优酷大数据OLAP技术选型


分享嘉宾:五羖 阿里文娱 技术专家
编辑整理:汤志敏
出品平台:DataFunTalk、AI启蒙者
目前优酷的工作类型广泛,既有会员营销这种比较复杂的分析,又有优酷播放器性能优化这种对实时性要求比较强的业务需求,在不同的业务场景里面需要使用不同OLAP引擎来达到不同的效果。本文的主要内容包括:
大数据给传统数据技术带来的挑战
市面上各类大数据OLAP技术方案一览
优酷不同业务场景的OLAP选型
我们知道,大数据在市场分析、性能诊断、客户关系、数据运营、广告投放等都占据着重要的地位。同时,在利用大数据的过程中,也给我们带来了诸多挑战:
1. 大数据带来的挑战

在实际应用中的数据处理速度,假定是亿级数据量,如果使用传统的mysql进行分析需要耗时19分钟。
2. 应对挑战
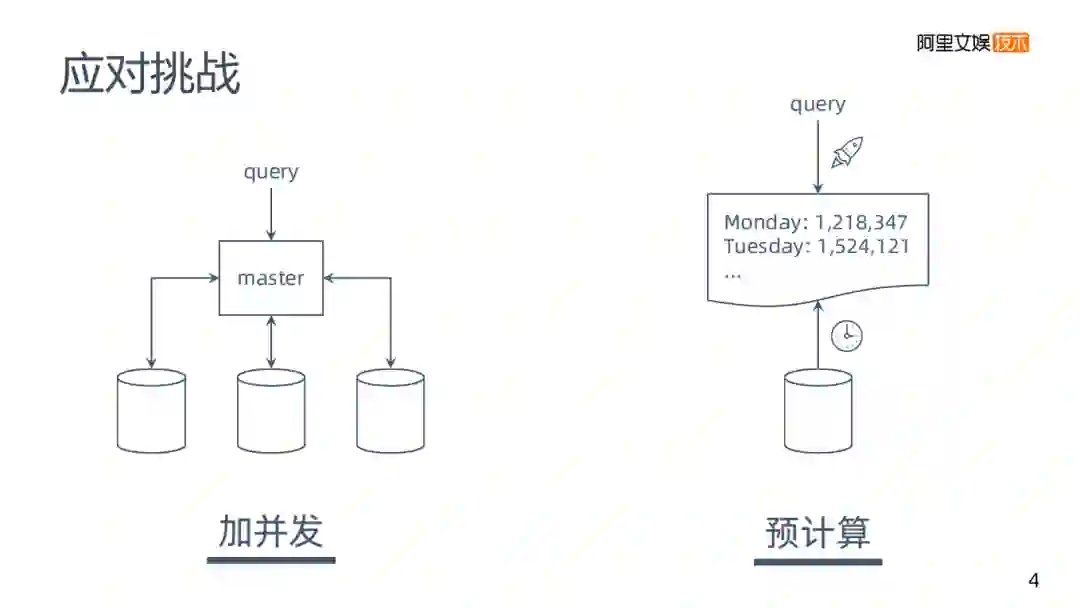
那遇到这样的问题有什么样的解决方案呢,通过对各OLAP引擎的观察,我分成了两大类:
加并发:一个mysql处理需要19分钟,那么添加多个数据实例并行计算,来减少时间。但实现是存在一定困难的。
预计算:虽然说19分钟速度是挺慢的,但是可以在预定的时间来跑数据,将数据存在性能较好的数据库里,要求是不存在原始的零星数据。预计算以后再去查询,速度会有很大改善。
这是我总结的两个在大数据下处理速度很慢问题的解决方案。下面我们来看看市面上具体的解决方案有哪些。
1. 加并发:MPP架构
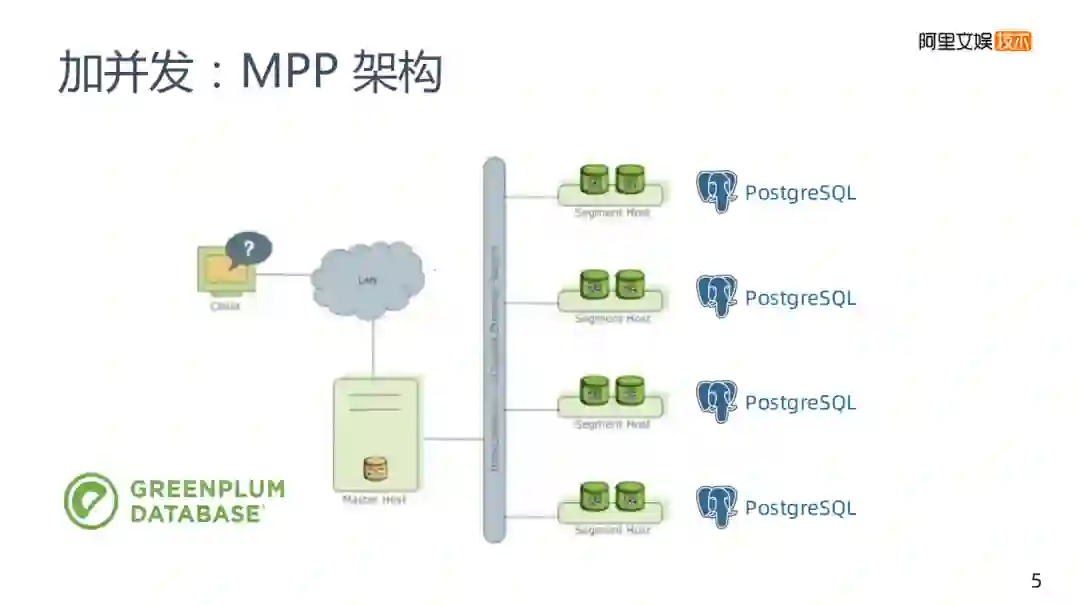
第一类的加并发方案,类似之前所说的添加多个mysql,GREENPLUM引擎也是基于一个传统的关系型数据库PostgreSQL,在GREENPLUM里面有多个PostgreSQL实例,每个实例都有Master节点去管理,再将接收到的请求拆分后分发到各实例,再将实例集中在一起返回,这就是一个MPP架构的基本原理。
MPP架构的缺陷
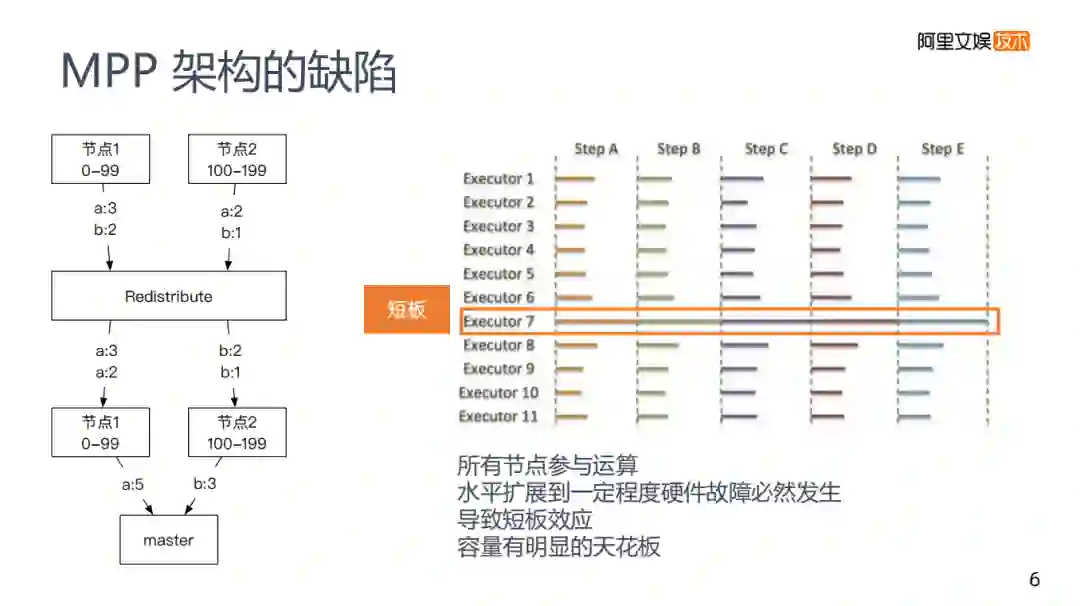
左边图是一个GREENPLUM的大致计算流程。不同的MPP架构会有所区别,但是大致原理都是差不多的,每次计算是所有节点都参与计算。
举个例子:使用group by将每个节点上a和b的数量计算出来,每个节点都做这样的运算,计算完之后会有一个Redistribute的过程,将所有key到一个节点上再去合并,最后master将数据收集起来完成计算。
存在的问题是所有的节点都参与计算,不存在特别强的水平拓展性,如果有千万级的节点必然会发生硬件故障,导致容量存在明显的天花板。
2. 加并发:批处理架构
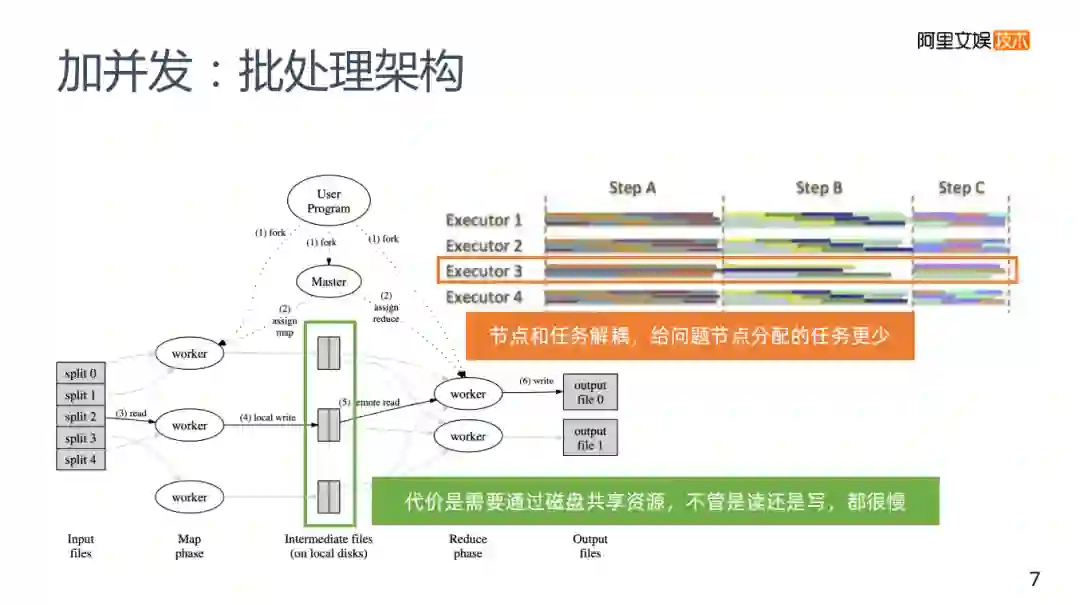
应对这样的问题的解决方案是使用批处理的架构来解决。我们平常使用的批处理架构,MR和Spark,并不需要所有的节点都参与运算,它在一个任务事件下发以后,控制节点会分配给一些集群中的节点,而这些节点各自完成自己的计算,然后把计算结果写到磁盘里,再交给下一个计算的节点去写入,每次不需要所有的节点去参与运算。因为节点和它的任务是解耦的,控制节点可以调节分配任务,来减少短板,大规模的水平扩容不会有太大的问题,但却需要一定的代价。
为什么MPP需要所有的节点去参与运算?因为运算的结果还要通过通信的方式给其他节点来进行下一步的计算,包括资源存储中各个节点是不共享的,所以需要所有的节点参与运算。
批处理架构需要节点和任务去进行解耦,解耦的代价是,需要共享资源,势必会带来写磁盘,不管是读磁盘还是写磁盘,相比MPP的通信方式来说显然会更慢。
3. 批处理&MPP的互补
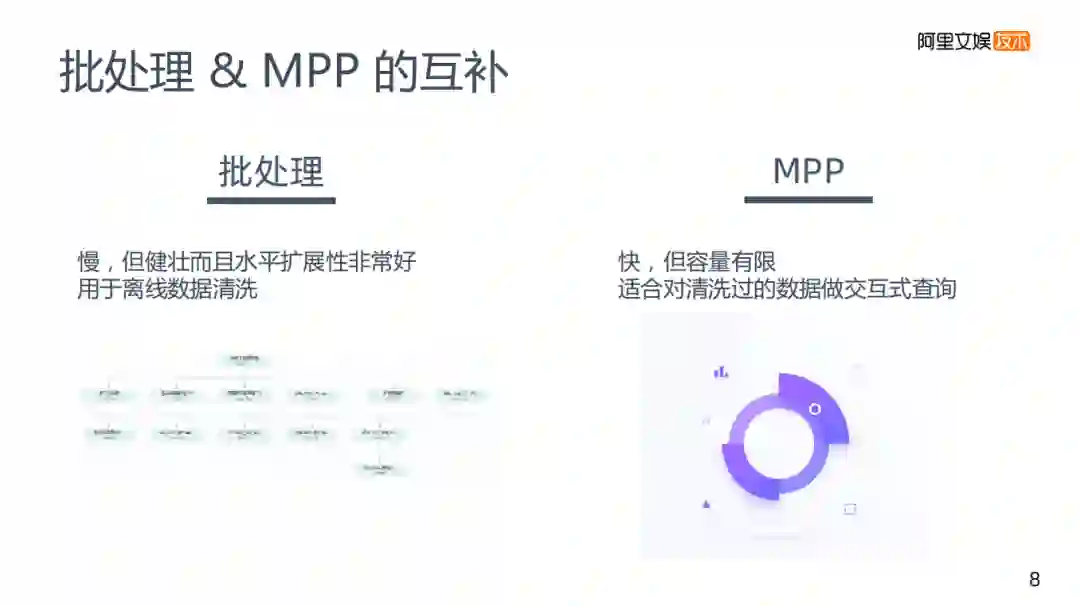
在实际使用中,两者其实是一个互补的关系,批处理速度慢,但是它的运行处理相对比较健壮,扩展性也比较好。适用于离线数据清洗。
MPP的速度虽然相对较慢,且容量无法增大,每个部门相应的集群资源需要单独去搭建。适合于对清洗过的数据做交互式查询。
4. MPP on Hadoop
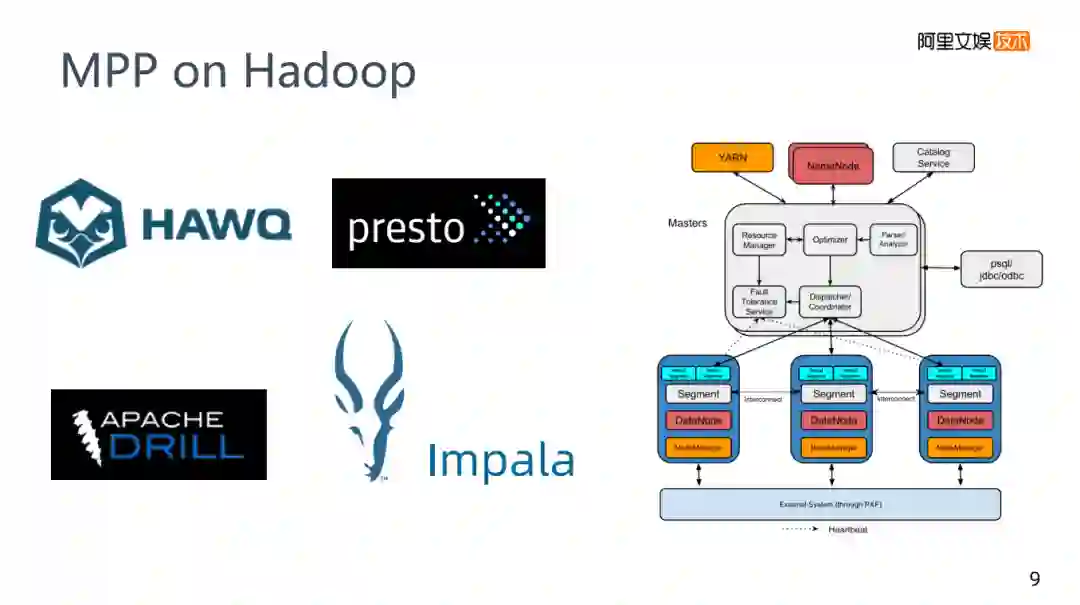
相对于互补的话,MPP on Hadoop就不得不提一下,网易使用Impala,还有相关的presto这些名字,在这里就把他们归类为MPP on Hadoop技术。MPP技术它是GREENPLUM,它的各个节点是传统关系型数据库postgre。比如,刚才场景中是先批处理再MPP,如果想用GREENPLUM,需要将Hadoop中的数据导入到GREENPLUM中,因为它们底层的存储是不一样的,Hadoop底层是HDFS,而GREENLUM底层是postgre,它们的存储上是没有关系的,必须要有一个导入的过程,正常来说Hadoop的生态,Hive是一个常用的批处理技术,它的速度比较慢,为了加速计算,就诞生了MPP on Hadoop这样的技术。
这些技术大部分没有自己的存储,是一个类MPP的架构,需要控制节点把任务下发到对应的MPP的任务节点上,而在MPP节点的底层是HDFS,等于是这两者的一个结合,实际运用起来查询会比Hive更快一些。
5. 预计算
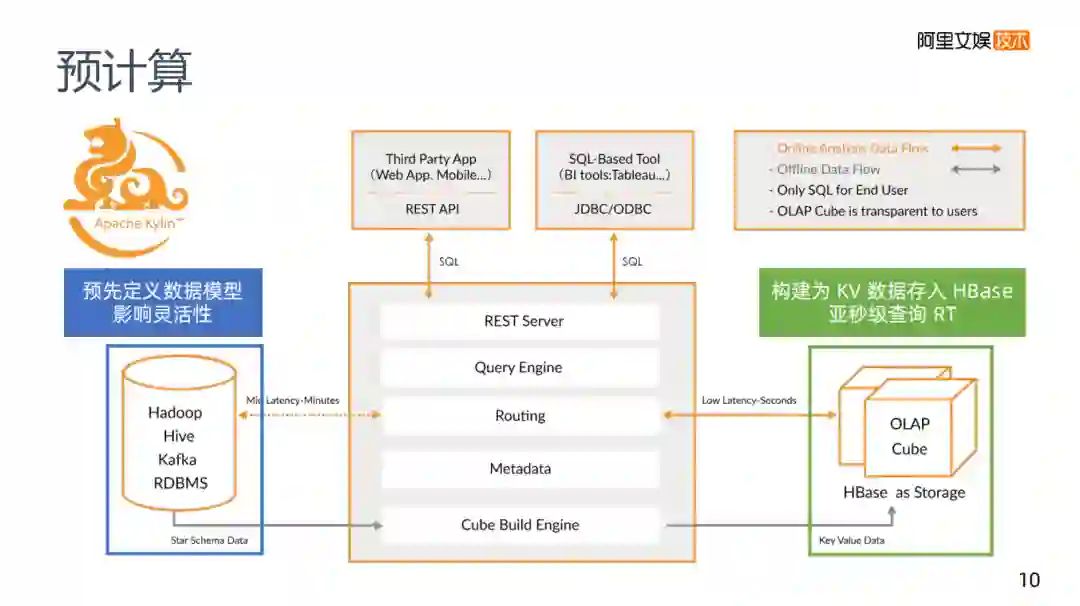
讲到预计算,就不得不提到Apache Kylin,它的架构如图,需要预先定义查询的内容。
比如说我要对某个Key进行计算,计算出A的数量,将其存在Kylin底下的HBase,它的Key是某某维度等于A,value等于A的值,因为这个Key还可能等于B,所以这个B的数据也存在HBase中,要达到这种情况,首先与Kylin之间一定要有一个交互式的协议,告诉它那些东西是我需要去查的,帮我做好计算。因为预计算中,当维度特别多的时候,是无法枚举所有要查询的东西,所以你要预先定义好Kylin,这在Kylin中叫做Cube,就是要定义你的Cube模型,告诉Kylin你的查询模式是怎么样的,而Kylin会根据定义的数据模型,去生成对应的Hive任务,Hive任务会根据模型规则去完成计算,计算好之后写入HBase里,在HBase中每一个查询对应一个Key,查询速度会很快。
这个方案绕过了大数据查询下会比较慢的问题,变成了一个HBase查询的问题,构建为KV数据存入HBase里,基本上可以达到一个亚秒级别的查询,MPP的话当数据量比较大时,需要几十秒,使用Kylin基本上是一个亚秒级的RT。但我们需要预先去定义一个数据模型,肯定会影响数据的灵活性。
比如播放的数据有没有发生卡顿,或者节点状况。我们在查询数据时,有分省份的查询,有分运营商的查询,要告诉Kylin要分省份的去查,分运营商的去查,还是需要省份和运营商交叉去查,如果没有明确,当临时的查询使用Kylin是达不到对应的效果的。业务上经常有变化,重新通过Hive去刷新任务,重新计算结果并写入HBase,这本身就是一个非常费时费力的过程,是一个变化比较大的业务。另外再维度的复杂性上也是没有上限,比如十几个维度都要各自交叉,都要去交互到很深的话,这个模式其实是没有办法支持,它的预计算结果会膨胀的特别厉害,可能会比原来的数据还要多,这时就无法进行下去。
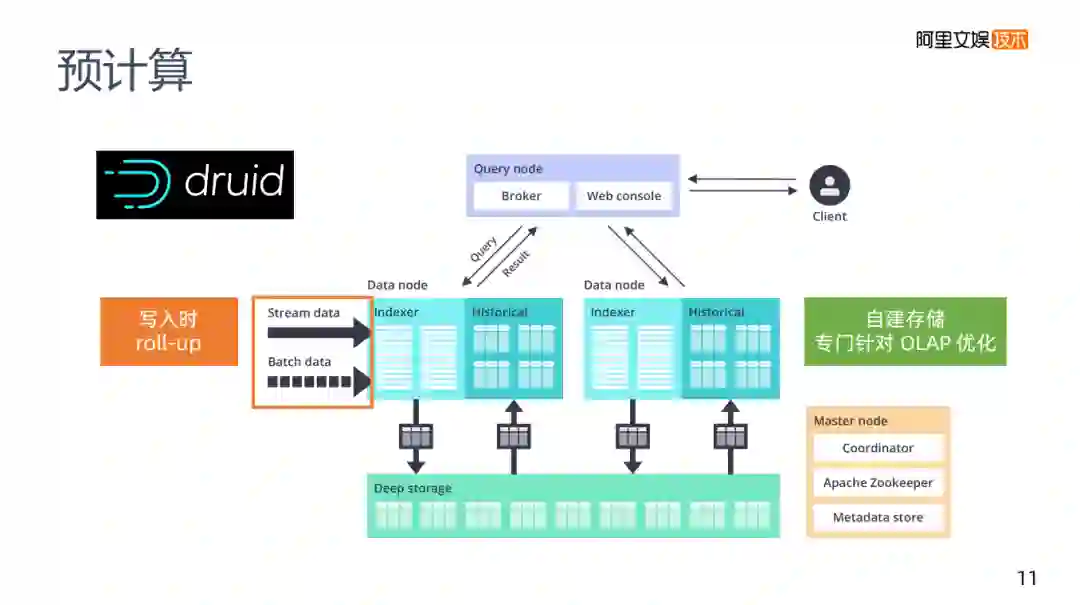
预计算还要介绍的是druid,将其归类为预计算并不是特别明确,它有预计算的能力,当数据写入时,它有一个roll-up这样的配置,在第一步数据写入时会帮助你进行一个数据减少的工作,在它本身内部的架构里,它不是Kylin需要HBase这样的存储,druid内部有一个自己的存储,专门针对OLAP进行了优化。druid还是一个时序的存储,在时序上做优化,让老的数据存在老的存储里,新的数据存在新的存储里。在预计算和查询的灵活性方面,如果说只能够选择一套方案的话,可以考虑只使用druid。
6. OLAP方案综述
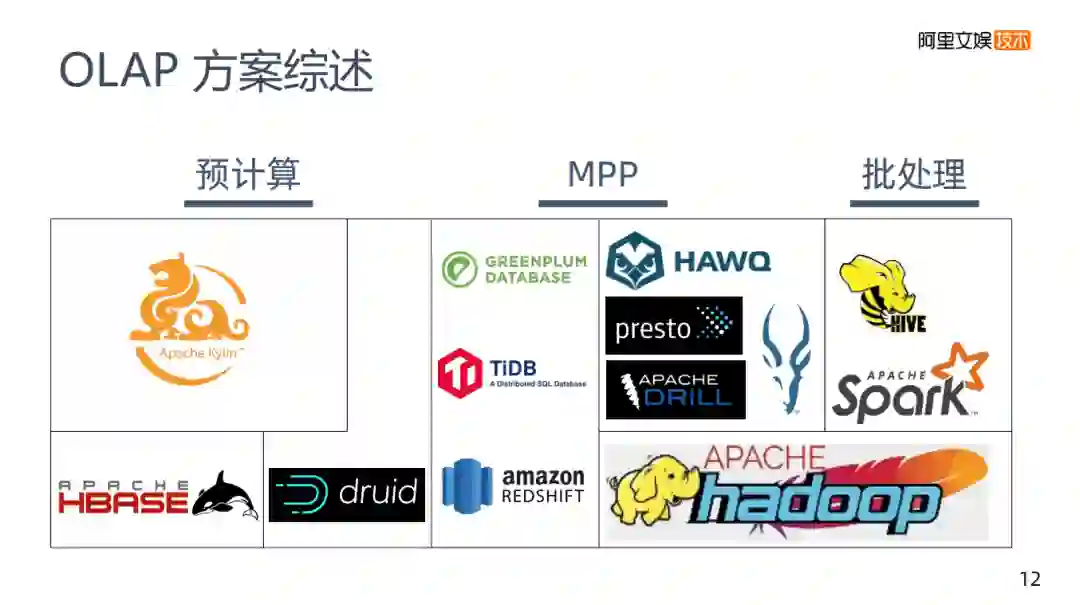
在这里将所说过的OLAP方案综述一下,将市面上的OLAP分为两种:
通过加并发的方式来解决问题:MPP架构和批处理架构
通过预计算来解决问题
图中是市面上常见的OLAP,纵向是不同的架构类型,横向是查询和存储的关系。
Kylin可以说是一个计算框架,因为它底层的存储使用的是HBase,用Kylin来解决数据如何建模的问题。
再往右就是druid,它本身有预计算的能力是自建存储的。比如说美团做了一个Kylin on druid这样的工作,计算仍然是Kylin,但是它把底层的HBase换成druid,这样做的考虑将druid和HBase比较,实际在查询的能力方面还是要强不少的。
GREENPLUM和TiDB或者amazon更偏向于传统架构,都是关系型的数据库,需要有自己的存储。
再往右就是基于HDFS的架构,HIVE和Spark都是基础HDFS上做的批处理。
1. 实战性场景
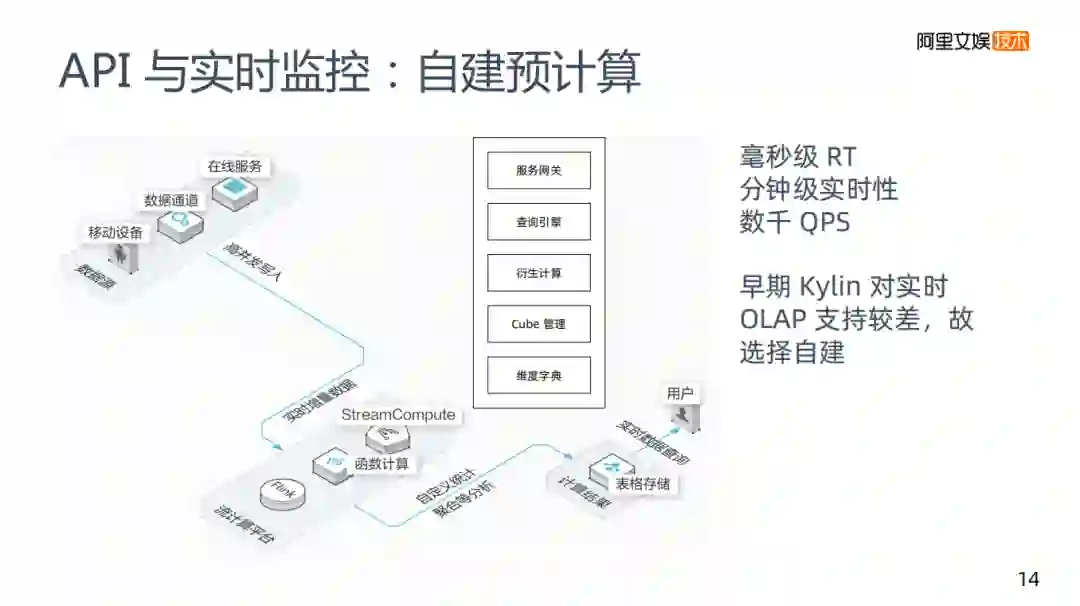
第一类场景是API与实时监控:API是系统访问,比如在我们的推荐系统里,需要用到一些实时特征,如用户截至目前曝光了多少次,会存在非常大的QPS,以及对RT要求很高,数据也要有分钟级的实时性要求。API与实时监控,目前在优酷是自建的预计算系统。
为什么早期没有使用Kylin,是因为实时OLAP当时支持较差。Kylin和Hive还是有很强的依赖的。首先就是数据的收集,业界一般主要使用kafka,这里使用类似Kafka这种消息队列,会把流式的信息导入进来,流计算使用Flink,内部也存在Cube管理这样类似的协议,聚合得到和Kylin一样的KV结构数据,存储在阿里的表格存储里,和HBase差别比较小,然后用户去读取数据。
从思路上来说和Kylin差别不是很大,在预计算系统里面我们会提供一些网关服务,因为要对外提供API,如果是报表的话也要根据报表平台来访问的,然后会有自己的查询引擎,解析类SQL这样的语法,把它解析成表格存储里面的数据。
另外也做了一块叫做维度计算,针对业务上变化速度快,也会尝试在KV结构上做计算,可能包括一些数学运算。
最后一个是维度字典,在实际使用中是非常重要的。比如版本的维度一直在变化,如果是在这样一个HIVE的平台里,可能使用Groupby可以查出具体版本,在将数据进行预计算后,存储在类似HBase的KV存储中。制作维度字典对应用性有比较好的提高,
2. BI报表:批处理+MPP
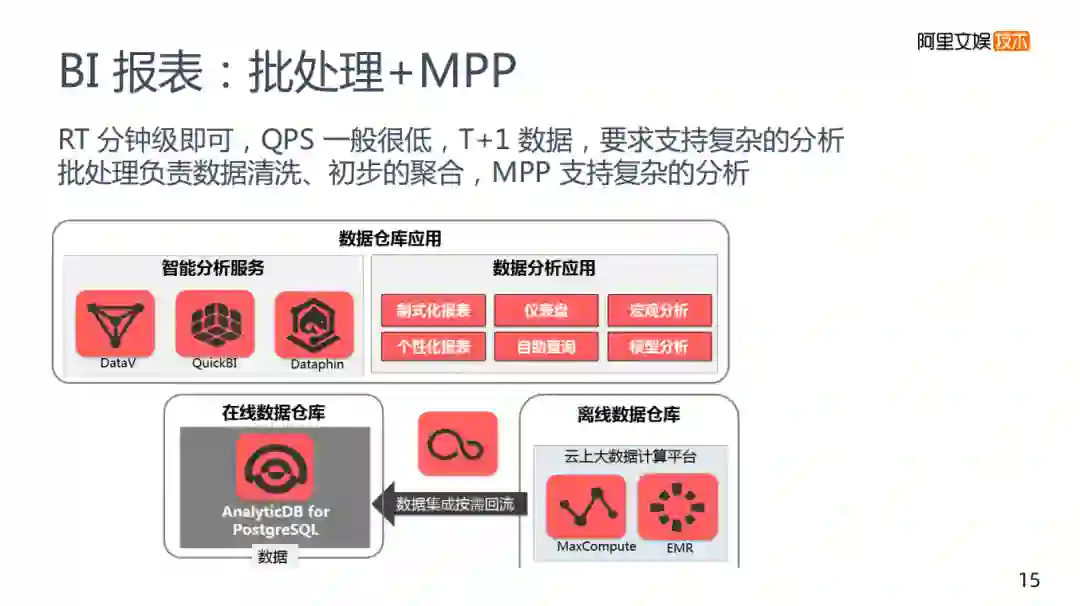
第二类是BI报表,是批处理+MPP组合的形式,其中对业务中的RT和QPS要求不高,重点在于需要支持非常复杂的分析,最好使用的方案其实是批处理+MPP,批处理这层主要是进行数据清洗初步的聚合,如果是优酷的数据量,基本上是一分钟两分钟这种级别,速度上较慢。
通过对业务的理解,将关键的数据保留,通过批处理预先建好DWS层的模式处理,在这基础之上,往MPP的表中导入从而支持这个复杂的分析,底层的架构是一个离线的批处理的计算,批处理完成之后将数据放入离线的表中,并导入到阿里的数仓,使用MPP的数仓来支持,以及BI类工具来支持我们的业务需求,满足复杂分析的要求。
3. 实时ad-hoc:类似ELK
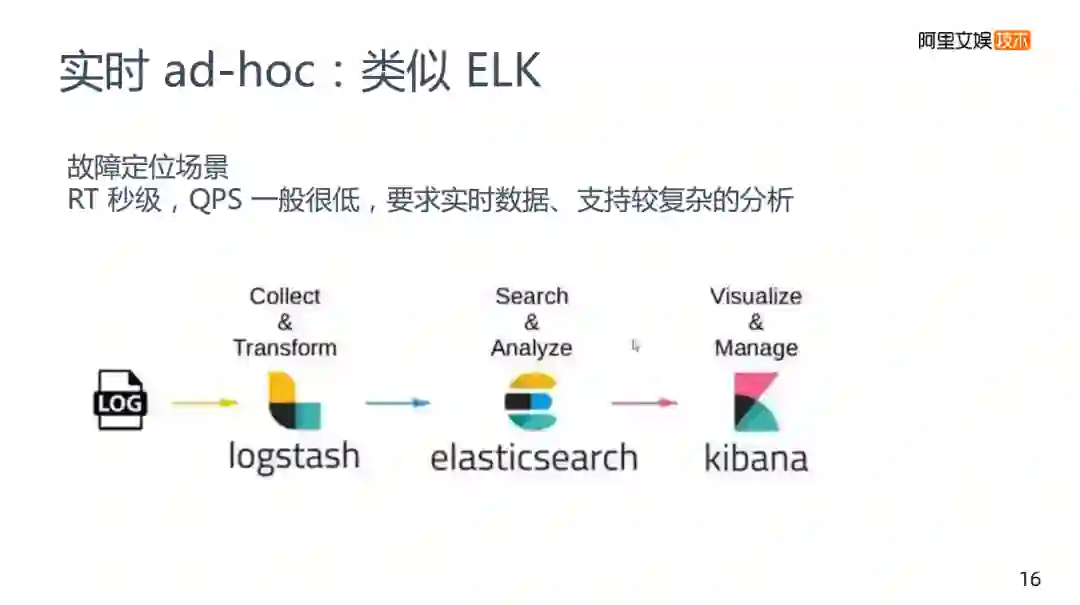
第三类场景是实时查询的一种场景,跟刚才的BI类又不相同,主要发生在优酷性能的统计数据里面,在这个场景下我们一般做预计算,但偏向实时的,分析比较复杂,通常适用于故障定位的场景。
比如如何去定位查找错误,查找机房存在问题,这都是一些比较常见的场景。这个场景对RT的要求较好。RT和QPS方面没有API要求那么高,它的用户人数也不是那么多,没有一些高并发的场景,但是对数据的实时性和分析的复杂性还是存在要求的,这种的预计算也不大可能去满足,为解决这类问题,我们做的是一个类似ELK的方案。
首先是需要收集log,在收集的过程中要做数据清洗,将数据存到es中,es在大数据里面也是比较常用的,适用于故障排查的场景,搜索关键词、模糊搜索等。es的聚合能力,过滤能力都是相对比较经典的。但确实模糊查询也没有很刻意的提出这个概念,甚至有些不支持模糊查询,比如说Kylin,es主打是模糊查询,但是es也实现了聚合功能,因为es里面是json,json里面某个字段,这个字段有多少Key,聚合以后有多少个,这种它也是能够做的。而join就相对较差,它不是一个非常完备,但是在这种重聚合,过滤夹带一些模糊查询的的情况下,还是比较适合做一个引擎。在es后是一个Kibana,但我们使用的不是Kibana,是使用内部的BI工具。
在这种场景下,当错误发生了,我们可以很快的定位到错误位置,实现实时查询的能力。
今天的分享就到这里,谢谢大家。
在文末分享、点赞、在看,给个3连击呗~

文章推荐:
社群推荐:

关于我们:
DataFunTalk 专注于大数据、人工智能技术应用的分享与交流。发起于2017年,在北京、上海、深圳、杭州等城市举办超过100场线下沙龙、论坛及峰会,已邀请近600位专家和学者参与分享。其公众号 DataFunTalk 累计生产原创文章300+,百万+阅读,8万+精准粉丝。

🧐分享、点赞、在看,给个3连击呗!👇





