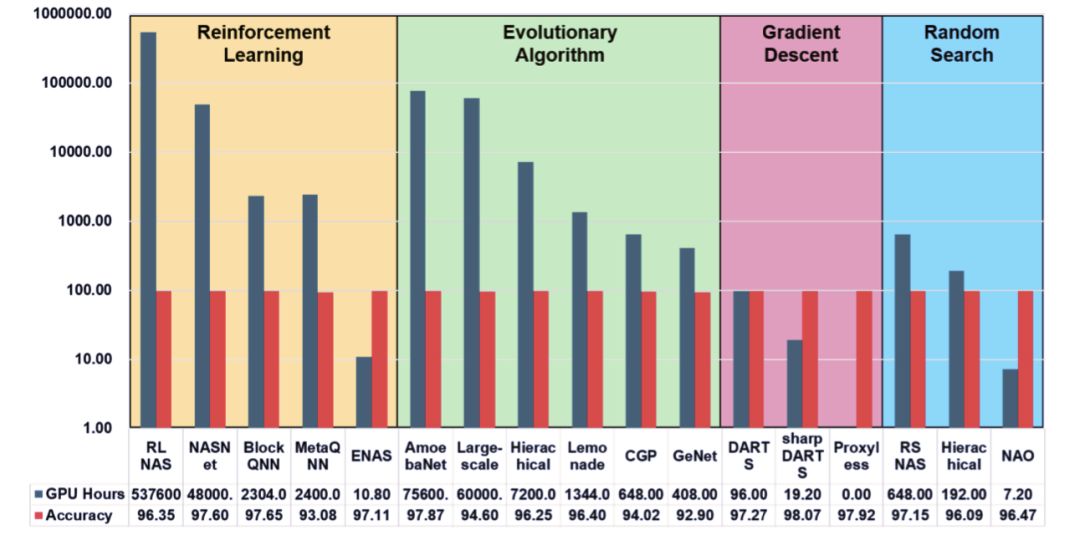
AutoML: A Survey of the State-of-the-Art
ViLBERT: Pretraining Task-Agnostic Visiolinguistic Representations for Vision-and-Language Tasks
Trick Me If You Can: Human-in-the-Loop Generation of Adversarial Examples for Question Answering
作者:Kun Dong、Austin R. Benson、David Bindel
论文链接:https://arxiv.org/pdf/1905.09758.pdf
作者:Tom Decroos、Lotte Bransen、Jan Van Haaren、Jesse Davi
论文链接:https://arxiv.org/pdf/1802.07127.pdf
作者:John Wieting、Taylor Berg-Kirkpatrick、Kevin Gimpel、Graham Neubig
论文链接:https://www.aclweb.org/anthology/P19-1427

作者:Wan-Duo Kurt Ma、J.P. Lewis、W. Bastiaan Kleijn
论文链接:https://arxiv.org/pdf/1908.01580v1.pdf
作者:Xin He、Kaiyong Zhao、Xiaowen Chu
论文链接:https://arxiv.org/pdf/1908.00709v1
作者:Jiasen Lu、Dhruv Batra、Devi Parikh、Stefan Lee
论文链接:https://arxiv.org/pdf/1908.02265.pdf

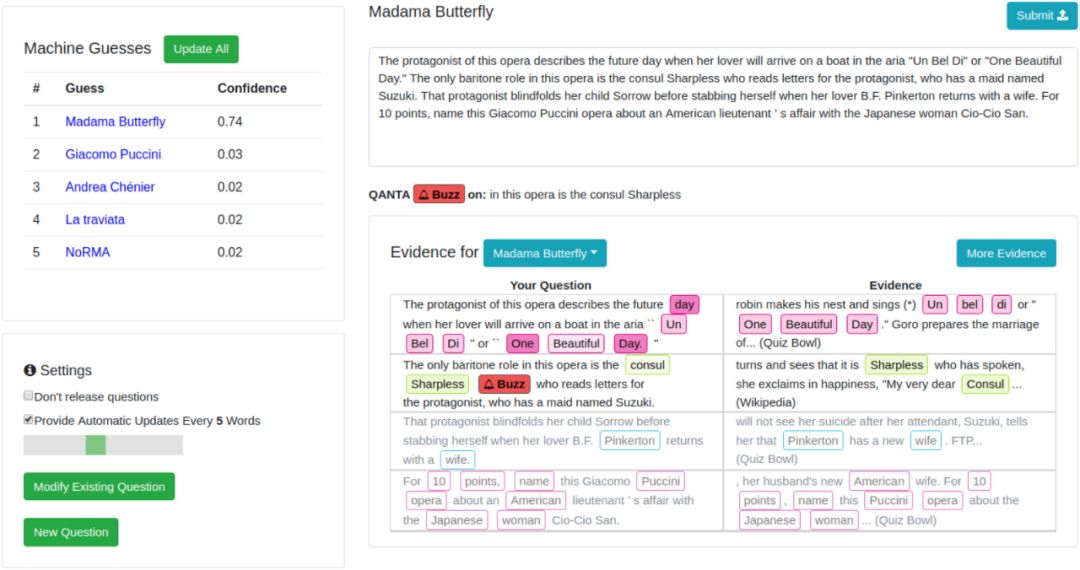
作者:Eric Wallace、Pedro Rodriguez、Shi Feng、Ikuya Yamada、Jordan Boyd-Graber
论文链接:https://doi.org/10.1162/tacl_a_00279
项目链接:https://github.com/Eric-Wallace/trickme-interface/