尼克谈人工智能的历史、现实与未来
点击上方“专知”关注获取专业AI知识!

本文授权转载自公众号:上海书评 shanghaishuping

尼克(蒋立冬绘)
尼克,乌镇智库理事长,数知科技创始人,国家“千人计划”专家。早年负笈美国,师从“强化学习”算法发明者;曾在哈佛和惠普工作。
近日,尼克的《人工智能简史》由人民邮电出版社出版,他在书中全面勾勒人工智能半个多世纪的历史,再现了AI史上大师的工作、交往。就人工智能的历史、现实与未来诸问题,《上海书评》对他作了专访。

尼克:《人工智能简史》,人民邮电出版社,2017年12月,320页。
采访︱丁雄飞 李文逸
《经济学人》(The Economist)今年7月15日发表的题为“中国或在人工智能领域赶上或击败美国”(China May Match or Beat America in AI)的文章里,引用了乌镇智库所作的人工智能报告的数据。乌镇智库和人工智能之间是什么关系?从数据看人工智能,您可以告诉我们什么?
尼克:乌镇智库搜集了人类有史以来几乎所有的公开数据,例如所有的专利、所有的学术资源、所有的经济金融数据、法院判例,还有过去十几年里所有语言的维基百科和各种在线百科数据,以及社交媒体数据。我们把这些数据都建成知识图谱,也整合了IBM著名的Watson系统底层的开源知识图谱。在我们做的各种行业报告中,最有影响力的确实是关于人工智能的系列报告。目前,《经济学人》、《金融时报》、高盛等机构关于人工智能的深度报道大量引用我们的数据。可以说,中文媒体上涉及人工智能的报道,其数据部分的源头大多在我们这儿。
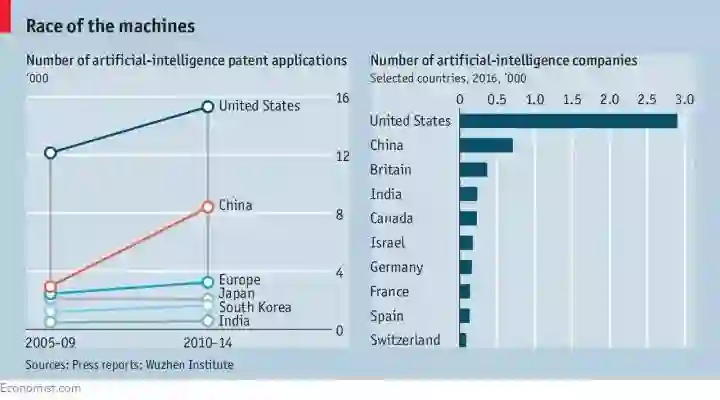
《经济学人》刊载的2005、2010年相关国家AI专利申请数量,以及2016年相关国家AI公司数量。
具体来说,从专利看人工智能,我们可以知道: 1980年代,中国尚没有专利制度,更谈不上人工智能专利,但到了2012至2013年间,中国人工智能的专利总数已经超过美国,但专利的质量还不高。专利质量是可以定量计算出来的,学术论文的结果也类似。
根据我们做的人工智能的大学排名,前四十名里没有中国,但从四十几名开始,就有清华了。在人工智能的分支学科中,八十年代极盛的专家系统,今天已无人问津,这在工业界的反映就是日本第五代计算机项目的衰败。2010年后兴起、今天还十分热门的人工智能子学科包括:机器学习、计算机视觉、自然语言处理。机器翻译就属于自然语言处理。

《金融时报》刊载的AI相关研究论文引用排名
我们还可以利用数据做区域的对比研究。中国在人工智能的投融资已经是世界第二,但也差不多只是以色列的四倍。以色列是个人口八百万的国家,比上海的一个区还要小。而我们做的物联网报告显示,中国的物联网体量比以色列要大四十多倍。这说明涉及高精尖技术的,以色列很强,而涉及人口和制造的,中国强。
您为什么要写人工智能的历史?去年来,AlphaGo不断战胜人类围棋冠军,而AlphaGo Zero还能自己从低阶到高阶对弈,能谈谈您和这个团队的渊源吗?

人机围棋对决,柯洁不敌AlphaGo。
尼克:现在人工智能这么热,需要有本书把它的历史说明白。另外,国内没什么像样的人工智能的科普。我看过很多伪媒体人和“砖家”的各种言论,胡说八道的程度令人发指,可怕的是其中一些人还有巨大的话语权和影响力,控制着各种资源。
我自认还够格写这样一本书。人工智能发展过程中的不少事儿,我大致都清楚。一方面出于兴趣,另一方面,我的老师和大师兄是这个领域的大师级人物,他们发明了“强化学习”算法。谷歌收购的DeepMind团队里一半的人都是我大师兄的学生,他们曾经是人工智能中的少数派,但DeepMind搞的AlphaGo赢了李世石之后,这一派一下又成了显学。当年把我老师招到麻省大学的是迈克尔·阿比布(Michael Arbib)。他是控制论创始人维纳的最后一个博士生。按照阿比布的一家之言,人工智能是控制论的替代品。我当年本想投奔的是阿比布,但我到学校,他已转会去了南加州大学,结果我就跟了我老师研究强化学习。从这个意义上说,我是AlphaGo那帮人的长辈。

迈克尔·阿比布

DeepMind团队
我上学的时候正值人工智能低潮。一般美国大学的计算机系都是分三伙人:做系统的,做理论的,做人工智能的。做系统的和做理论的互相看不起,但他们同时看不起做人工智能的。现在情况不一样了,做人工智能的应该都咸鱼翻身了,个个成了公共知识分子。我那时才疏学浅,看不清强化学习的远景,证明了一个与机器学习相关的理论结果就离开了。其实,在人工智能的各个分支里,大概只有强化学习还留了点控制论的影子,也有人认为,强化学习包含了全部人工智能。
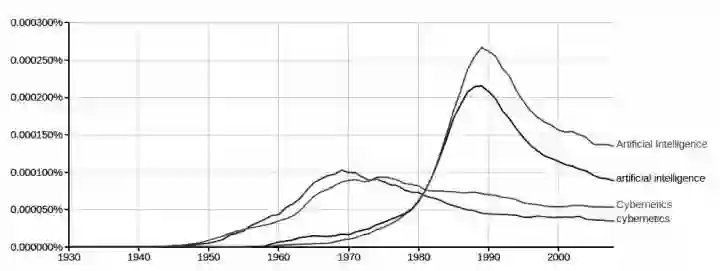
“人工智能”与“控制论”词频对比(引自《人工智能简史》)
人工智能学界,国内有一个和美国不同的现象:中国在人工智能领域最有发言权的是自动化系——对应到中科院就是自动化所(新成立的人工智能学院就设在这里),而自动化系主要关注计算机是怎么用的,并不关注计算机的基础理论。美国的大学并没有分得这么细,加州大学伯克利分校和麻省理工学院到现在还是一个大系:EECS(Department of Electrical Engineering and Computer Science)——这在中国至少能拆成五个学院。中国一个很小的学科分支都是一个学院,而学院之间老死不相往来。
人工智能这样的学科,如果不懂点图灵的计算理论,讨论就很难深入。我除了想正本清源,还想鼓励专家间的互动。
我也希望决策者看看我的书,了解些科普和历史,也许可以少被伪媒体人和“砖家”们忽悠,少浪费些社会资源。我再说多了就要挨骂了。
西方有对人工智能历史的经典书写吗?
尼克:美国人写的人工智能历史,比较著名的有尼尔森(Nils J. Nilsson)的《人工智能探究》(The Quest for Artificial Intelligence: A History of Ideas and Achievements)。尼尔森是人工智能学科的早期参与者和领导者,担任过斯坦福研究所(SRI)人工智能部门的负责人和斯坦福大学计算机系主任多年。不过他这本书主要写的是他自己熟悉的、偏好的领域。麦克达克(Pamela McCorduck)1979年写的《能思考的机器》(Machines Who Think: A Personal Inquiry into the History and Prospects of Artificial Intelligence)从今天的角度看则有些过时。

尼尔森:《人工智能探究》

麦克达克:《能思考的机器》
另外,明尼苏达大学的查尔斯·巴贝奇(Charles Babbage)研究所一直在做计算机科学的口述历史,采访了很多人工智能学者。大部分的采访都有录音。我听了近一百小时录音,从这些第一手资料里有一些有趣的新发现。
无论中英文,当下都没有一本合适的人工智能历史的读物。总的来讲,我这本书还算公正全面,我儿子正在把它译成英文。
通过第一手资料,您有什么关于AI史的新发现?
尼克:比如“人工智能”(artificial intelligence)这个词最早是谁提出的。普遍的误解是,“人工智能”这个词是1956年达特茅斯学院夏季研讨会——人工智能的起源事件——的召集者麦卡锡(John McCarthy)想出来的,其实不然。麦老晚年回忆,承认这个词最早是从别人那里听来的,但记不清是谁了。后来英国数学家伍德华(Philip Woodward)给《新科学家》杂志写信说他是AI一词的原创者,麦卡锡最早是听他说的,因为他1956 年曾去麻省理工学院访问,与麦卡锡交流过。但麦卡锡在1955 年就在其建议书里使用“人工智能”一词了。如今当事人大都已仙逝,这事恐成悬案。其实英国人最早的说法是“机器智能”(machine intelligence),这大概和图灵1950年在哲学杂志《心》(Mind)上发表的传世文章《计算机与智能》(Computing Machinery and Intelligence——我的译文作为附录收在书中)有关。最早Computing Machinery指计算机,而Computer是指人肉计算员,他/她们用机械计算机从事简单重复的计算工作。

图灵的《计算机与智能》发表于1950年10月的《心》
另外,我比较详细地考证了美国人工智能几大学派之间的矛盾和论争。美国最早有三大人工智能基地:斯坦福大学、麻省理工学院和卡内基梅隆大学。三大基地是三伙不同的人弄的,这些实验室经历了种种的斗争、分裂、重组。这些人事纷争构成了人工智能学科的历史。事实上,当图灵在1948 年英国国家物理实验室的内部报告中区分了“肉体智能”/“附体智能”(embodied intelligence)和“无肉体智能”(disembodied intelligence),后来的统计派/神经网络派(造一台智能机器模拟大脑中的神经网络)与符号派/逻辑派(用逻辑和符号系统模拟心智)之争就已经埋下了伏笔。人工智能的鼻祖之一纽厄尔(Allen Newell)说过,一部AI史就是一部斗争史(大意如此)。换言之,在任何时候,每种方法都有个对立面:模拟与数字,知识与逻辑,语义与语法,连续与符号,串行与并行,取代与增强,机械论与目的论,生物学与活力论,工程与科学……

麦卡锡在斯坦福大学的人工智能实验室

司马贺
最早的麦卡锡、司马贺(Herbert Simon)分别是做逻辑和定理证明的,做统计的人当时不被重视,但现在反而逻辑没人搞了,都去做统计了。近年来,知识图谱技术在谷歌的鼓吹下,算是为符号派留下了一支血脉。
自人工智能起源至今,半个多世纪过去了,它在哪些方面业已取得了突破?
尼克:参加了达特茅斯会议的纽厄尔和司马贺在1957 年曾预测:十年内计算机下棋能赢人,十年内计算机将能证明人还没有证明的定理。他们太乐观了。这两个预测分别在1997年和1996年才实现,花了大概四十年。

1985年4月14日,纽厄尔在旧金山参加美国计算机协会的人机交互大会。

2006 年,达特茅斯会议五十周年时,当时的十位与会者中有五位仙逝,活着的五位——摩尔、麦卡锡、明斯基、塞弗里奇、所罗门诺夫在达特茅斯重聚。
从人工智能的历史看,确实有很多过去认为是很难解决的问题被慢慢解决,比如人脸识别近五年在国内迅猛发展。目前,借助“深度学习”(多层神经网络)的语音识别系统已经达到可实用的阶段。过去几年也有一堆同质的公司冒出来。
机器翻译难道还没有突破吗?
尼克:的确,随着语音和图像识别技术渐趋成熟,人们普遍认为目前人工智能里比较难的问题是自然语言处理。有专家最近有言:懂语言者得天下。机器翻译就是自然语言处理的一部分。2016 年,谷歌利用深度神经网络搞的神经机器翻译(Google Neural Machine Translation)系统,大幅提高了机器翻译的水平;今年,Facebook利用自己擅长的卷积神经网络,也进一步提高了机器翻译的效率。但这距离理想场景——例如人们可以不学外语,人耳中嵌入微型翻译器,自动译出听到的外语——还很远。

谷歌神经机器翻译系统翻译的例句
自然语言处理涉及了不少哲学主题,从图灵测试到塞尔的“中文屋”假想实验,皆与此相关。每出现一个新的人工智能工具,都会被用来试试自然语言处理。
除了翻译之外,自然语言处理的另一个难题是人机对话。现在的对话都是在短场景——十个句子之内,因为问答系统依靠的是常识和浅层的推理;知识图谱是核心。一个问题总是会涉及who,when,where,how,why,这些要素都可以套到知识图谱中类和实体的属性和关系上。当你问2016 年之后的搜索引擎:“梁启超的儿媳妇是谁?”答案中至少会有“林徽因”和“林洙”。因为系统底层的知识图谱知道梁思成是梁启超的儿子,而梁思成结了两次婚,第一次林徽因,第二次林洙。当知识图谱足够大的时候,它回答问题的能力会惊人:2011 年IBM的沃森(Watson)就在美国电视智力竞赛节目Jeopardy!中击败人类选手。但是,目前要达到很长的人机对话场景还很难。

沃森在Jeopardy!中击败人类选手
这些技术是人工智能下一步的突破口,我们也努力在这些领域做些有意义的创新性工作。
如《银翼杀手》这样的赛博格电影总会关注未来人工智能的主体意识和人机关系这样的议题。您是怎么看“奇点”(singularity)的?
尼克:所谓“奇点”——机器超过人,或者用《未来简史》(Homo Deus: A Brief History of Tomorrow)作者的话说,有一个全新的物种在智能上超越人类——本身的定义是不严格的。如果就某个单项指标论,机器早就超过人类了。讨论这个问题,首先要定义智能是什么、人是什么。当下,总有一些人会干而机器不会干的事,以及机器会干而人不会干的事,但不也总有这个人会干,而那个人不会干的事吗?能说其中一个就不是人吗?
我们甚至可以追问:当你断了一条胳膊、换了一颗别人的心脏,你还是你吗?如果把你的头换到别人的身体上,你还是你吗?这个时候,DNA可能都是别人的了,但意识还是你的。科幻电影总是把人工智能问题化约为是不是能造出人形机器人,这是低级而庸俗的。界定人或智能是什么、追问机器是否有智能,需要诉诸计算理论。

2017年6月7日,高考机器人AI-MATHS在断网断题库的情况下完成了北京文科数学卷和全国二卷数学卷,分别用时二十二分钟与十分钟,成绩分别为一百零五分与一百分(满分一百五十分)。
一直有所谓强人工智能和弱人工智能之说:强人工智能就是能造出全面超越人类的机器,而弱人工智能是指能造出在某些方面——例如下棋、人脸识别——超越人类的机器。根据丘奇-图灵论题(Church-Turing Thesis),所有功能足够强的计算装置的计算能力都等价于图灵机,不可能存在比图灵机更强的计算装置。除了丘奇-图灵论题,还有个相似性原则:任何计算装置之间互相模拟的成本是相似的。这两个论题隐含着强人工智能的可能性:智能等价于图灵机、人就是图灵机。目前的计算机科学(包括人工智能)的工作都是建立在这个认同之上的。当服从摩尔定律(每十八个月信息处理能力加倍)的计算装置进化的速度快过人类进化的速度,那么就有“奇点”来临的那一天。那时,自然语言理解、机器定理证明都不是事儿。

可运行的纸带版图灵机
也不是所有的科学家都相信丘奇-图灵论题和相似性原则。代表人物就是英国数学家、《皇帝新脑》(Emperor’s New Mind: Concerning Computers, Minds, and the Laws of Physics)的作者彭罗斯(Roger Penrose)。当下很热门的量子计算机就有可能不服从相似性原则。量子计算机或许能有效地解决素数分解问题,这是当今公钥加密算法的基础,如果量子计算机成功,那当前的电子商务体系就会出现不安全隐患。当然,大规模、可实用的量子计算机的实现,仍然存在困难,目前在这方面最领先的是IBM。

彭罗斯:《皇帝新脑》
根据您的理解,人工智能为什么会在这几年进展迅速?
尼克:主要原因有两个,一个是大规模的数据累计,另一个是计算能力的提升,同时达到了拐点。
我想提出一个更普遍的观点:今天,测度人类文明的标准是全社会的算力。斯坦福大学历史学教授莫里斯(Ian Morris)在《西方将主宰多久》(Why the West Rules—For Now)一书中,用能耗作为主要测量参数,比较了东西方文明。但随着新能源技术的出现,例如前几年的页岩气的开发,能源问题已经在一定程度上得到缓解。在我看来,就过去一百多年而言,测度文明的指标是信息处理能力。具体到这几十年,信息处理能力可以用计算能力来衡量——全社会的算力是全社会计算设备的数目与单台设备计算能力的乘积。
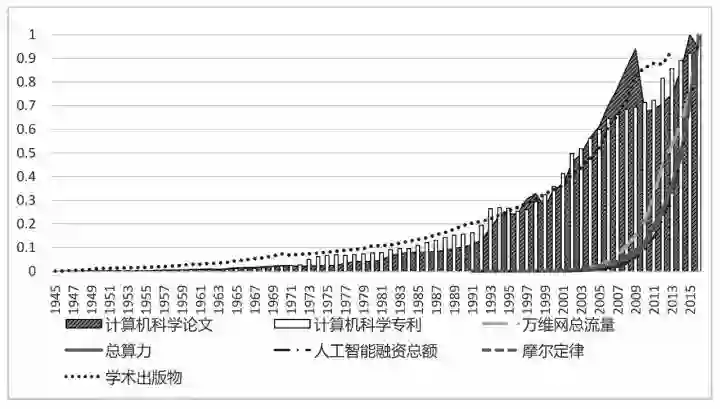
计算机科学论文、计算机科学专利、万维网流量、社会算力、人工智能全球融资总额、摩尔定律及学术出版物的增长趋势对比(引自《人工智能简史》)
今年6月,马云在天津举行的首届世界智能大会上作了《智能改变世界》的主题报告;早先,腾讯也实践了聊天机器人。人工智能在中国的前景如何?眼下存在泡沫吗?
尼克:不论是去年中国科学家、企业家群体发起的未来科学大奖(号称中国的诺贝尔奖,单项奖金一百万美金),还是今年阿里巴巴成立的探索科技未来的实验室“达摩院”(宣称将在三年内投资千亿),都让人感觉中国试图在科技领域确立世界的领导权。且不论具体的实施,我认同民间资助科技的这个思路和运作方式。

阿里巴巴“达摩院”
但上世纪八十年代日本五代机的教训足以让我们引以为戒。当时日本在制造业和集成电路上大举超越美国,五代机便是日本雄心勃勃试图建立在全球信息产业的领导地位、从制造大国转型为经济强国的计划的一部分。与此同时,美国的费根鲍姆(Edward Albert Feigenbaum)等人也使劲吹捧五代机,目的则是为了给本国政府施压,要求增加在科技领域,尤其是在自己领域——专家系统的投资。当然,最后五代机是个彻底的失败。五代机的失败让日本整个信息产业一直落后于美国,使得日本最聪明的一批人的黄金十年被耽误了,也严重打击了当时所谓“日本第一”的民族自信。

1981年第一次五代机会议的会议录(共二百八十八页)
几年前,我花时间研究了日本五代机所有会议的论文集。从1988 年的会议录——一千三百页的三大卷——可以看出,当时五代机已经成了大杂烩,失去了聚焦点,八杆子打不着的领域也拼命向它靠拢。这就像当下人工智能领域的创业,一些和人工智能毫无瓜葛的人一夜间都成了人工智能专家。很多创业者也是拿到风投的钱之后再考虑做什么。可以说,现在人工智能里面肯定有泡沫。但是不是有很大的泡沫,我不敢说。比较大的问题是同质化,做语音处理的公司有一堆,做人脸识别的也有一堆,都融了巨额的风险投资,它们的估值已经超过了许多上市公司。如果资本没有预期的回报,就是泡沫。共享单车就是一堆同质公司竞争的例子,目前的合并可以被看作是挤泡沫。

人脸识别产品
风险投资扎堆投资是不健康的,是泡沫的根源之一。他们理应是前瞻性的,而不是人云亦云。了解些人工智能的历史,也许会让大家对一些潜在的投资领域有更深刻的了解。无论美国还是中国,表现最好的风险投资机构都是对行业有独到看法的。
中国和美国在人工智能领域可否一比?

中美在人工智能领域的竞争
尼克:美国经历过几次科技泡沫,人才和资本都会更成熟些,应对措施也更多样化。日本在五代机之前没有经历过科技泡沫,危机一来,束手无策,最后只好互相掩盖,不了了之。除了投融资领域的泡沫,中国的科技政策的制定和实施也可吸取教训。
从整体上说,中国的人工智能是和美国一道处在第一梯队里。我们深入研究过中国的三个经济区——京津冀、长三角和粤港澳大湾区,中国的人工智能企业、人才、资本有大约七成集中在北京,这一点类似于美国的硅谷。我们的研究也表明,现在,中国确实在人工智能的某些方面已经赶超美国,至少体现在公司、专利和论文的数量上,但质量上,还有距离。总的来讲,硅谷还是全球的灯塔。
-END-
专 · 知
人工智能领域主题知识资料查看获取:【专知荟萃】人工智能领域24个主题知识资料全集(入门/进阶/论文/综述/视频/专家等)
同时欢迎各位用户进行专知投稿,详情请点击:
【诚邀】专知诚挚邀请各位专业者加入AI创作者计划!了解使用专知!
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请扫一扫如下二维码关注我们的公众号,获取人工智能的专业知识!

请扫一扫加专知小助手微信(Rancho_Fang),加入专知主题人工智能群交流!

点击“阅读原文”,使用专知!





