教程 | 百行代码构建神经网络黑白图片自动上色系统
选自freecodecamp
作者:Emil Wallnér
机器之心编译
使用神经网络对图片进行风格化渲染是计算机视觉领域的热门应用之一。本文将向你介绍一种简单而有效的黑白图片上色方法,仅需 100 行代码,你也可以搭建自己的神经网络,几秒钟内让计算机自动完成手动工作需要几个月的任务。
今年 7 月,Amir Avni 用神经网络向 Reddit 的 Colorization 社区宣战——那是一个为历史黑白照片上色的版面,用户们通常使用的工具是 Photoshop。
社区用户们惊讶于 Amir 的深度学习系统。以前人们需要几个月手工上色的任务在计算机那里只需要几秒钟就完成了。我也被 Amir 的神经网络迷住了,所以在看到结果之后我开始试着复现它。首先,让我们看看我们自动上色的成果/失败品。

目前,图片上色的工作主要由人们通过 Photoshop 手工完成,这需要相当多的工序和时间。
简而言之,一张照片可能需要一个月的时间来上色。对于画师来说,这还意味着很多研究工作,一张人脸可能需要 20 张粉色、绿色和蓝色图层,经过不断调整最终才能获得正确的效果。
本文面向初学者,如果你认为自己对于深度学习理解不足,可先看看:
https://blog.floydhub.com/my-first-weekend-of-deep-learning/
https://blog.floydhub.com/coding-the-history-of-deep-learning/
Andrej Karpathy 的 CS231 课程视频:https://www.youtube.com/watch?v=LxfUGhug-iQ
本文将展示如何三步构建自己的神经网络上色系统。
第一部分先解释核心逻辑。我们会构建一个 40 行的神经网络作为「Alpha」上色机器人,其中没有应用到太多深度技术,这个过程会让我们熟悉模型的核心机制。
第二部是创建一个可以泛化的神经网络——我们的「beta」版本。它可以让我们对此前未见的图片进行上色。
在「正式版」中,我们会将神经网络与分类器相结合。我们会使用训练过 120 万张图片的 Inception ResNet V2,为了让上色风格更符合现代审美,我们使用 Unsplash 上的图片来训练神经网络。
该项目的
Jupyter Notebook:https://www.floydhub.com/emilwallner/projects/color/43/code/Alpha-version/alpha_version.ipynb
FloydHub:https://www.floydhub.com/emilwallner/projects/color/43/code
GitHub:https://github.com/emilwallner/Coloring-greyscale-images-in-Keras
FloydHub 上的云 GPU 实验:https://www.floydhub.com/emilwallner/projects/color/jobs
核心逻辑
在本节中,我会介绍如何渲染图像,数字色彩的机理以及神经网络的主要逻辑。黑白图片可以在像素网格中表示。每个像素由对应其亮度的数值,范围在 0-255 之间,对应从黑到白。

彩色图像(RGB)由三个层组成:红色层、绿色层与蓝色层。若将白色背景上一片绿叶的图片分析为三个通道。直观地,你可能认为树叶只存在于绿色层。但是正如你所见到的,树叶在三个通道中都出现了,这是因为图层不仅决定颜色,还决定亮度。

为了实现白色,你需要让三种颜色的分布平均,通过为红色和蓝色加入相同数值——结果就是绿色变得更亮了。所以,彩色图像使用三个通道的数值对比对颜色进行编码。
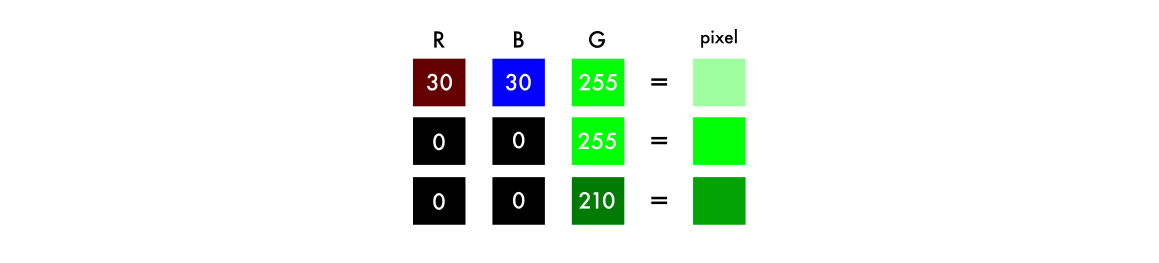
对于黑白图片,每个图层的数值都是 0-255 之间的相同值。如果所有通道数值为 0,则这个像素为黑色。你可能知道神经网络会在输入与输出之间构建联系。将这个思路归纳到我们的着色任务中——神经网络需要找到灰度图像和彩色图像之间的联系。
再准确一点,我们在寻找的是将灰度值链接到三色图层数值的方法。

Alpha 版本
我们将从神经网络的简单版本开始,先来为这张图片中的人脸进行着色。这样你就可以熟悉模型的核心机制了。
只需 40 行代码,我们就可以做到下图中的着色效果。下图中间是神经网络的着色,而右侧是原图。神经网络也经过了这张图的训练。在 Beta 版本的段落中我们将对此进行详细解释。

色彩空间
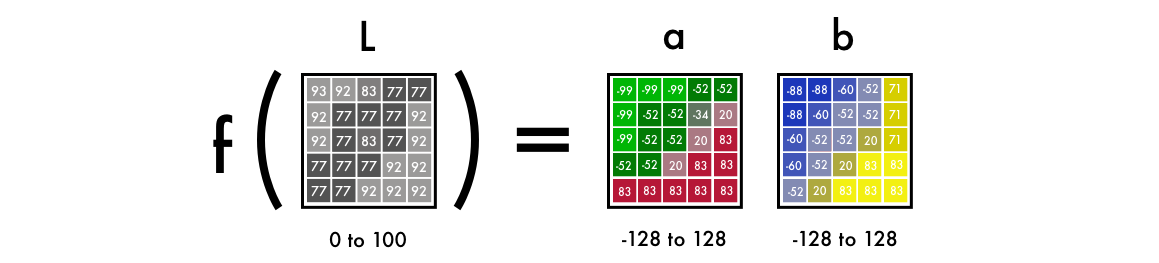
首先,我们需要用算法来改变颜色通道,从 RGB 到 Lab。L 代表亮度,而 a 和 b 代表颜色光谱绿-红和蓝-黄。
正如下图所示,Lab 编码的图片有一个灰度层,而颜色层由三个减少为两个。这意味着我们可以在最终的预测中使用原来的灰度图片,同时只需要预测两个通道。

从实验上来说,人类眼睛里大约 94% 的细胞是用来探测亮度的,只有剩下 6% 是用来感应颜色的。正如你在上图中所看到的,灰度图比颜色图看起来清楚多了,这也是我们需要在神经网络输出中保留灰度图的另一个原因。
从黑白到彩色
神经网络的最终预测就像这样:我们有一张灰度图的输入,我们希望以此来预测两个色彩图层,Lab 中的 ab。最终的图像包括了输入的灰度图层 L 和预测的两个图层,最终组成 Lab 图片。
为了将一层转换为两层,我们需要使用卷积滤波器。你可以把他们想象为 3D 眼镜中的蓝/红色偏振镜。每个偏振镜都会决定我们看到的图片是什么样的,它可以突出或删除图片中的部分信息。神经网络也可以从一个/多个过滤器组合之上创造新的图像。
对于卷积神经网络而言,每一个滤波器都会自动调整以帮助达到预期的结果。我们先要从堆叠数百个滤波器,并将它们塞进两个颜色图层 a、b 中做起。不过首先,我们来看看代码。
在 FloydHub 中部署代码
如果你不太了解 FloydHub,你可以先看看它的安装指南:
https://www.floydhub.com/
或我的上手指南:
https://blog.floydhub.com/my-first-weekend-of-deep-learning/
Alpha 版本
安装完 FloydHub 后,键入下列命令:
git clonehttps://github.com/emilwallner/Coloring-greyscale-images-in-Keras
打开文件夹,启动 FloydHub。
cd Coloring-greyscale-images-in-Keras/floydhub
floyd init colornet
FloydHub 的网络控制面板就在网页里。系统将提示你创建一个名为 colornet 的新 FloydHub 项目。一旦完成,回到你的终端并运行相同的 init 命令。
floyd init colornet
好了,开始运行我们的程序:
floyd run --data emilwallner/datasets/colornet/2:data --mode jupyter --tensorboard
注意:我们已经在 FloydHub 上安装了一个公开数据集(我已经上传了),数据集的目录在这里:
--dataemilwallner/datasets/colornet/2:data
你可以直接在 FloydHub 上使用这个数据集(其他的也是)并且:
通过--tensorboard 指令开启 Tensorboard
通过--mode jupyter 指令运行 Jupyter Notebook 模式
如果你有可用 GPU,你可以在命令行中加入 GPU flag: --gpu,这样训练的速度可以大约快上 50 倍。
在 FloydHub 网站的 Jobs 标签下,点击 Jupyter Notebook 链接,并找到这个文件:
floydhub/Alpha version/working_floyd_pink_light_full.ipynb
打开它,并运行所有代码块,随着逐渐增加的 epoch 值,我们可以体会神经网络是如何学习的。
model.fit(x=X, y=Y, batch_size=1, epochs=1)
首先从 epoch 值为 1 开始,逐渐增加到 10、100。Epoch 的数值表示神经网络从训练集图像中学习的次数。在训练完神经网络后,你可以在的 img_result.png 主文件夹中找到结果图。
# Get images image = img_to_array(load_img('woman.png')) image = np.array(image, dtype=float) # Import map images into the lab colorspace X = rgb2lab(1.0/255*image)[:,:,0] Y = rgb2lab(1.0/255*image)[:,:,1:] Y = Y / 128X = X.reshape(1, 400, 400, 1) Y = Y.reshape(1, 400, 400, 2) model = Sequential() model.add(InputLayer(input_shape=(None, None, 1))) # Building the neural network model = Sequential() model.add(InputLayer(input_shape=(None, None, 1))) model.add(Conv2D(8, (3, 3), activation='relu', padding='same', strides=2)) model.add(Conv2D(8, (3, 3), activation='relu', padding='same')) model.add(Conv2D(16, (3, 3), activation='relu', padding='same')) model.add(Conv2D(16, (3, 3), activation='relu', padding='same', strides=2)) model.add(Conv2D(32, (3, 3), activation='relu', padding='same')) model.add(Conv2D(32, (3, 3), activation='relu', padding='same', strides=2)) model.add(UpSampling2D((2, 2))) model.add(Conv2D(32, (3, 3), activation='relu', padding='same')) model.add(UpSampling2D((2, 2))) model.add(Conv2D(16, (3, 3), activation='relu', padding='same')) model.add(UpSampling2D((2, 2))) model.add(Conv2D(2, (3, 3), activation='tanh', padding='same')) # Finish model model.compile(optimizer='rmsprop',loss='mse') #Train the neural network model.fit(x=X, y=Y, batch_size=1, epochs=3000) print(model.evaluate(X, Y, batch_size=1)) # Output colorizations output = model.predict(X) output = output * 128canvas = np.zeros((400, 400, 3)) canvas[:,:,0] = X[0][:,:,0] canvas[:,:,1:] = output[0] imsave("img_result.png", lab2rgb(cur)) imsave("img_gray_scale.png", rgb2gray(lab2rgb(cur)))
运行神经网络的 FloydHub 命令:
floyd run --data emilwallner/datasets/colornet/2:data --mode jupyter --tensorboard
技术说明
简单来说,输入就是以网格表示的黑白图像,输出是两个具有颜色值的网格。在输入和输出之间用滤波器将它们连接起来。这是一个卷积神经网络。
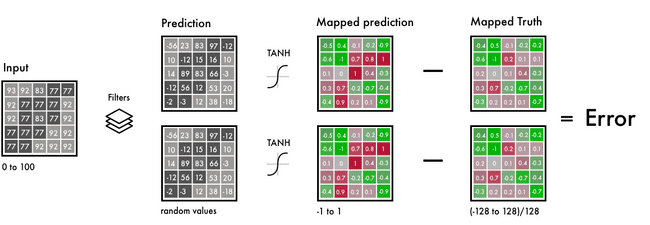
从左侧开始,分别是 B&W 输入、滤波器和神经网络的预测。
我们需要在相同的区间将预测值和真实值建立映射,从而将值进行比较。区间的范围在-1 到 1 之间。为了映射预测值,我们使用了 tanh 激活函数。tanh 函数的任意输入的输出值都在-1 到 1 之间。
真实的颜色值分布在-128 到 128 的区间内。这是 Lab 色彩空间的默认区间。用 128 除这些值就能获得-1 到 1 的区间分布。这种「标准化」操作使我们能比较预测的误差。
计算除最后的误差之后,网络将更新滤波器以减少总误差。网络会持续迭代这个过程直到误差尽可能的小。接下来我们将描述代码片段中的一些想法与表达。
X = rgb2lab(1.0/255*image)[:,:,0]
Y = rgb2lab(1.0/255*image)[:,:,1:]
1.0/255 表示我们使用了一个 24 比特的 RGB 色彩空间,意味着在每个色彩通道中使用 0-255 之间的一个数字,总共有 1670 万个色彩组合。
由于人类只能感知 200 万到 1000 万种颜色,使用这么大的色彩空间不太必要。
Y = Y / 128
Lab 色彩空间的分布范围和 RGB 不同。Lab 的色谱范围从-128 到 128。通过用 128 除输出层的值,可以将范围转换为-1 到 1。
我们的神经网络的输出也是在这个范围内,因此可以互相匹配。
在使用 rgb2lab() 函数转换色彩空间后,我们用 [ : , : , 0] 选择灰度层,这是神经网络的输入,[ : , : , 1: ] 选择的是绿-红、蓝-黄这两个层。在训练了神经网络之后,根据最后预测结果生成图像。
output = model.predict(X)
output = output * 128
在这里,我们使用灰度图像作为输入,并用于训练神经网络。我们对所有的位于-1 到 1 范围内输出乘上 128,从而得到 Lab 色彩空间的真实颜色。
canvas = np.zeros((400, 400, 3))
canvas[:,:,0] = X[0][:,:,0]
canvas[:,:,1:] = output[0]
最后,通过三层全为 0 值的网格创建一个黑色 RGB 画布,然后从测试图像中复制灰度图像,并将这两个颜色层添加到 RGB 画布上去,最后将这个像素值阵列转换为一张图像。
研究经验
阅读研究文献是个难关:一旦我总结了每一篇论文中的核心特征之后,浏览论文就变得容易多了,我还学会将细节放入特定的背景中理解。
从简单的开始很关键:我在网上找到的大多数实现都是 2000 到 10000 行的长度的代码。这使得理解问题的核心逻辑变得很困难。一旦获得主要思维框架之后,阅读代码实现和研究文献就变得容易多了。
探索开源项目:为了粗略理解写代码的要领,我在 GitHub 上浏览了 50-100 个着色项目。
过程不总是很顺利:在刚开始的时候,网络只能生成红色和黄色。我最初用 ReLU 函数作为最后一层的激活函数,由于它只能将数字映射为正值,而无法输出负值,即蓝色和绿色的色谱。通过改为使用 tanh 为激活函数解决了这个问题。
从理解到加速:我见过的大多数的实现工作得很快但很难使用。而我更注重模型革新的速度,而不是代码执行速度。
beta 版本
如果想理解 alpha 版本的弱点,可以尝试为未训练过的图片上色,可以看到,它通常会给出糟糕的结果,因为网络只对信息进行了记忆,从而无法为没见过的图像上色。我们将以这个方向在 beta 版本做出改进,即让它学会泛化。

特征提取器
我们的网络能找到连接灰度图像和其色彩版本的特征。
假设你需要对黑白图像上色,但因为一些限制你一次只能看到 9 个像素。你可以从左上方到右下方扫描每一张图像并尝试预测每一个像素对应的颜色。

例如,这 9 个像素是下方所示的女人的鼻孔的边缘。可以想象,这几乎不可能做出正确的上色。因此需要分成几步来完成。
首先,寻找简单的模式:对角线、所有的黑色像素,等等。在每一个方块中寻找相同的模式并移除不匹配的像素。从 64 个小型滤波器中生成 64 张新图像。

当再次扫描图像的时候,你能找到与已经检测到的相同的小范围模式。为了获得对图像的高层次的理解,需要将图像尺寸减半。
目前仍然只有一个 3x3 滤波器用于扫描每一张图像。但通过用低级的滤波器组合成新的 9 像素滤波器,可以探测更加复杂的模式。每个像素组合可能用于探测一个半圆、一个点或一条线。你可以重复地在图像中提取相同的特征。这一次总共生成了 128 张新的过滤图像。
经过几步的过滤之后,过滤图像的样子可能如下图所示:
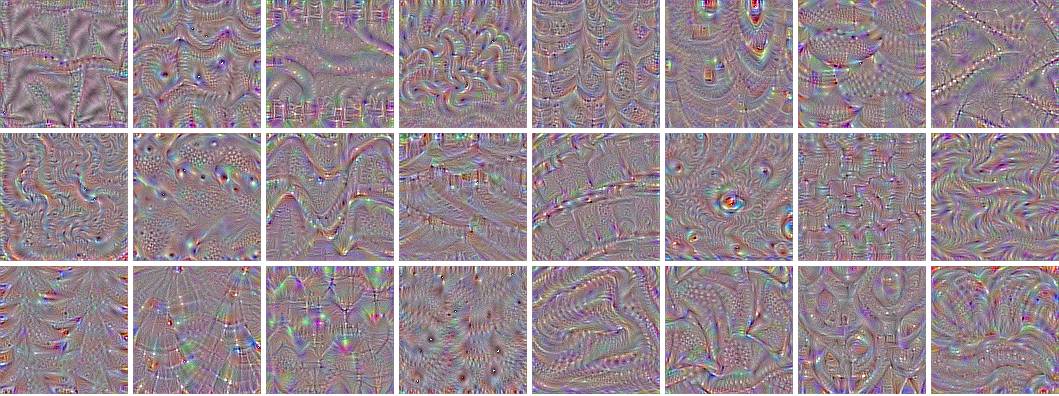
之前提到过,这个过程从低级的特征开始,比如边缘,靠近输出的层将其组合成模式,然后再组合成面部细节,最后转换成一张脸。这个视频教程中提供了更详细的解释:https://www.youtube.com/watch?v=AgkfIQ4IGaM。
整个过程和大部分处理视觉的神经网络很相似。这里用的神经网络的类型是卷积神经网络。这些网络组合多个滤波器以理解图像中的语境。
从特征提取到色彩
神经网络以试验和调试误差的方式训练。它首先为每一个像素给出一个随机预测,基于每一个像素计算出的误差,通过反向传播提升特征提取的性能。
在我们的案例中,调整网络的目标是颜色的匹配度和目标的定位。我们的网络从将所有目标转换为褐色开始。褐色是和所有其它颜色相差最小的颜色,因此产生的误差最小。
由于大多数的训练数据都很相似,网络在分辨不同的目标时遇到了困难。这将使网络在生成更加细致的颜色时失败。这将是我们在完整的版本中要探索的问题。
以下是 beta 版本的代码,随后是代码的技术解释。
# Get images X = []for filename in os.listdir('../Train/'): X.append(img_to_array(load_img('../Train/'+filename))) X = np.array(X, dtype=float) # Set up training and test data split = int(0.95*len(X)) Xtrain = X[:split] Xtrain = 1.0/255*Xtrain #Design the neural network model = Sequential() model.add(InputLayer(input_shape=(256, 256, 1))) model.add(Conv2D(64, (3, 3), activation='relu', padding='same')) model.add(Conv2D(64, (3, 3), activation='relu', padding='same', strides=2)) model.add(Conv2D(128, (3, 3), activation='relu', padding='same')) model.add(Conv2D(128, (3, 3), activation='relu', padding='same', strides=2)) model.add(Conv2D(256, (3, 3), activation='relu', padding='same')) model.add(Conv2D(256, (3, 3), activation='relu', padding='same', strides=2)) model.add(Conv2D(512, (3, 3), activation='relu', padding='same')) model.add(Conv2D(256, (3, 3), activation='relu', padding='same')) model.add(Conv2D(128, (3, 3), activation='relu', padding='same')) model.add(UpSampling2D((2, 2))) model.add(Conv2D(64, (3, 3), activation='relu', padding='same')) model.add(UpSampling2D((2, 2))) model.add(Conv2D(32, (3, 3), activation='relu', padding='same')) model.add(Conv2D(2, (3, 3), activation='tanh', padding='same')) model.add(UpSampling2D((2, 2))) # Finish model model.compile(optimizer='rmsprop', loss='mse') # Image transformer datagen = ImageDataGenerator( shear_range=0.2, zoom_range=0.2, rotation_range=20, horizontal_flip=True) # Generate training data batch_size = 50def image_a_b_gen(batch_size): for batch in datagen.flow(Xtrain, batch_size=batch_size): lab_batch = rgb2lab(batch) X_batch = lab_batch[:,:,:,0] Y_batch = lab_batch[:,:,:,1:] / 128 yield (X_batch.reshape(X_batch.shape+(1,)), Y_batch) # Train model TensorBoard(log_dir='/output') model.fit_generator(image_a_b_gen(batch_size), steps_per_epoch=10000, epochs=1) # Test images Xtest = rgb2lab(1.0/255*X[split:])[:,:,:,0] Xtest = Xtest.reshape(Xtest.shape+(1,)) Ytest = rgb2lab(1.0/255*X[split:])[:,:,:,1:] Ytest = Ytest / 128print model.evaluate(Xtest, Ytest, batch_size=batch_size) # Load black and white images color_me = []for filename in os.listdir('../Test/'): color_me.append(img_to_array(load_img('../Test/'+filename))) color_me = np.array(color_me, dtype=float) color_me = rgb2lab(1.0/255*color_me)[:,:,:,0] color_me = color_me.reshape(color_me.shape+(1,)) # Test model output = model.predict(color_me) output = output * 128# Output colorizationsfor i in range(len(output)): cur = np.zeros((256, 256, 3)) cur[:,:,0] = color_me[i][:,:,0] cur[:,:,1:] = output[i] imsave("result/img_"+str(i)+".png", lab2rgb(cur))
下面是 FloydHub 指令,用来运行 Beta 神经网络:
floyd run --data emilwallner/datasets/colornet/2:data --mode jupyter --tensorboard
技术说明
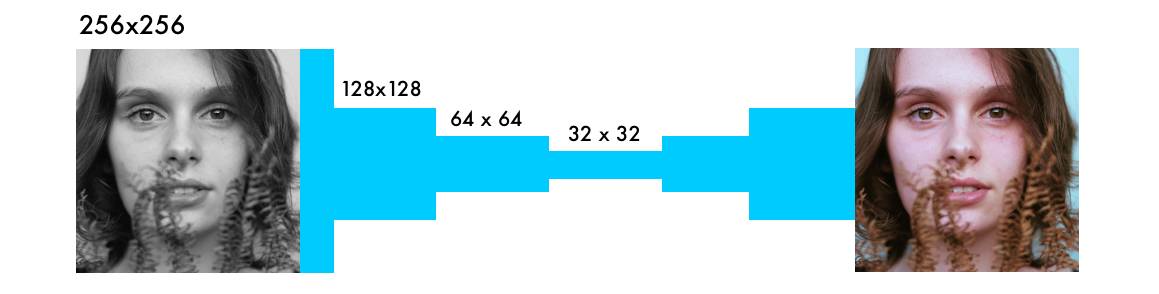
该网络与其他视觉神经网络的主要不同是像素位置的重要性。在上色网络中,图像大小或比例在网络中保持不变。在其他类型的网络中,图像距离最后一层越近就越失真。
分类网络中的最大池化层增加了信息密度,同时也使图像失真。它只对信息估值,而不是图像的布局。在上色网络中,我们使用步幅 2(带 padding)以减少一半的宽度和高度。这也会增加信息密度,但不会使图像失真。
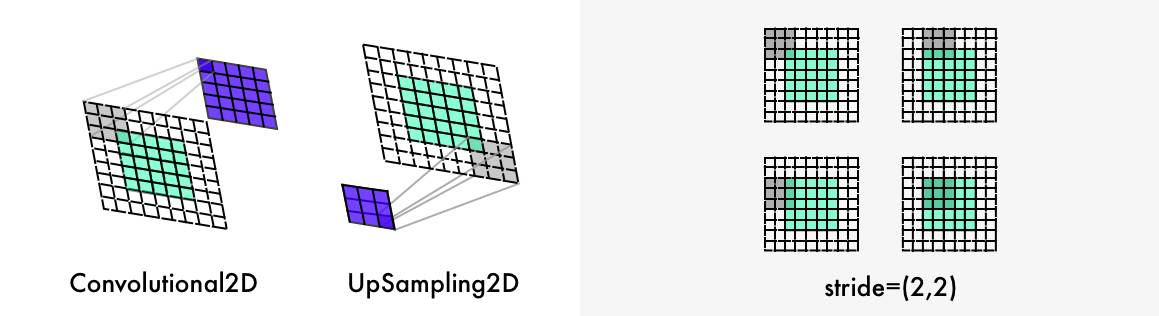
两个进一步的区别是:上采样层和图像比例的保持问题。分类网络只关心最后的分类。因此,整个网络架构将持续降低图像的大小和质量。
上色网络保持图像比率的稳定。这通过添加空白填充(如上图所示)来完成。此外,每个卷积层剪切图像。它通过参数 padding='SAME'来完成。
为了使图像大小翻倍,上色网络使用上采样层(https://keras.io/layers/convolutional/#upsampling2d)。
for filename in os.listdir('/Color_300/Train/'):
X.append(img_to_array(load_img('/Color_300/Test'+filename)))
该循环首先计算目录中所有文件名称,然后通过图像目录进行迭代,将图像转换成像素阵列。最后,将它们连接成为巨型向量(giant vector)。
datagen = ImageDataGenerator(
shear_range=0.2,
zoom_range=0.2,
rotation_range=20,
horizontal_flip=True)
我们可以使用 ImageDataGenerator(https://keras.io/preprocessing/image/)调整图像生成器的设置。这样,每个图像都不一样,从而提高学习率。shear_range 使图像向左或向右倾斜,另一种设置是放大、旋转和水平翻转。
batch_size = 50
def image_a_b_gen(batch_size):
for batch in datagen.flow(Xtrain, batch_size=batch_size):
lab_batch = rgb2lab(batch)
X_batch = lab_batch[:,:,:,0]
Y_batch = lab_batch[:,:,:,1:] / 128
yield (X_batch.reshape(X_batch.shape+(1,)), Y_batch)
我们使用文件夹 Xtrain 中的图像,来生成基于以上设置的图像。然后我们为 X_batch 提取黑色层和白色层,并为两个色彩层(color layer)提取两个颜色值。
model.fit_generator(image_a_b_gen(batch_size), steps_per_epoch=1, epochs=1000)
GPU 越强大,可以拟合的图像就越多。通过这个设置,你可以每次迭代中使用 50-100 张图像。steps_per_epoch 通过将训练的图像数量除以批次大小(batch size)来计算。
例如,如果有 100 张图像,而批次大小为 50,则 steps_per_epoch 为 2。epoch 表示训练全部图像的次数。在一个 Tesla K80 GPU 上用 10000 张图像训练 21 个 epoch 需要大约 11 个小时。
研究经验
在大规模运行之前先进行大量小批次实验。即使实验了二三十次,还是能发现错误。因为运行不代表就一定奏效。神经网络中的 bug 通常比传统编程错误更加细微。
更多样的数据集使图像更加呈褐色。如果你的图像很相似,那么无需过于复杂的架构,你就可以得到不错的结果。缺点是网络的泛化效果不好。
形状、形状、形状。每个图像的大小必须确定且与网络比例相符。一开始,我用的是一个大小 300 的图像。把这个图像分割了三次,得到 150、75 和 35.5 的图像。结果是丢了一半的像素!这导致很多不好的结果,直到我意识到最好使用 2 的幂次方:2、8、16、32、64、256 等。
创建数据集:a)停用.DS_Store 文件。b)有创造性。我最后使用了 Chrome console 脚本和扩展程序 ImageSpark 来下载文件。c)复制抓取的原始文件,使你的清理脚本结构化。
完整版本
我们最终版的上色神经网络有四个组成部分。我们将之前的网络分割成编码器和解码器。在二者中间,使用一个融合层。如果你对分类网络不是很了解,推荐学习该教程:http://cs231n.github.io/classification/。
与编码器并行,输入图像还在最强大的分类器之一 Inception ResNet v2 中运行。这是一个在 120 万张图像上训练的神经网络。我们提取分类层,然后将它与编码器的输出融合起来。
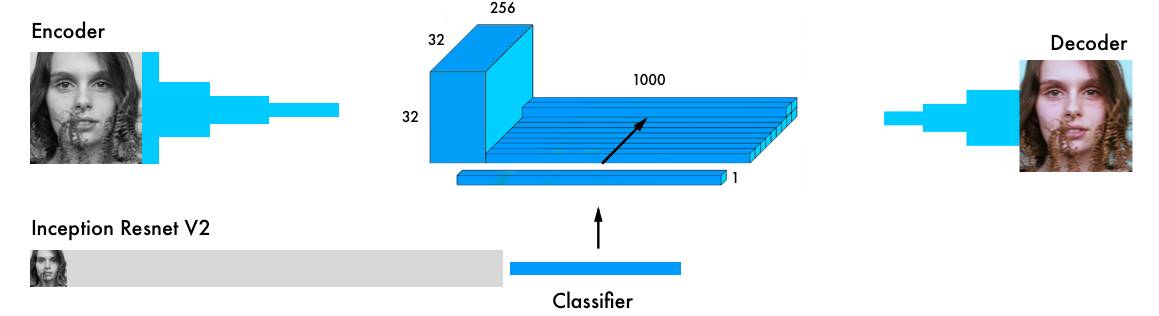
原始论文详细可视化:https://github.com/baldassarreFe/deep-koalarization。
通过从分类器到上色网络的迁移学习,该网络可以了解图像中有什么。这样就可以使该网络通过上色机制匹配目标表示(object representation)。
这里是部分验证图像,仅使用 20 张图像用于网络训练。

大部分图像的输出结果效果不好。但是我在一个较大的验证集(包含 2500 个图像)上找到了一些不错的图像。在更多图像上训练模型可以给出更一致的结果,但是大多数图像经过处理后呈褐色。我使用多个图像(包括验证图像)进行了一些实验,全部实验列表:https://www.floydhub.com/emilwallner/projects/color。
这里是之前研究中最常见的架构:
向图像中手动添加色点来指导神经网络(http://www.cs.huji.ac.il/~yweiss/Colorization/)
找出匹配图像,进行色彩迁移(https://dl.acm.org/citation.cfm?id=2393402、https://arxiv.org/abs/1505.05192)
残差编码器和融合分类层(http://tinyclouds.org/colorize/)
融合分类网络中的超柱(https://arxiv.org/pdf/1603.08511.pdf、https://arxiv.org/pdf/1603.06668.pdf)
融合编码器和解码器之间的最终分类(http://hi.cs.waseda.ac.jp/~iizuka/projects/colorization/data/colorization_sig2016.pdf、https://github.com/baldassarreFe/deep-koalarization/blob/master/report.pdf)
常见色彩空间:Lab、YUV、HSV 和 LUV
常见损失函数:均方差、分类、加权分类
我选择了「融合层」架构(上述列表的第五个)。
因为融合层的输出结果最好,而且在 Keras 中理解和复现都更加容易。尽管它不是最强大的上色网络,但很适合初学者,而且最适合理解上色问题的动态。
我使用 Federico Baldassarre 等人论文中设计的神经网络(https://github.com/baldassarreFe/deep-koalarization/blob/master/report.pdf),在 Keras 中进行了自己的操作。
技术说明
我们想级联或融合多个模型,Keras 的功能性 API 非常合适。(API 地址:https://keras.io/getting-started/functional-api-guide/)

首先,我们下载 Inception ResNet v2 神经网络,加载权重。由于我们将并行使用这两个模型(Inception ResNet v2 和编码器),我们需要明确要使用的模型。这两个模型可以使用带 TensorFlow 后端的 Keras 实现:
inception = InceptionResNetV2(weights=None, include_top=True)
inception.load_weights('/data/inception_resnet_v2_weights_tf_dim_ordering_tf_kernels.h5')
inception.graph = tf.get_default_graph()
我们使用图像微调来创建批次,然后将它们转换成黑白图像,在 Inception ResNet 模型中运行。
grayscaled_rgb = gray2rgb(rgb2gray(batch))
embed = create_inception_embedding(grayscaled_rgb)
首先,我们必须调整图像的大小,使之适应 Inception 模型。然后使用预处理器根据模型对像素和颜色值进行格式处理。最后,在 Inception 模型中运行该图像,并提取模型的最后一层。
def create_inception_embedding(grayscaled_rgb):
grayscaled_rgb_resized = []
for i in grayscaled_rgb:
i = resize(i, (299, 299, 3), mode='constant')
grayscaled_rgb_resized.append(i)
grayscaled_rgb_resized = np.array(grayscaled_rgb_resized)
grayscaled_rgb_resized = preprocess_input(grayscaled_rgb_resized)
with inception.graph.as_default():
embed = inception.predict(grayscaled_rgb_resized)
return embed
我们回过头来看一下生成器。每一个批次都生成 20 个图像,格式如下。这在 Tesla K80 GPU 上需要花费大约一个小时。在没有内存问题的情况下,该模型最多可以一次性生成 50 个图像。
yield ([X_batch, create_inception_embedding(grayscaled_rgb)], Y_batch)
这和我们的 colornet 模型的格式相匹配。
model = Model(inputs=[encoder_input, embed_input], outputs=decoder_output)
将 encoder_input 馈送至编码器模型,然后在融合层中把编码器模型的输出和 embed_input 融合起来;融合层的输出作为解码器模型的输入,然后返回最终输出 decoder_output。
fusion_output = RepeatVector(32 * 32)(embed_input)
fusion_output = Reshape(([32, 32, 1000]))(fusion_output)
fusion_output = concatenate([fusion_output, encoder_output], axis=3)
fusion_output = Conv2D(256, (1, 1), activation='relu')(fusion_output)
在融合层中,我们首先将带有 1000 个类别的层级乘 1024 (32 * 32)。这样,我们就使用 Inception 模型的最后一层得到了 1024 个单元。
然后将它们从 2D 重塑为 3D,即将维度更改为 32 x 32x1000 的张量。然后把它们和编码器模型的输出连接起来。我们使用 256 个 1X1 卷积核的卷积网络,馈送到 ReLU 激活函数后作为融合层的最终输出。
下一步
为图像上色是一个非常有趣迷人的问题。它是一个科学问题,也是一个艺术问题。我写这篇文章的目的就是使大家可以了解图像上色,并且继续开发相关技术。以下是一些初学建议:
使用另一个预训练模型实现它
尝试一个不同的数据集
使用更多图像来提高网络的准确率
在 RGB 色彩空间内构建一个放大器。创建一个与上色网络类似的模型,该模型使用高饱和彩色图像作为输入,正确的彩色图像作为输出。
实现加权分类
将该网络应用到视频。不用担心上色,试图使图像之间的转换更加连贯。你还可以对较大的图像进行一些类似的操作。
你还可以使用 FloydHub,用这三个版本的上色神经网络为黑白图像上色。
对于 alpha 版本,只需要将 woman.jpg 文件替换成你自己的同名文件即可(图像大小 400x400)。
对于 beta 版本和完整版本,将你的图像添加至 Test 文件夹,然后运行 FloydHub 命令。如果 Notebook 正在运行的话,你还可以将 Notebook 中的图像直接上传至 Test 文件夹。注意:这些图像必须是 256x256 像素。还有,你可以上传彩色图像作为测试图像,因为系统可以自动将它们转换成黑白图像。
代码
注意:使用下列代码时我从 Keras 序列模型转向了它们的功能性 API。(文档:https://keras.io/getting-started/functional-api-guide/)
# Get images X = []for filename in os.listdir('/data/images/Train/'): X.append(img_to_array(load_img('/data/images/Train/'+filename))) X = np.array(X, dtype=float) Xtrain = 1.0/255*X #Load weights inception = InceptionResNetV2(weights=None, include_top=True) inception.load_weights('/data/inception_resnet_v2_weights_tf_dim_ordering_tf_kernels.h5') inception.graph = tf.get_default_graph() embed_input = Input(shape=(1000,)) #Encoder encoder_input = Input(shape=(256, 256, 1,)) encoder_output = Conv2D(64, (3,3), activation='relu', padding='same', strides=2)(encoder_input) encoder_output = Conv2D(128, (3,3), activation='relu', padding='same')(encoder_output) encoder_output = Conv2D(128, (3,3), activation='relu', padding='same', strides=2)(encoder_output) encoder_output = Conv2D(256, (3,3), activation='relu', padding='same')(encoder_output) encoder_output = Conv2D(256, (3,3), activation='relu', padding='same', strides=2)(encoder_output) encoder_output = Conv2D(512, (3,3), activation='relu', padding='same')(encoder_output) encoder_output = Conv2D(512, (3,3), activation='relu', padding='same')(encoder_output) encoder_output = Conv2D(256, (3,3), activation='relu', padding='same')(encoder_output) #Fusion fusion_output = RepeatVector(32 * 32)(embed_input) fusion_output = Reshape(([32, 32, 1000]))(fusion_output) fusion_output = concatenate([encoder_output, fusion_output], axis=3) fusion_output = Conv2D(256, (1, 1), activation='relu', padding='same')(fusion_output) #Decoder decoder_output = Conv2D(128, (3,3), activation='relu', padding='same')(fusion_output) decoder_output = UpSampling2D((2, 2))(decoder_output) decoder_output = Conv2D(64, (3,3), activation='relu', padding='same')(decoder_output) decoder_output = UpSampling2D((2, 2))(decoder_output) decoder_output = Conv2D(32, (3,3), activation='relu', padding='same')(decoder_output) decoder_output = Conv2D(16, (3,3), activation='relu', padding='same')(decoder_output) decoder_output = Conv2D(2, (3, 3), activation='tanh', padding='same')(decoder_output) decoder_output = UpSampling2D((2, 2))(decoder_output) model = Model(inputs=[encoder_input, embed_input], outputs=decoder_output) #Create embedding def create_inception_embedding(grayscaled_rgb): grayscaled_rgb_resized = [] for i in grayscaled_rgb: i = resize(i, (299, 299, 3), mode='constant') grayscaled_rgb_resized.append(i) grayscaled_rgb_resized = np.array(grayscaled_rgb_resized) grayscaled_rgb_resized = preprocess_input(grayscaled_rgb_resized) with inception.graph.as_default(): embed = inception.predict(grayscaled_rgb_resized) return embed # Image transformer datagen = ImageDataGenerator( shear_range=0.4, zoom_range=0.4, rotation_range=40, horizontal_flip=True) #Generate training data batch_size = 20def image_a_b_gen(batch_size): for batch in datagen.flow(Xtrain, batch_size=batch_size): grayscaled_rgb = gray2rgb(rgb2gray(batch)) embed = create_inception_embedding(grayscaled_rgb) lab_batch = rgb2lab(batch) X_batch = lab_batch[:,:,:,0] X_batch = X_batch.reshape(X_batch.shape+(1,)) Y_batch = lab_batch[:,:,:,1:] / 128 yield ([X_batch, create_inception_embedding(grayscaled_rgb)], Y_batch) #Train model tensorboard = TensorBoard(log_dir="/output") model.compile(optimizer='adam', loss='mse') model.fit_generator(image_a_b_gen(batch_size), callbacks=[tensorboard], epochs=1000, steps_per_epoch=20) #Make a prediction on the unseen images color_me = []for filename in os.listdir('../Test/'): color_me.append(img_to_array(load_img('../Test/'+filename))) color_me = np.array(color_me, dtype=float) color_me = 1.0/255*color_me color_me = gray2rgb(rgb2gray(color_me)) color_me_embed = create_inception_embedding(color_me) color_me = rgb2lab(color_me)[:,:,:,0] color_me = color_me.reshape(color_me.shape+(1,)) # Test model output = model.predict([color_me, color_me_embed]) output = output * 128# Output colorizationsfor i in range(len(output)): cur = np.zeros((256, 256, 3)) cur[:,:,0] = color_me[i][:,:,0] cur[:,:,1:] = output[i] imsave("result/img_"+str(i)+".png", lab2rgb(cur))
以下是运行完整版神经网络的 FloydHub 命令:
floyd run --data emilwallner/datasets/colornet/2:data --mode jupyter --tensorboard
本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告&商务合作:bd@jiqizhixin.com



