| 极市线上分享 第89期 |
一直以来,为让大家更好地了解学界业界优秀的论文和工作,极市已邀请了超过100位技术大咖嘉宾,并完成了88期极市线上直播分享。往期分享请前往bbs.cvmart.net/topics/149或直接阅读原文,也欢迎各位小伙伴自荐或推荐更多优秀的技术嘉宾到极市进行技术分享,与大家一起交流学习~~
承办单位:中国图象图形学学会青年工作委员会
会议地点:线上会议
会议时间:2021年12月11日-13日
线上直播地址:
http://live.bilibili.com/3344545
(极视角直播平台)
大会主席:
2. 登录会议官网:http://youth.csig.org.cn/csig2021/index.html完成注册及交费
3. 请注册时候,在会议官网填写好发票单位名称、税号、邮箱等相关信息,以便发送电子发票,发票事宜的相关咨询请发邮件至:info@csig.org.cn。
![]()
2021中国图象图形学学会青托沙龙日程安排(线上)
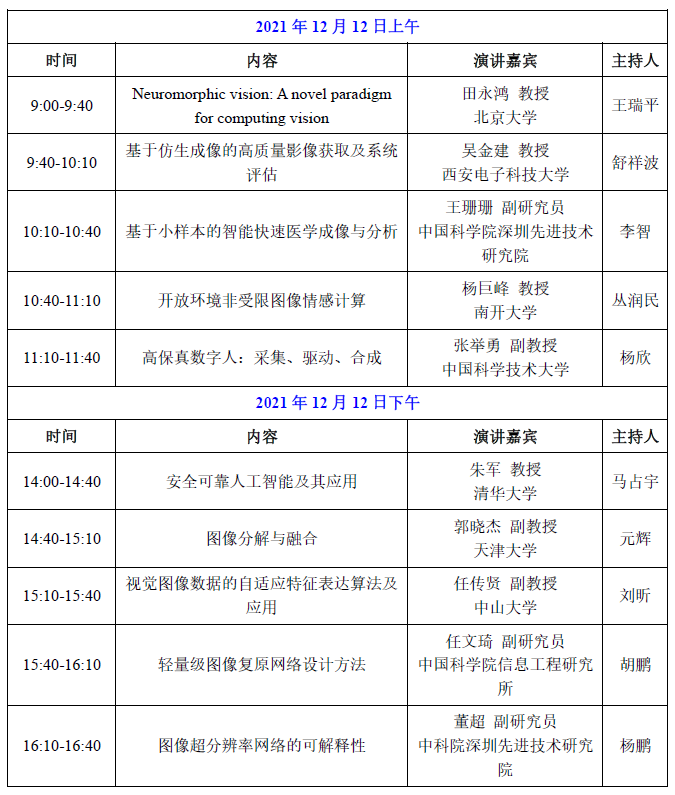
2021年12月11日上午
报告1
![]()
演讲嘉宾:周昆 浙江大学
报告题目:从计算机图形学到智能图形学
报告简介:上世纪六十年代,集成电路计算机开始走向通用化和商业化,用计算机来画图和生成图形图像成为计算机学科与产业发展的重大挑战,计算机图形学由此蓬勃发展起来,成为信息产业的核心支撑技术。进入人工智能时代,面向智能终端、智能系统和智能制造等新兴产业需求,图形学与人工智能技术的深度融合创新成为学科发展的新趋势。本次报告将首先回顾计算机图形学的起源和发展,然后介绍近年来本团队融合图形学和人工智能技术在三维重建、人脸动画和三维打印方向取得的科研进展。
个人简介:
周昆,浙江大学计算机学院教授,国际计算机学会会士(ACM Fellow),国际电气与电子工程师协会会士(IEEE Fellow)。2002年获浙江大学工学博士学位,2007年入选教育部长江学者特聘教授,2008年获得国家杰出青年科学基金,现任浙江大学计算机辅助设计与图形学国家重点实验室主任。研究领域为计算机图形学、计算机视觉、人机交互和虚拟现实。在ACM/IEEE Transactions上发表论文100余篇,获发明专利60余项。曾获得国家自然科学二等奖、陈嘉庚青年科学奖、中国青年科技奖、MIT TR35 Award等国内外奖项。现任学术期刊《Visual Informatics》创刊主编,现/曾担任ACM TOG、IEEE TVCG、IEEE CG&A等期刊编委。
![]()
报告简介:深度神经网络在图像理解、语音识别、自然语言处理等人工智能应用领域取得了令人瞩目的成就,成为人工智能研究的热点之一。然而,随着网络性能的不断提高,网络的深度和广度也在不断增加,这就大大增加了网络的参数和计算复杂度。如何压缩和加速这些大的神经网络模型成为学术界和工业界研究的热点。针对神经网络的加速和冗余度问题,本次报告简要介绍已有的加速和压缩方法并在其中覆盖纪荣嵘教授研究组近几年来在神经网络压缩与加速中所做的一些工作与成果。
个人简介:纪荣嵘,厦门大学南强特聘教授,国家杰出青年科学基金获得者。主要研究方向为计算机视觉。近年来发表TPAMI、IJCV、ACM汇刊、IEEE汇刊、CVPR、NeurIPS等会议长⽂过百篇。论文谷歌学术引用万余次。曾获2016年教育部技术发明一等奖、2018年省科技进步一等奖、2019年福建省青年科技奖。曾/现主持国防973项目,国家自然科学基金联合重点基金等项目。任中国计算机学会A类国际会议CVPR和ACM Multimedia领域主席、中国图象图形学学会学术工委副主任、教育部电子信息类教指委人工智能专业建设咨询委员会委员。
![]()
报告简介:基于深度学习的感知与理解模型通常依赖于大量的标注数据针对应用场景进行训练。然而对数据进行手工标注需要耗费大量的时间和人力成本。这造成了模型广泛部署应用的一大阻碍,也同时成为了人脑智能和机器智能的一大区别。为此, 我们研究如何能够在标注受限的条件下,少利用乃至不利用手工标注数据,来进行模型的有效训练和学习。从而一方面缓解手工标注带来的难题;另一方面,赋予机器自动地从场景中挖掘获取信息的能力,使得机器在宏观的行为能力方面与人脑智能更加接近。本次报告将从受限标注这一角度展开,结合域自适应、弱监督、半监督、自监督等范式,探讨如何针对场景的感知与理解这一任务进行信息的自动挖掘和模型的学习训练。
个人简介:张兆翔,博士,中国科学院自动化研究所研究员、博士生导师,中国科学院大学教授,中国科学院脑科学与智能技术卓越创新中心骨干,入选“教育部长江学者特聘教授”、“国家万人计划青年拔尖人才”,研究方向包括:物体检测与分割,视觉认知计算,类脑智能等,担任或曾担任 IEEE T-CSVT、Patten Recognition、NeuroComputing 编委(Associate Editor),是 CVPR、ICCV、AAAI、IJCAI、ACM MM、ICPR、 ACCV 等国际会议的领域主席(Area Chair)。
![]()
演讲嘉宾:左旺孟 哈尔滨工业大学
报告题目:面向低标注成本和非理想监督的深度网络学习方法初探
报告简介:当前深度学习的成功仍主要建立在大规模标注数据和模型算法的基础上。虽然大规模数据获取已经较为容易,数据的精细化标注仍然会耗费大量的人力物力。近年来涌现的弱监督、噪声标注和小样本学习等面向低标注成本的深度网络学习方法仍较为依赖人为设计,缺乏统一的形式和原则。因此,报告从知识提取和知识蒸馏的角度出发分析了低成本标注学习问题,为弱监督语义分割和物体检测提供了新的角度和解决方案。其次,针对真实图像去噪、图像去模糊/超分辨等问题,往往不能获得理想的监督信息,能够获得替代监督信息与理想监督相比可能会呈现时空域未配准、颜色/模糊程度不一致等特点。为此,报告以人脸正面化和Raw图ISP和超分为例,介绍了颜色不一致和空域未配准情况下深度网络的有效学习方法。
个人简介:左旺孟,哈尔滨工业大学计算学部教授、博士生导师,机器学习研究中心执行主任。主要研究方向包括非理想监督学习方法及其在图像增强与复原、图像编辑与生成、物体检测和图像分类等领域的应用。在CVPR/ICCV/ECCV等顶级会议和T-PAMI、IJCV及IEEE Trans.等期刊上发表论文100余篇。曾任ICCV2019、CVPR2020/2021等CCF-A类会议领域主席,现任IEEE T-PAMI和T-IP等期刊编委。
![]()
报告简介:The development of machine learning algorithms and 2D/3D sensors have substantially improved the efficiency and quality of 3D content creation. This talk will discuss the advantage of data-driven content creation, which can leverage deep learning models learned from captured data to boost the performance of 3D content understanding and generation. It will cover our recent work on 3D environment creation for AR/VR applications、physics-based motion generation and how the created content can help to improve the accuracy of computer vision tasks.
个人简介:现任浙江大学CAD&CG国家重点实验室百人计划研究员。曾任日本立命馆大学博士后,微软亚洲研究院网络图形组研究员, 杭州师范大学浙江省钱江学者特聘教授。主要研究方向为计算机图形学、三维重建、深度学习、物理仿真及3D打印。在国内外高水平学术会议和期刊发表论文80余篇,其中ACM Transactions on Graphics, IEEE TVCG, 及IEEE CVPR等CCF-A类论文20余篇。获中国和美国授权专利15项。所开发的三维注册和重建技术在高精度扫描仪及人体三维重建系统中得到应用。2014年受国家自然科学基金优秀青年基金资助,主持国家自然科学基金重点项目一项,获浙江省自然科学二等奖一项。
2021年12月11日下午
![]()
报告简介:
本报告将介绍嵌入式处理系统的任务及边缘端设备对智能在线自主学习提出的更高需求,分析深度学习应用在面向目标检测&跟踪任务的智能边缘计算中存在的局限性。报告还将介绍轻量化目标检测&目标跟踪的研究现状,并结合当前主流的智能边缘系统架构分析在线自主学习、轻量化目标检测&跟踪的整体框架的设计方法。最后将分享边缘端在线自主学习的应用成果,及未来边缘计算的发展方向和发展前景。
个人简介:
张弘,北京航空航天大学教授,博导,主要研究领域为人工智能、模式识别、图像分析及处理和计算机视觉,具体包括1)复杂背景下目标自动检测、识别与精确跟踪技术 2) 多模图像智能匹配与融合及协同技术以及3)图像增强和图像复原技术等。张弘教授近年承担了国家科技部重大专项、重点研发、国家自然基金、总装预研等项目50多项;指导硕士研究生、博士研究生60多人;在TIP、PR等高水平期刊和会议上发表论文100余篇;出版国家规划级教材两本;相关成果获得了56项发明专利授权;研发了察打、预警、搜救、安防等28型光电探测系列装备,已广泛应用于国防、边海防、特种安防等领域。张弘教授曾获得国家科技进步二等奖、教育部技术发明一等奖、国防科技进步三等奖,北京市科学技术三等奖等,是北京市E-health信息处理国际合作基地的负责人。她还曾担任国家自然基金、北京市自然基金等多个基金评委,科技部重大专项、教育部、北京市科技奖等评审专家;军口专家及多个相关国际会议的程序委员,及多个国际刊物的评审专家。
![]()
报告简介:
医学影像检测与分割是临床应用中的关键技术。然而,医学影像检测分割任务中往往面临“标注噪声大、训练样本少、背景干扰大”等挑战,导致面向医学图像检测与分割的图像特征学习难、区分性差、鲁棒性低。本报告将介绍如何结合医学解剖结构等先验和约束,解决医学影像检测与分割中的特征学习难问题。具体介绍以下工作:1)基于医学领域知识及结构先验的多目标对齐及特征解耦,有效抑制背景噪声干扰,提升小样本下目标检测精度;2)结合噪声感知的标签软化方法及边界相似性函数,用于提升噪声标注下目标边界的分割精度;3)结合医学先验信息的图像合成方法,针对双视角乳腺钼靶影像病灶检测与匹配任务进行训练样本扩增,有效提升病灶检测与匹配精度。
个人简介:杨欣,博士,2013年获得加州大学圣塔芭芭拉分校博士学位。现任华中科技大学电信学院教授,主要从事医学影像分析与计算机视觉领域研究工作,已在国际权威期刊及学术会议上发表学术论文90余篇,授权美国/中国发明专利6项,出版英文书籍章节2部;获得中国图象图形学学会石青云女科学家奖,国家自然科学基金优秀青年基金资助;担任SCI期刊IEEE-TMI及Multimedia System编委及ACM MM2018和MICCAI2019-2021领域主席;现任CSIG青工委副秘书长,CCF多媒体专委会副秘书长等。
![]()
报告简介:
在AI技术蓬勃发展的今天,大部分研究都是以人的视角展开设计,从人的需求出发,以及围绕人的思维习惯等进行展开,因此人始终站在智能理解和交互的中心位置。本报告针对音视频相互之间的关联特性,通过对音视频中的不同视角、不同模态信息进行挖掘和建模,总结有监督、自监督、弱监督等学习模型实现不变视角行为识别、视频中视觉信息指导的音频分离、音视频目标定位、多模态情感识别等以人为中心的理解任务,探讨未来更有意义的研究趋势。
个人简介:姬艳丽,副教授,博导,研究方向为面向机器人应用的人机交互技术,包括自然场景下的人体行为识别、人的骨架提取、音视觉多模态信息理解、情感认知等。发表TIP,TMM,TCSVT,PR,Signal processing, CVPR,ACM MM等SCI期刊论文及高水平国际会议论文,申请近三十项发明专利。获得28th Australasian Database Conference国际会议Best Paper Award,第二十届中国虚拟现实大会最佳论文提名奖。主持国家自然科学基金青年项目和面上项目,主持和参与十多项国家级、省部级、知名企业横向项目。多次参与承办国际会议和国内学术峰会,学术活动包括国际会议ACMMM2021,ICME Registration Chair,国内学术峰会Conference Secretary of VALSE 2015、workshop chair of VALSE 2018,poster chair of VALSE 2019 和Program Chair of ACM SIGAI CHINA symposium in TURC, 2017,2018等,Local Chair of TURC 2019。中国图象图形学学会青年工作委员会执行委员、副秘书长,VALSE委员会SAC副主席。CVPR,AAAI,ICCV,IJCAI,ECCV,PRCV等领域会议PC/TPC,TPAMI,TIP,TNNLS,TMM,PR等期刊审稿人。
![]()
报告简介:
在迪士尼、皮克斯等主流动画工作室,动画师通常基于窗口、图标、菜单和指示设备(WIMP)交互界面,运用 Maya,Houdini 等商业软件制作动画过程复杂、成本高昂。尤其在VR动画制作中,360°全景空间任何一点都可以成为观众观看的视点,传统动画采用镜头组接的制作方法已不再适合。申请人运用混合现实技术突破了传统基于WIMP动画制作交互界面不直观的问题,另外,针对3D智能角色呈现,从算法层面解决了2D屏幕固有的深度信息失真的难题,无需眼镜或其它复杂设备辅助,提高了用户与3D智能角色交互体验。
个人简介:
潘烨,上海交通大学电子信息与电气工程学院,长聘教轨副教授、博士生导师。伦敦大学学院计算机学院博士/硕士,电子科技大学/普渡大学信息与通信工程学院本科。曾任伦敦大学学院高级博士后研究员,美国洛杉矶迪士尼研究院副研究员。因在虚拟角色,包括混合现实环境中3D角色交互技术、虚拟现实环境中化身、新型远程呈现系统及交互技术三个方面的贡献,分别于2019年入选《福布斯中国30位30岁以下(科学)精英榜》,2020年以最年轻的上榜者入选《福布斯中国科技女性榜》。
2021年12月12日上午
报告10(Keynote报告)
![]()
报告题目:Neuromorphic vision: A novel paradigm for computing vision
报告简介:
How to effectively represent and process visual information is the fundamental problem of computing vision. In the existing technological framework, visual information is usually organized into frame-by-frame images, or a video sequence. The image frames or video thus become the basic unit of visual information representation and processing. However, with the rapid growth of visual data and the continuous emergence of high-speed imaging applications, the traditional visual information representation and processing framework based on image frames is facing great challenges. Based on the fact that the biological prototype of cameras is the retina, we thus should learn from the structure and mechanism of biological retina to re-visit the theory and methods of visual information representation and processing suitable for new types of imaging applications. Along with this idea, neuromorphic vision is developing recently to create computing vision algorithms and systems that mimic biological nervous systems to represent and process visual information. Thus, this talk will present the concept, related research problems, and some recent developments of neuromorphic vision.
个人简介:田永鸿,北京大学博雅特聘教授,博士生导师,IEEE Fellow,鹏城国家实验室网络智能部副主任兼云脑研究所所长,鹏城云脑技术总师,2018 年国家杰出青年基金获得者。主要研究方向为分布式机器学习和类脑计算。累计主持国家重点研发计划项目、国基金杰青/重点/重大仪器项目等国家、省部级与企业合作项目40 余项,在IEEE TPAMI/TIP/TNNLS/TYB/TMM/TCSVT/TKDE/TNSE、ACM CSUR/TOMM/ TOIS、Cerebral Cortex、IJCV、Patt. Recog.等期刊和NeurIPS/ICCV/CVPR/IJCAI/ AAAI/ECCV/ACM MM等会议发表学术论文250余篇,两获国际期刊和会议最佳论文奖;拥有美/中国发明专利90项,获国家技术发明二等奖1次、国家科技进步二等奖1次、教育部科技进步一等奖1 次、中国电子学会技术发明一等奖和自然科学二等奖各1次,是首届高校计算机专业优秀教师奖励计划获奖者。曾任国际期刊IEEE TCSVT/TMM/Multimedia等期刊编委,IEEE MIPR2020/ICME2021大会主席,IEEE ICME2015/BigMM2015/ISM2015/ MIPR2018/MIPR2019程序主席,现任香港中文大学(深圳)和华中科技大学兼职教授、IEEE数据压缩标准委员会副主席兼IEEE 2941标准工作组组长、中国图象图形学学会理事与交通视频专委会副主任等。他是科技部十四五重点专项“智能传感器”专家组成员。
![]()
报告简介:
高质量影像数据是我们认知世界的重要手段。面对远距离、高速运动、遮挡隐匿的目标探测挑战,如何能看得清、抓得住、辨得明,是当前面临的巨大挑战。针对该难题,受生物视觉系统的启发,课题组研发了一款基于能量差分成像的新体制仿生事件相机,颠覆传统基于能量积分的成像模式,具有对运动目标敏感、成像动态范围大、数据率低、系统功耗低等特点。进一步的,面向认知需求,探索成像质量评估及系统优化技术。借鉴大脑内在推导感知机制,课题组探索了视觉内容质量衰减的内在成因,首次提出图像结构复杂度定量计算方法,揭示人眼对图像内容变化的辨识能力,构建脑启发式客观质量评价方法,从而实现成像系统性能评估与优化。
个人简介:吴金建,男,现为西安电子科技大学教授、博导,国家优青。分别于2008年、2014年获得西安电子科技大学学士、博士学位,2019年破格晋升教授。2011年9月至2014年8月,赴新加坡南洋理工大学从事助理研究员、博士后研究员工作。获国家自然科学奖二等奖、陕西省自然科学奖一等奖、陕西省青年拔尖人才、教育部霍英东青年基金等。面向人工智能国家战略及重大需求,长期从事仿生成像、智能信号处理等方面的理论和应用研究。主持军科委国防创新项目、国家自然基金、教育部与装备发展部联合基金青年人才项目等多项课题,协同主持国家自然基金重点项目、十三五航天预研等项目,开发出多套智能信息处理系统并交付使用。已发表相关学术论文80余篇,其中一区期刊或A类会议论文30余篇,三篇入选ESI高被引论文,获IEEE电路与系统旗舰会议ISCAS2013“最佳学生论文奖”、国际人工智能大会CICAI2021“最佳学生论文提名奖”等。
![]()
报告简介:
近年来以深度学习为代表的人工智能技术在众多领域中取得突破。然而基于强监督的深度学习方法无法满足许多应用领域的需求,特别是在数据量少、保密性要求高、标注昂贵的医学影像数据中。发展少样本甚至零样本的方法具有极大的应用价值,这类方法目前的发展关键在于缺乏可解释性、经验一致性、针对性和可泛化性等。本报告利用数学理论,研究数据与模型混合驱动的特征生成方法,在小样本条件下的磁共振医学影像的重建和分析任务中做了一系列推导和验证。实验结果显示了数据与模型混合驱动方法在医学数据中的应用潜力。
个人简介:
王珊珊,双博士,博士生导师。研究方向机器学习、快速医学成像、放射组学等, 迄今为止在Nature communications、IEEE Trans TMI/TBME/TIP、MICCAI等顶级期刊与会议发表英文学术论文50多篇,ESI 高被引2篇,PMB年度亮点文章1篇,发明授权专利9项,4项实现规模化产业应用。快速医学成像获广东省科技发明一等奖,影像组学定量分析工作获广东省科技进步一等奖。并获2018海外华人磁共振协会OCSMRM杰出研究奖(Outstanding Research Award),2020吴文俊人工智能优秀青年奖,2021年深圳市青年科技奖,澳大利亚John Make peace Bennett最佳博士论文提名奖,IEEE Senior member,OCSMRM BoT/Life member, Gordon Plenary Lecturer, NIBIB New Horizontal Lecturer。
![]()
报告简介:
视觉是人类感知、表达和传递情感的重要途径。与经典的人脸表情识别任务不同,广义图像情感计算涉及的对象更复杂,面临的挑战也更多。从图像情感的抽象性、主观性、模糊性等特点出发,我们在情感区域检测、情感类别辨识、情感分布度量、情感图像检索、多模态情感感知等方面做了一些初步探索,部分地解决了开放环境非受限图像情感计算的难题。
个人简介:
杨巨峰,南开大学计算机学院教授,入选天津杰青、南开百青。研究方向是计算机视觉、机器学习、多媒体计算,发表PAMI/CVPR等高水平学术论文50余篇。任中国计算机学会计算机视觉专委会副秘书长,中国计算机视觉大会(CCCV 2017)组织主席。研究成果获第十届吴文俊人工智能自然科学二等奖。
![]()
报告简介:
对物理世界中场景与人的高效高保真三维数字化是计算机图形学、三维视觉等领域中的核心问题,相关算法与技术也有效支撑了众多虚拟现实与增强现实应用。在本次报告中,我将汇报课题组在高效高保真虚拟数字人构建方面的研究工作,包括基于单目/双目相机的深度估计、基于优化与深度学习算法的刚性与非刚性配准、三维人脸表情捕捉与人体动作捕捉,及其在语音驱动数字人、沉浸式视频会议系统等方面的应用。
个人简介:
张举勇,中国科学技术大学数学科学学院副教授,博士生导师。2011年获新加坡南洋理工大学计算机工程学院博士学位,2011年至2012年于瑞士联邦理工学院洛桑分校从事博士后研究,2012年至今工作于中国科学技术大学。研究兴趣包括计算机图形学、三维视觉与数值最优化算法,近期研究兴趣为采用与设计基于数值优化与深度学习的算法对场景、人进行高效高保真三维数字化。发表IEEE TPAMI, ACM TOG, CVPR/ICCV等CCF A类论文三十余篇,担任IEEE Transactions on Multimedia, The Visual Computer期刊编委。
2021年12月12日下午
报告15(Keynote报告)
![]()
报告简介:
随着人工智能技术越来越广泛地应用于金融、工业等真实开放的环境,其安全性和可靠性面临着新的挑战和更高要求,例如:人脸识别、自动驾驶等系统被对抗样本攻破;隐私数据在使用过程中面临泄露风险等。该报告将从数据安全和算法安全的角度,介绍安全人工智能的技术进展,并结合金融场景介绍具体的实践案例,具体包括RealSecure隐私保护机器学习、算法的对抗攻防技术以及深度伪造视频的自动检测等。
个人简介:朱军,清华大学计算机系教授、人智所所长,北京智源人工智能研究院首席科学家,曾任卡内基梅隆大学兼职教授。主要从事机器学习研究,担任IEEE TPAMI的副主编、AI编委,担任ICML、NeurIPS等领域主席20余次。获科学探索奖、CCF自然科学一等奖等,入选万人计划领军人才、MIT TR35中国先锋者以及IEEE“AI’s 10 to Watch”,获多项国际竞赛冠军和最佳论文奖。
![]()
报告简介:
单图像的信息分解及多图像的信息融合在诸多视觉任务中起到关键作用。本次报告将首先针对“由一生多“的病态问题,从层级图像剥离(Hierarchical Image Peeling)、层级元素解耦(Hierarchical Decoupling)、双流信息交互(Dual-stream Interaction )等多角度介绍如何对图像的信息进行有效分解,并通过反射去除、低照度增强、本征分解、边缘检测、显著性检测、人脸重渲染等任务上验证其有效性。另外,本报告将介绍无监督条件下对于多状态多模态的图像融合策略,在提升图像美观度的同时可为下游任务提供更丰富可靠的视觉输入。
个人简介:郭晓杰,天津大学智能与计算学部特聘研究员、长聘副教授,博士生导师、北洋骨干教师,吴文俊人工智能科技奖优秀青年奖获奖者、IEEE/CCF Senior Member。他担任CVPR 2022 AC,IJCAI 2021 SPC及20余个一区/CCF A类期刊和会议评审。研究方向包括计算机视觉和模式识别,取得一系列成果,不仅为高性能图像质量增强与模式分析提供了科学依据和有效方案,而且也有效提升了智能体多源信号融合、恶劣条件环境感知等智能视觉系统的精度与实时性。主持参与国家自然科学基金/科技部研发计划/CCF-腾讯犀牛鸟基金等10余项。迄今在国际权威期刊和会议上发表论文80余篇,曾获得国际模式识别协会Piero Zamperoni Best Student Paper奖1项,多媒体旗舰会议ICME Best Student Paper Runner-up奖2项,中国模式识别计算机视觉大会PRCV Best Student Paper Runner-up奖1项,被OpenCV平台技术集成1项。更多信息请访问:https://sites.google.com/view/xjguo
![]()
报告简介:
随着人工智能技术和其它信息技术的快速发展与不断进步,视觉图像数据的收集来源越来越广泛,规模也越来越大,但是正确标注的成本始终居高不下。这些客观因素导致正确标注的训练样本过少,数据的分布差异较大,经典的学习理论不再严格有效,视觉图像的泛化性建模与跨域自适应特征表达成为十分重要的研究方向。本次报告将向同行汇报相关研究内容的一些新进展。
个人简介:任传贤,中山大学数学学院副教授,科学计算与计算机应用系主任,兼任广东省工业与应用数学学会秘书长、中国计算机学会计算机视觉专委会副秘书长。长期关注高维、异构图像数据的特征表达与判别分析,在多尺度判别分析、稀疏表示与正则化方法、深度自适应特征表达(迁移学习)等方面开展了较为系统的研究。主持和参加多项国家自然科学基金项目,在国际重要学术期刊IEEE TPAMI, TIP, TNNLS, TCYB以及重要学术会议CVPR、AAAI等发表论文四十余篇,获得教育部自然科学研究优秀成果二等奖。
![]()
报告简介:
近年来大多数图像复原和增强网络的参数量与计算量都趋于增加,但是随着4K超高清视频的普及,这些方法不利于在超高清图像视频上的真实应用。针对这一问题,本次报告主要介绍了几种可用于实时处理4K超高清视频的轻量级图像复原网络结构。分别从图像分片并行、网络架构搜索,联合CNN与MLP的混合网络模型,以及基于双边网格学习的模型出发介绍了几种4K超高清图像视频实时复原网络结构,以及这些模型在图像视频去模糊、去雾、HDR重建等任务中的应用。
个人简介:任文琦,中国科学院信息工程研究所信息工程国家重点实验室副研究员。天津大学与加州大学Merced分校联合培养博士。主要研究方向包括图像视频处理与增强等相关问题。在本领域内国际主要期刊和会议IEEE TPAMI/TIP/TIFS、IJCV,CVPR/ICCV/NeurIP/ECCV等发表学术论文40余篇。担任《中国图象图形学报》青年编委,北京图象图形学学会理事等。曾获中国计算机学会优秀博士论文奖、CCF-腾讯犀牛鸟基金卓越奖、及中办科学技术进步一等奖(排名第四)等。并入选了微软亚洲研究院“铸星计划”、北京市科协“青年人才托举工程”、北京市“科技新星”等。
![]()
报告简介:
图像超分辨率技术近年来发展迅速,各种超分网络层出不穷,性能指标也在逐年攀升。然而我们对超分网络的运行机制却知之甚少,网络设计的科学性得不到保障。不仅如此,整个底层视觉领域都缺乏网络可解释性的工作。为此,我们尝试从三个角度来对超分网络进行解析。首先,我们研究了超分网络的归因机制,提出了专门针对底层视觉的归因工具Local Attribution Map (LAM),用它来分析超分网络对输入信息的有效利用情况。然后,我们尝试回答了一个关乎底层视觉网络本质的问题——超分网络里是否学到了语义信息,还是只是进行了复杂的局部映射?我们在网络特征中成功提取出了含有底层语义的Deep Degradation Representations (DDR),并与我们普遍认知的高层语义进行区分。在研究了网络的输入和特征之后,我们又从滤波器的角度出发,探索了盲超分网络中的功能分区。我们利用新提出的Filter Attribution method based on Integral Gradient (FAIG),找到了网络中负责去噪和去模糊的部分,并利用它们对不同损失类型的输入图进行分类。希望我们的工作可以帮助研究者更有效的理解和设计超分网络,并能够启发更多关于底层视觉的可解释性工作。
个人简介:
董超,副研究员,博士生导师,博士毕业于香港中文大学信息工程专业。2014年在欧洲计算机视觉大会(ECCV)上发表论文SRCNN,首次将深度学习引入图像超分辨领域。2017年-2019年,带队参加国际超分辨率比赛NIRTE17, NIRTE18,PIRM18,NTIRE19和AIM2020,共获得8项冠军。2016年-2018年就职于商汤科技集团,任高级研究经理,带领商汤超分团队开发了世界首款基于深度学习的数码变焦软件。2018年6月全职加入中科院深圳先进技术研究院,成立XPixel画质团队,专注于底层机器视觉和图像处理。现担任VALSE领域主席、IEEE JSTSP期刊编委,中国科学院青促会会员。团队主页:http://xpixel.group/
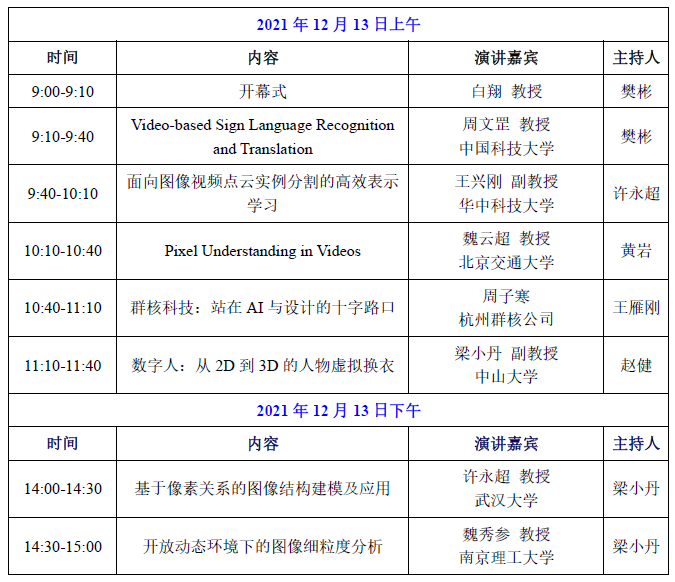
2021年12月13日上午
![]()
报告题目:Video-based Sign Language Recognition and Translation
报告简介:
Vision and language are two of the most important characteristics of human intelligence, and the corresponding research branches in artificial intelligence are computer vision and natural language processing. Since computer vision aims to understand image or video, it is natural to integrate vision and language for high-level vision tasks. As a typical test bed for research on vision and language, video-based sign language recognition (SLR) has attracted substantial attention in recent years. Existing approaches to SLR follow a data-driven paradigm, which ignore the essential characteristics of sign language, such as hand shape prior, language grammar, etc. To this end, in this talk, we introduce our solutions from the perspective of integrating data-driven and knowledge-guided ideas to bridge the gap of vision and language. We will first introduce the background of sign language and recognition techniques. Then, discuss our efforts on SLR from different perspectives, including data augmentation, multi-cue fusion, grammar learning, hand prior modeling, and self-supervised learning. After that, we share the prospect of the future research on SLR towards its real-world applications.
个人简介:Dr. Wengang Zhou is currently a Full Professor with the Department of Electronic Engineering and Information Science (EEIS), University of Science and Technology of China (USTC). Before joining USTC, he worked as a post-doctorate researcher in the Computer Science Department, University of Texas at San Antonio (2011-2013). He got his PhD degree from EEIS Department, USTC in 2011. His current research interests include multimedia information retrieval, computer vision, and computer game. In those fields, he has published over 90 papers in IEEE Transactions and CCF Tier-A International Conferences. He was the recipient of ICIMCS 2012 best paper reward and the Excellent PhD Thesis Award of Chinese Academy of Sciences in 2013. He served as the Publication Chair of ICME 2021.
![]()
报告简介:
在这个报告中,我将介绍我们在ICCV 2021上发表的三个关于视觉数据实例分割的工作。第一个工作提出了一种基于Query机制的图像实例分割方法,通过同一个Query在多阶段同时预测物体的包围盒和掩码,该方法超越了之前的SoTA方法,例如Mask R-CNN, Cascade R-CNN, HTC等。第二个工作提出了面向视频实例分割的交叉学习方法,该方法通过利用每一帧中物体的动态参数来预测物体在其他帧中的掩码,在损失函数层面获得了稳定的物体表示,在精度和速度的权衡方面取得了当前的最优结果。第三个工作提出了一个面向点云实例分割的层次聚类方法。在ScanNet测试集上取得了第一名的成绩,且在所有SoTA方法中速度最快。相关算法均开源于:https://github.com/hustvl。
个人简介:
王兴刚,华中科技大学,电子信息与通信学院,副教授,主要研究方向为计算机视觉和深度学习。在业内顶级的期刊和会议上发表论文50余篇,谷歌学术引用次数超过7600次。担任国际顶级会议CVPR领域主席,Pattern Recognition (IF 7.196)、Image and Vision Computing (IF 3.103)、 Electronics (IF 2.412)期刊编委/副编辑,AAAI、IJCAI SPC,IEEE TPAMI、CVPR等期刊会议审稿人。入选中国科协“青年托举人才工程”,获“微软学者”奖(全亚洲10名获奖者)、湖北省自然科学二等奖、华为优秀技术合作项目奖、CCF-腾讯犀牛鸟基金优秀奖等奖励。
![]()
报告题目:Pixel Understanding in Videos
报告简介:
In this talk, Dr. Wei will introduce his recent research on video object segmentation (VOS) and video scene parsing (VSP). VOS aims to segment an (or several) object instance (s) in the entire video sequence given the annotated object mask (s) on the first frame, and VSP aims to predict the semantics of each pixel for all video frames. For VOS, a Collaborative VOS by Foreground-Background Integration (CFBI) approach and an Associating Object with Transformers (AOT) approach will be introduced, which achieves the state-of-the-art performance on popular benchmarks and help win the Youtube VOC Challenge in 2021. For VSP, a new large-sale dataset named Video Scene Parsing in the Wild (VSPW) will be introduced. These works are published in TPAMI 2021 and CVPR 2021.
个人简介:魏云超,北京交通大学教授、博导。曾在新加坡国立大学,美国伊利诺伊大学厄巴纳-香槟分校,悉尼科技大学从事研究工作。曾获澳大利亚学术新星(2020),中国图象图形学学会科技技术奖一等奖(2020),澳大利亚研究委员会青年研究奖(2019),计算机视觉领域世界杯ImageNet竞赛冠军(2014),Youtube VOS国际视频分割竞赛冠军(2021)中国电子学会/北京交通大学优博(2016)等,在国际顶级会议和期刊上发表论文80多篇,包括12篇IEEE TPAMI和43篇CCF A类会议论文,Google引用近7000次。主要从事计算机视觉方面的相关研究,包括面向不完美数据的视觉认知,图像/视频的分割和物体检测,多模态数据建模等。
![]()
报告简介:
近年来,AI与设计的碰撞引发了跨行业的广泛讨论,也产生了许多不错的应用案例。随着AI技术的发展,我们甚至看到了一些可以“以假乱真”的设计结果。然而,对于AI与设计结合的一些基本问题,我们似乎仍然没有满意的答案:现在的AI应该如何赋能设计?在不久的将来,我们可以期待AI带来哪些影响,会遇到哪些主要挑战?设计平台产生的大数据,又能为AI带来哪些新的机遇?围绕这些问题,我将介绍群核科技作为全球领先的云设计软件平台和SaaS服务提供商,在AI与设计结合的方向上,从科研到应用落地的一些实践经验和心得。
个人简介:周子寒,清华大学自动化学士,美国伊利诺伊大学电子与计算机工程博士。2013年1月至2021年4月就职于美国宾夕法尼亚州立大学信息科学与技术学院,历任研究员,助理教授(博士生导师)。研究三维计算机视觉,在相关领域已发表论文30余篇,获得美国发明专利3项,总引用超过3000次。2021年5月起就职于杭州群核信息技术有限公司,任首席科学家,致力于下一代3D云设计技术的自主研发,并推动AI与计算机辅助设计新兴交叉领域的科研探索。
![]()
报告简介:
近年来,各种图像生成、人物生成和姿态迁移等技术取得了显著进展,并支持了虚拟人(Virtual Human)领域的蓬勃发展和技术落地应用。本次讲座首先将介绍我们研究组在2D图像虚拟换衣领域的长期研究和进展,可以处理复杂多样的衣服生成和试穿。之后将介绍我们最新的研究成果,如何仅依据2D图像和衣服直接生成3D虚拟人物和换装效果,大大提升系统的可展示性和灵活度。同时介绍本研究组相关成果在工业界落地使用效果。
个人简介:
梁小丹博士任职于中山大学副教授。之前于美国卡内基梅隆大学CMU任博士后研究院。主要研究方向为可解释和认知智能及其在大规模视觉识别,人物生成和多模态人机交互领域的应用。Google Scholar引用超过1万余次,兼任ICCV 2019, CVPR 2020, NeurIPS 2021, WACV 2021的领域主席和CVPR 2021的Tutorial Chair. 荣获ACM中国和CCF优秀博士论文奖,阿里巴巴达摩院青橙奖、中国图象图形学学会科学技术一等奖,中国图象图形学学会石青云女科学家奖和ACL 2019最佳展示论文提名奖,福布斯中国30 Under 30科学榜等。
2021年12月13日下午
![]()
报告简介:
图像表示是图像处理与理解的基础核心问题之一,传统的图像表示中,图像常被看成一个无向图,每个像素点通常是独立考虑的,为了更好的分析和理解图像,许多图像处理则是基于由像素点组成的基元(primitive),比如傅立叶变换、小波变换等。在本报告中,报告人将首先从数学形态学出发,利用相邻像素点的关系,构建基于区域的图像表示来对图像进行结构建模。该空间具有鲁棒图像分析所需的多尺度、连续拓扑变换协变、对比度变换不变等特性。随后介绍基于形状空间在兴趣区域检测、滤波、层次分割等方面的应用。最后,报告人也将介绍近期利用深度学习来学习相邻像素点的关系进行图像结构建模,并用在检测与分割方面工作。
个人简介:许永超,武汉大学,计算机学院,教授,博导,2008年本科毕业于华中科技大学,2010年硕士毕业于法国巴黎11大,2013年获得东巴黎大学博士学位,回国前任职于巴黎高等信息工程师学院Tenured Assistant Professor,研究领域涉医学图像分析、多方向目标检测识别、计算机视觉。在包括IEEE TPAMI、IEEE TIP、CVPR、ICCV等重要国际期刊和会议发表学术论文 40多 篇,目前担任Frontiers of Computer Science期刊的青年编委,IEEE TPAMI、IJCV、CVPR等多个期刊会议的审稿人。入选中国科协“青年托举人才工程”,获CVPR,ECCV竞赛冠军各一次,中兴高价值合作项目奖等奖励。
![]()
报告简介:
图像细粒度分析是视觉感知学习的重要研究课题,在智能新经济和工业互联网等方面具有巨大应用价值。随着细粒度图像分析的应用场景向多维领域快速发展,其处于静态封闭环境的经典假定不再成立,不可避免地将面临开放动态环境挑战。本报告将针对监督信息不充足、样本分布不平衡、类别空间不闭合等现实频发问题,介绍在开放动态环境下图像细粒度分析方面本课题组的相关研究成果,并简要展望图像细粒度分析的未来发展方向。
个人简介:魏秀参,博士,南京理工大学计算机科学与工程学院教授,南京大学学生创业导师。主要研究领域为计算机视觉和机器学习,在相关领域国际顶级期刊和会议发表论文四十余篇,Google Scholar Citations 逾2400次,相关研究成果获得含iNaturalist在内的计算机视觉领域国际权威赛事共4项世界冠军。曾在CVPR、ICME等国际会议讲授“图像细粒度分析”为主题的短课程。著有《解析深度学习–卷积神经网络原理与视觉实践》一书。曾获江苏省计算机学会青年科技奖、江苏省科协青年人才托举工程、南京经开区中青年优秀人才、南京理工大学青年拔尖人才等荣誉。任中国计算机学会高级会员、CCF计算机视觉专委会委员、中国图象图形学报青年编委。担任ICCV、IJCAI、ACM Multimedia等国际会议Workshop程序委员会主席,ACCV 2022 Tutorial主席,IJCAI 2021高级程序委员等。
极市平台专注分享计算机视觉前沿资讯和技术干货,特邀请行业内专业牛人嘉宾为大家分享视觉领域内的干货及经验,目前已成功举办88
期线上分享
。近期在线分享可
点击以下标题
查看:
(http://bbs.cvmart.net/topics/149/cvshare),也可以点击阅读原文获取。
在"极市平台"公众号后台回复期数或者分享嘉宾名字,即可获取极市平台对应期在线分享资料。
极市(Extreme Mart)
是深圳极视角科技有限公司旗下AI开发者生态,面向计算机视觉算法工程师,为开发者提供算法开发环境、真实数据项目实战、自动测试、加速工具、算法封装等全方位平台技术与工程支持,同时提供技术干货、大咖分享、社区交流、竞赛活动等丰富的内容与服务。
有任何想了解的内容请在本帖下留言,嘉宾会在直播中回答大家的问题哦~
觉得有用麻烦给个在看啦~ ![]()