谷歌开源NLP模型可视化工具LIT,模型训练不再「黑箱」
计算机视觉研究院专栏
作者:Edison_G

深度学习模型的训练就像是「黑箱操作」,知道输入是什么、输出是什么,但中间过程就像个黑匣子,这使得研究人员可能花费大量时间找出模型运行不正常的原因。假如有一款可视化的工具,能够帮助研究人员更好地理解模型行为,这应该是件非常棒的事。
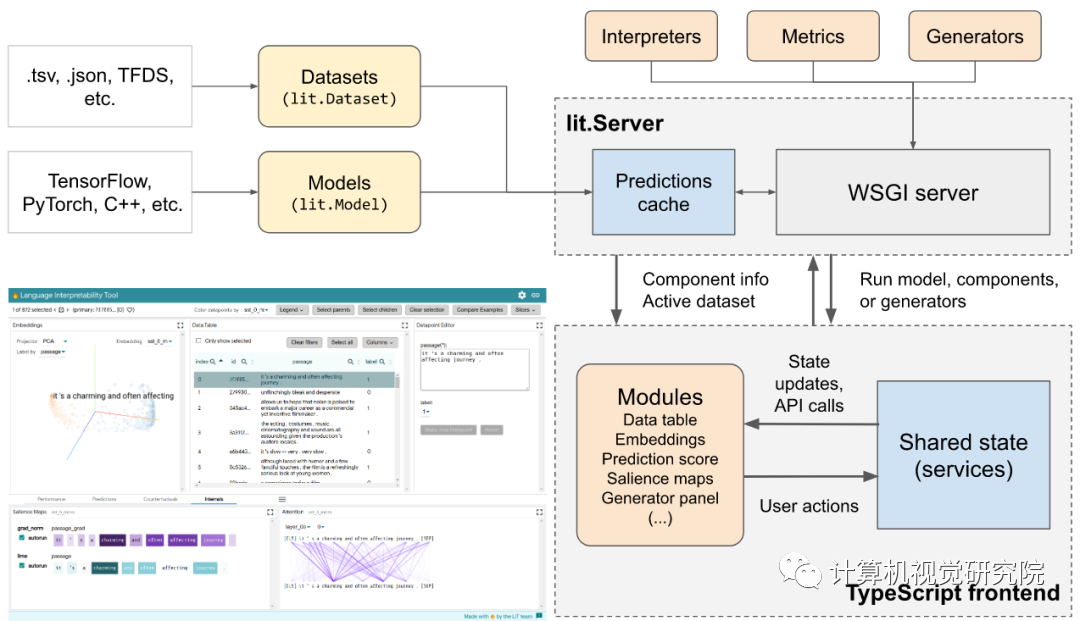
近日,Google 研究人员发布了一款语言可解释性工具 (Language Interpretability Tool, LIT),这是一个开源平台,用于可视化和理解自然语言处理模型。
论文地址:https://arxiv.org/pdf/2008.05122.pdf
项目地址:https://github.com/PAIR-code/lit
LIT 重点关注模型行为的核心问题,包括:为什么模型做出这样的预测?什么时候性能不佳?在输入变化可控的情况下会发生什么?LIT 将局部解释、聚合分析和反事实生成集成到一个流线型的、基于浏览器的界面中,以实现快速探索和错误分析。
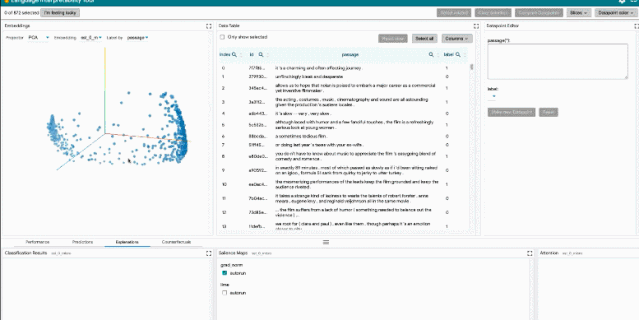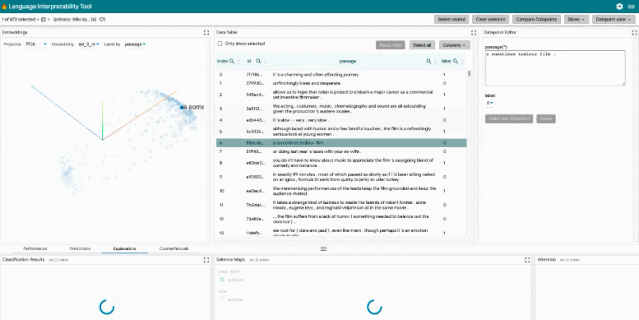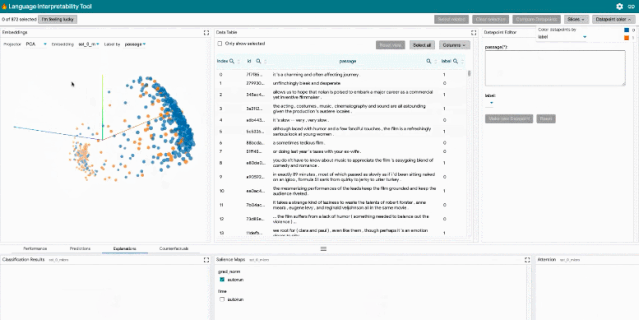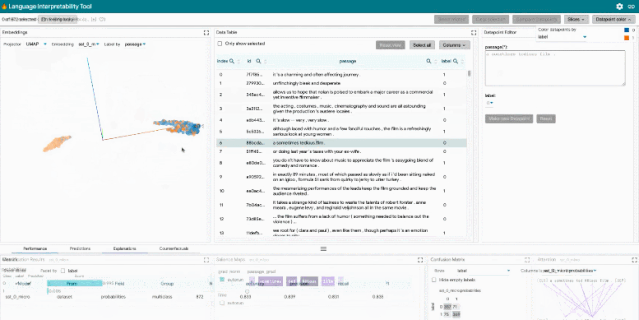
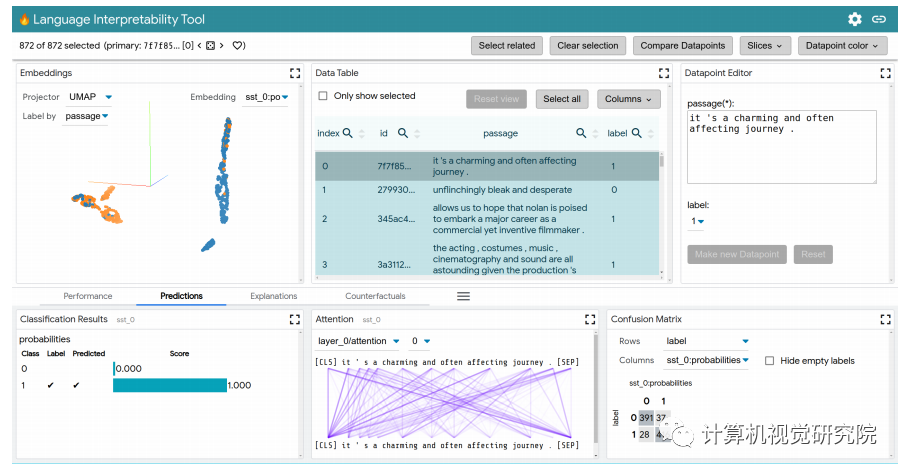
LIT 通过基于浏览器的用户界面(UI)支持各种调试工作流。功能包括:
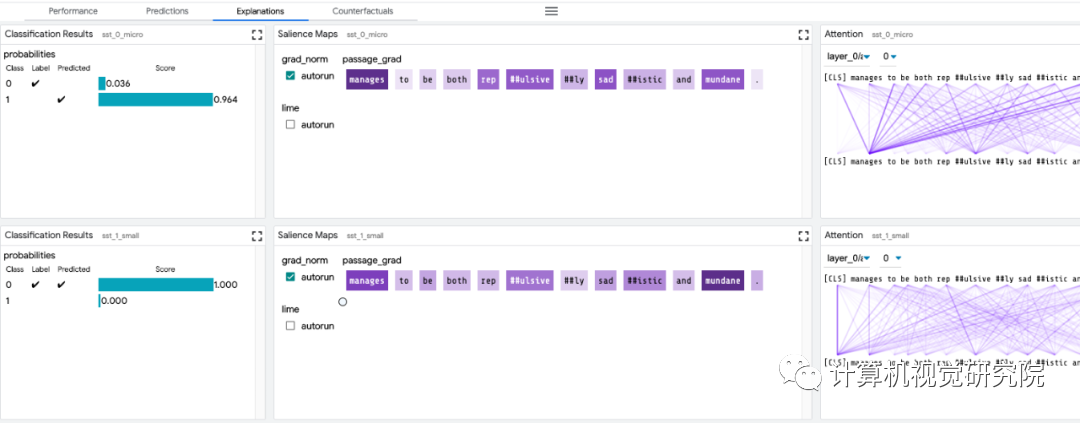
局部解释:通过模型预测的显著图、注意力和丰富可视化图来执行。
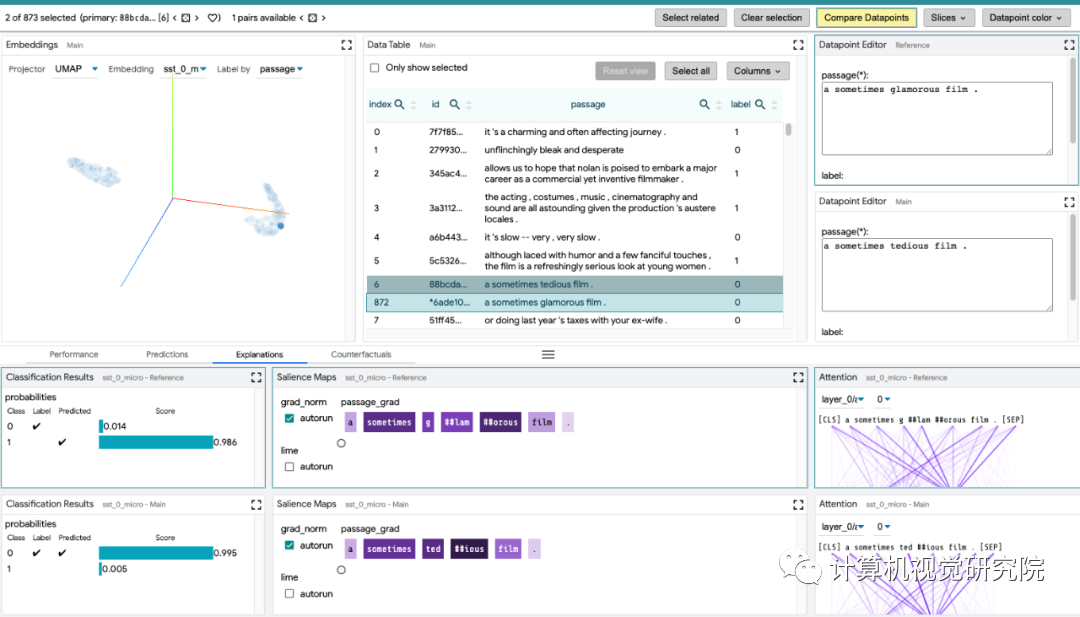
聚合分析:包括自定义度量指标、切片和装箱(slicing and binning),以及嵌入空间的可视化。
反事实生成:通过手动编辑或生成插件进行反事实推理,动态地创建和评估新示例。
并排模式:比较两个或多个模型,或基于一对示例的一个模型。
高度可扩展性:可扩展到新的模型类型,包括分类、回归、span 标注,seq2seq 和语言建模。
框架无关:与 TensorFlow、PyTorch 等兼容。
下面我们来看 LIT 的几个主要模块:
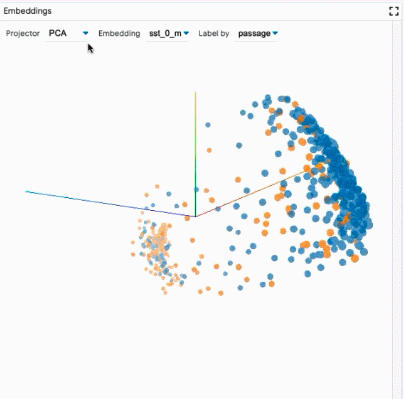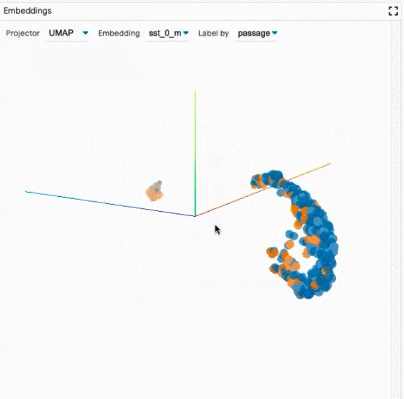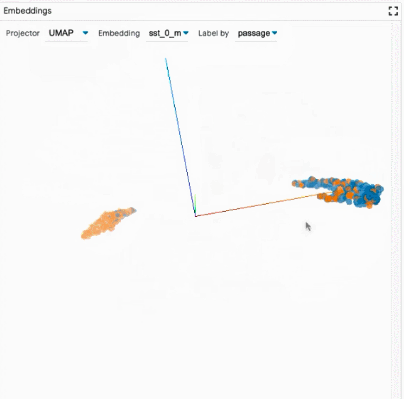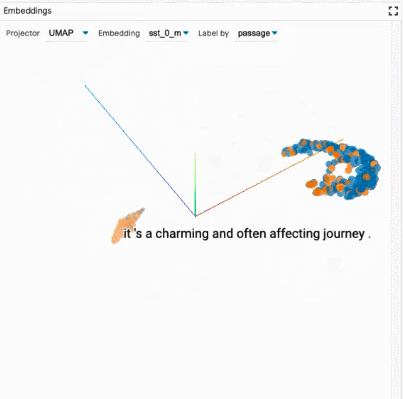
探索数据集:用户可以使用不同的标准跨模块(如数据表和嵌入模块)交互式地探索数据集,从而旋转、缩放和平移 PCA 或 UMAP 投影,以探索集群和全局结构。
git clone https://github.com/PAIR-code/lit.git ~/lit# Set up Python environmentcd ~/litconda env create -f environment.ymlconda activate lit-nlpconda install cudnn cupti # optional, for GPU supportconda install -c pytorch pytorch # optional, for PyTorch# Build the frontendcd ~/lit/lit_nlp/clientyarn && yarn buildcd ~/litpython -m lit_nlp.examples.quickstart_sst_demo --port=5432cd ~/litpython -m lit_nlp.examples.pretrained_lm_demo --models=bert-base-uncased \ --port=5432http://www.iibrand.com/news/202008/1719096.html
https://github.com/PAIR-code/lit/blob/main/docs/user_guide.md
https://github.com/PAIR-code/lit/blob/main/docs/python_api.md#adding-models-and-data
-
https://medium.com/syncedreview/google-introduces-nlp-model-understanding-tool-ab840b456be3


长按扫描维码关注我们

