业界 | 阿里云推出机器学习平台PAI 2.0,降低人工智能门槛与开发成本
机器之心原创
作者:高静宜
2017 年 3 月 29 日,阿里云首席科学家周靖人博士在 2017 云栖大会•深圳峰会上重磅推出升级版的机器学习平台 PAI 2.0,可以大幅度降低人工智能门槛以及开发成本。

近年来,人工智能迎来新浪潮,逐渐扩展至城市治理、交通调度、工业制造、健康医疗、司法等应用场景。在大会上,周靖人博士表示:「在过去一年的时间里,我们协助客户落实了多项重大的人工智能应用,人工智能已经成为触手可及的普惠技术,变成真正帮助人类解决实际问题的得力助手,PAI 正是为此而来。」
2015 年,阿里云对外发布国内首个机器学习平台 PAI (Platform of Artificial Intelligence),不仅可以实现高性能云端计算从而降低存储和计算成本,还具备相应的工具和算法库进而降低技术门槛。此次版本的重大升级建立在阿里云机器学习平台 1.0 之上,标志着阿里云在构建 AI 核心技术能力上又进一步。
阿里云机器学习平台 PAI 2.0 的主要特性包括以下方面:
全面兼容深度学习框架
自 2012 年深度学习的代表模型 AlexNet 在 ImageNet 大赛中力压亚军,以超过 10 个百分点的绝对优势夺得头筹之后,依托于建模技术的进步、硬件计算能力的提升、优化技术的进步以及海量数据的累积,深度学习在语音、图像以及文本等多个领域不断推进,相较于传统作法取得了显著的效果提升。工业界和学术界也先后推出了用于深度学习建模用途的开源工具和框架,包括 Caffe、Theano、Torch、MXNet、TensorFlow、Chainer、CNTK 等等。TensorFlow、Caffe 和 MXNet 是目前全球主流的深度学习开源框架;TensorFlow 开源算法和模型最丰富;Caffe 是经典的图形领域框架,使用简单;MXNet 分布式性能优异。
深度学习通过设计复杂模型,依托于海量数据的表征能力,从而获取相较于经典浅层模型更优的模型表现,这样的建模策略促使对底层训练工具提出了更高的要求。现有的开源工具,往往会在性能上、显存支持上、生态系统的完善性上存在不同层面的不足,在使用效率上对于普通的算法建模用户并不够友好。
PAI 2.0 编程接口完全兼容深度学习框架:TensorFlow、Caffe 以及 MXNet,用户只需要将自己本地编写的代码文件上传至云端就可以执行。

对于底层计算资源,PAI 2.0 提供了强大的云端异构计算资源,包含 CPU、GPU、FPGA。在 GPU 方面,PAI 2.0 可以灵活实现多卡调度。

借助这些框架以及强大的计算资源,用户非常方便地就可以将计算任务下发到对应的分布式计算机群上,实现深度学习模型训练与预测。
算法库的丰富与创新
PAI 2.0 提供 100 余种算法组件,涵盖了分类、回归、聚类等常用场景,还针对主流的算法应用场景,提供了偏向业务的算法,包含文本分析、关系分析、推荐三种类别。
「算法全部脱胎于阿里巴巴集团内部的业务实践,所有算法都经历过 PB 级数据和复杂业务场景的锤炼,具备成熟稳定的特点」,阿里云首席科学家周靖人说。
支持更大规模的数据训练
PAI 2.0 新增了参数服务器(Parameter Server)架构的算法。不仅能进行数据并行,同时还可将模型分片,把大的模型分为多个子集,每个参数服务器只存一个子集,全部的参数服务器聚合在一起拼凑成一个完整的模型。
其创新点还在于失败重试的功能。在分布式系统上,成百上千个节点协同工作时,经常会出现一个或几个节点挂掉的情况,如果没有失败重试机制,任务就会有一定的几率失败,需要重新提交任务到集群调度。PS 算法支持千亿特征、万亿模型和万亿样本直至 PB 级的数据训练,适合于电商、广告等数据规模巨大的推荐场景。

人性化的操作界面
从操作界面来看,PAI 没有繁琐的公式和复杂的代码逻辑,用户看到的是各种分门别类被封装好的算法组件。每一个实验步骤都提供可视化的监控页面,在深度学习黑箱透明化方面,PAI 也同时集成了各种可视化工具。
周靖人博士在现场展示了在搭架实验的过程中,只需要设置数据源、输出,就可以让系统实现人工智能训练,拖拽组件即可快速拼接成一个工作流,大幅提升了建立的调试模型的效率。可视化方式则有助于使用户清楚地了解问题本身以及深度学习的效果。

事实上就目前而言,大规模深度学习优化还是一个方兴未艾的技术方向,作为一个交叉领域,涉及到分布式计算、操作系统、计算机体系结构、数值优化、机器学习建模、编译器技术等多个领域。按照优化的侧重点,可以将优化策略划分为计算优化、显存优化、通信优化、性能预估模型以及软硬件协同优化。PAI 平台目前主要集中在以下四个优化方向。
显存优化
内存优化主要关心的是 GPU 显存优化的议题,在深度学习训练场景,其计算任务的特点决定了通常会选择 GPU 来作为计算设备,而 GPU 作为典型的高通量异构计算设备,其硬件设计约束决定了其显存资源往往是比较稀缺的,目前在 PAI 平台上提供的中档 M40 显卡的显存只有 12GB,而复杂度较高的模型则很容易达到 M40 显存的临界值,比如 151 层的 ResNet。

36 层的 ResNet 模型示例
PAI 在显存优化上做了一系列工作,期望能够解放建模工作中的的负担,使用户在模型尺寸上获得更广阔的建模探索空间。在内存优化方面,通过引入 task-specific 的显存分配器以及自动化模型分片框架支持,在很大程度上缓解了建模任务在显存消耗方面的约束。其中自动化模型分片框架会根据具体的模型网络特点,预估出其显存消耗量,然后对模型进行自动化切片,实现模型并行的支持。在完成自动化模型分片的同时,框架还会考虑到模型分片带来的通信开销,通过启发式的方法在大模型的承载能力和计算效率之间获得较优的 trade-off。
通信优化
大规模深度学习,或者说大规模机器学习领域里一个永恒的话题就是如何通过多机分布式对训练任务进行加速。而机器学习训练任务的多遍迭代式通信的特点,使得经典的 map-reduce 式的并行数据处理方式并不适合这个场景。对于以单步小批量样本作为训练单位步的深度学习训练任务,这个问题就更突出了。
依据 Amdahl's law,一个计算任务性能改善的程度取决于可以被改进的部分在整个任务执行时间中所占比例的大小。而深度学习训练任务的多机分布式往往会引入额外的通信开销,使得系统内可被提速的比例缩小,相应地束缚了分布式所能带来的性能加速的收益。
PAI 平台通过 pipeline communication、late-multiply、hybrid-parallelism 以及 heuristic-based model average 等多种优化策略对分布式训练过程中的通信开销进行了不同程度的优化,并在公开及 in-house 模型上取得了比较显著的收敛加速比提升。
在 Pipeline communication 中,将待通信数据(模型及梯度)切分成一个个小的数据块从而在多个计算结点之间充分流动起来,可以突破单机网卡的通信带宽极限,将一定尺度内将通信开销控制在常量时间复杂度。

Pipeline communication
在 Late-multiply 中,针对全连接层计算量小,模型尺寸大的特点,对于多机之间的梯度汇总逻辑进行了优化,将「多个 worker 计算本地梯度,在所有结点之间完成信息交互」的分布式逻辑调整为「多个 worker 将全连接层的上下两层 layer 的后向传播梯度及激活值在所有计算结点之间完成信息交互」,当全连接层所包含的隐层神经元很多时,会带来比较显著的性能提升。

Without late-multiply

With late-multiply
在 Hybrid-parallelism 中,针对不同模型网络的特点,引入数据并行与模型并行的混合策略,针对计算占比高的部分应用数据并行,针对模型通信量大的部分应用模型并行,在多机计算加速与减少通信开销之间获得了较好的平衡点。下图看出将这个优化策略应用在 TensorFlow 里 AlexNet 模型的具体体现。
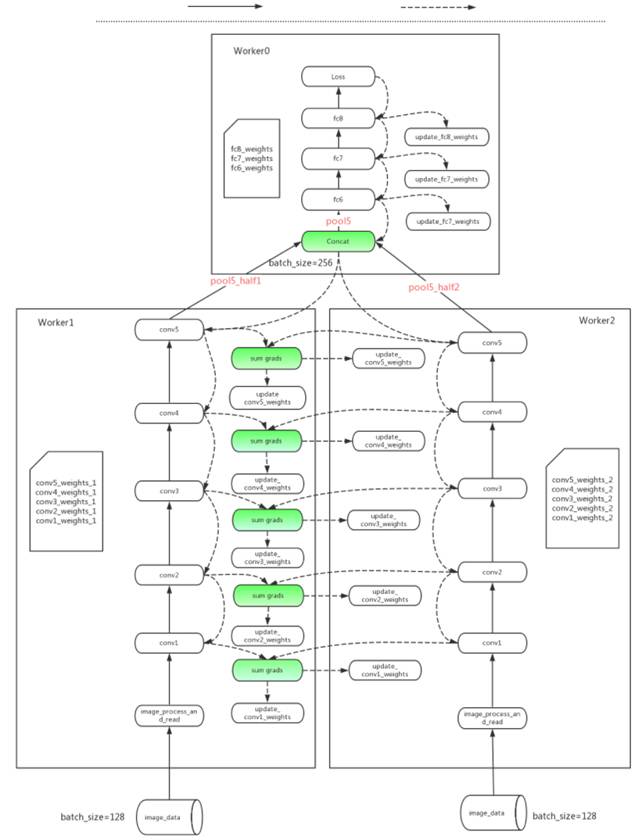
AlexNet with hybrid-parallelism
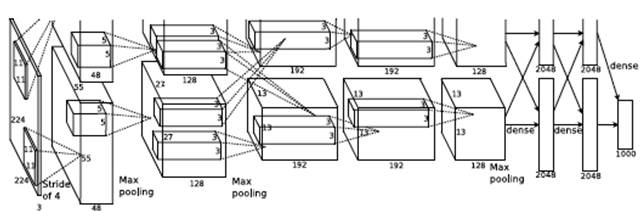
AlexNet 模型示例
性能预估模型
对于建模人员来说,他们关心的往往是以最具性价比的方式完成他们的建模训练任务,而不是用多少张卡,以什么样的分布式执行策略来完成他们的训练任务。而目前深度学习训练工具以及训练任务的复杂性,使得建模人员往往不得不透过 leaky abstraction 的管道,去关心为了完成他们的一个建模实验,应该使用多少张 GPU 卡,多少个 CPU 核、什么样的通信介质以及选择哪种分布式执行策略,才能有效地完成自己的训练任务。
基于性能预估模型,是期望能够将建模人员从具体的训练任务执行细节中解放出来。具体来说,给定建模用户的一个模型结构,以及所期望花费的费用和时间,PAI 平台会采用模型+启发式的策略预估出需要多少硬件资源,使用什么样的分布式执行策略可以尽可能逼近用户的期望。
软硬件协同优化
上面提到的三个优化策略主要集中在任务的离线训练环节,而深度学习在具体业务场景的成功应用,除了离线训练以外,也离不开在线布署环节。作为典型的复杂模型,无论是功耗、计算性能还是模型动态更新的开销,深度学习模型为在线部署提出了更高的要求和挑战。在 PAI 平台里,关于在线部署,除了实现软件层面的优化,也探索了软硬件协同优化的技术路线。目前在 PAI 平台里,阿里云技术团队正在基于 FPGA 实现在线 inference 的软硬件协同优化。在 PAI 里实现软硬件协同优化的策略与业界其他同行的作法会有所不同,我们将这个问题抽象成一个 domain-specific 的定制硬件编译优化的问题,通过这种抽象,我们可以采取更为通用的方式来解决一大批问题,从而更为有效地满足模型多样性、场景多样性的需求。
在 PAI 2.0 介绍的最后环节,周靖人博士展示了它的相关使用案例以及已经广泛的应用前景。

本文为机器之心原创,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):hr@jiqizhixin.com
投稿或寻求报道:editor@jiqizhixin.com
广告&商务合作:bd@jiqizhixin.com