Uber成果CoordConv被diss,深度学习上演“皇帝的新衣”
前几天,论智曾报道了这么一个项目:Uber提出CoordConv:解决了普通CNN的坐标变换问题。文中讲到,Uber AI的工程师们发现卷积神经网络无法将空间表示转换成笛卡尔空间中的坐标和独热像素空间中的坐标。更重要的是,他们还对这一限制提出了解决方法,即CoordConv。
论文一经推出,就收获了不少点赞,连我们的编译版本阅读量也很可观,小编甚是欣慰。可是没过几天,一位名叫Filip Piekniewski的朋友在他的个人博客上写道:“这种微不足道的进步也值得这样赞美……”这位计算机视觉工程师用52行代码就做出了和论文同样的结果,让我们看看他是如何剖析CoordConv的吧。以下是论智的编译。

简介
关于深度学习的论文,我读的很多,经常一个星期读好几篇的样子,所以目前为止可能读了几千份论文。机器学习或深度学习有一个基本的问题,即这些论文总是处在科学和工程之间的“无人之境”上,我将它成为“学术工程(academic engineering)”,具体解释如下:
我个人认为,一篇科学论文应该传递一种观点,使其有能力解释某种东西。例如一篇证明一个数学定理的论文或者表示某些物理现象的模型。另外,科学论文应该以实验为基础,实验的结果能告诉我们有关显示的基本情况。虽然如此,科学论文的中心仍是对自然事实的普遍性和观察进行总结。
一篇工程类论文应该展示解决某一特殊问题的方法。在不同的应用上,问题的类型也不相同,有时可能很无聊,但是对某些人是很有价值的。对一篇工程论文来说,重点和科学论文有所不同:解决方案的普遍性也许不是最重要的,重要的是这一方案能够实际运用。也就是说,给定可用条件,该解决方案比之前的方法更便宜、更高效。所以说工程类论文的重点是应用,其余的部分都是用于支撑该方法能解决问题的观点。
而机器学习介于两者之间,这一领域既有科学类论文(例如介绍反向传播的那篇),也有明显的工程类论文,其中描述了很实用的解决方法。但是大部分论文都更偏向工程一点,为了显示优越性,其中取消了特别的技巧,经过一些不重要的数据测试之后就宣布这种方法的成功。
除此之外还有第四种论文,它们的确包含某种观点,这种想法可能是有用的,但却是不值一提的。为了掩盖这令人尴尬的事实,作者们美名其曰这是“学术工程”,从而让论文看上去“高大上”了许多。
好巧不巧,Uber最近就发表了这样一篇论文——An Intriguing Failing of Convolutional Neural Networks and CoordConv Solution,下面我就要好好剖(shou)析(si)这一成果。
解剖开始
让我们直接进入正题,论文附带的视频可以带你在9分钟内了解大致讲了什么:
现在我们知道,这篇论文的中心是,研究者发现卷积神经网络在需要坐标的任务中表现得不是很好,详细地说,即输出标签或多或少的是输入元素坐标的正函数,并不表示输入的其他属性。
卷积网络确实在此类问题上表现的不好,因为特征映射的结构,从福岛邦彦提出新认知机(Neocognitron)后,在设计时就忽略了这些坐标的位置。所以Uber AI的作者提出了一种解决方法:在卷积层中加入坐标,将其当做额外的输入映射。
听起来这个方法很好,但是作者实际上提出的方法,也是很多从业者经常会想当然的方法——他们添加的特征更适合对想要的输出进行解码。任何从事计算机视觉的专家都不会对加入特征感到陌生,虽然这只是深度学习圈子里一个小话题。现如今,深度学习中的研究者们已然脱离了实际应用,声称我们应该只使用学到的特征,因为“这种方法更好”。这么说深度学习圈里的人们也开始认同特征工程了啊……
训练
不管怎样,这篇论文加入了一个特征,明确表示出了坐标的值。接着作者在一个名为“Not-so-Clevr”的数据集上进行测试(这个数据集的名字很皮),那么他们的试验是不是真的聪明呢?让我们进一步分析。
其中一个任务是基于坐标生成独热图像,或者从独热图像中生成坐标。他们表示在卷积网络中加入坐标的确可以大大提高性能。
等等,冷静一下,如果他们不直接上手TensorFlow,而是直接创建一个神经网络来解决独热编码到坐标的变换问题的话……就不用任何训练啊。对于这个问题我会进行三种操作:卷积、非线性激励和求和。好在这些都是卷积神经网络的基础组成部分:
import scipy.signal as sp
import numpy as np
# Fix some image dimensions
I_width = 100
I_height = 70
# Generate input image
A=np.zeros((I_height,I_width))
# Generate random test position
pos_x = np.random.randint(0, I_width-1)
pos_y = np.random.randint(0, I_height-1)
# Put a pixel in a random test position
A[pos_y, pos_x]=1
# Create what will be the coordinate features
X=np.zeros_like(A)
Y=np.zeros_like(A)
# Fill the X-coordinate value
for x in range(I_width):
X[:,x] = x
# Fill the Y-coordinate value
for y in range(I_height):
Y[y,:] = y
# Define the convolutional operators
op1 = np.array([[0, 0, 0],
[0, -1, 0],
[0, 0, 0]])
opx = np.array([[0, 0, 0],
[0, I_width, 0],
[0, 0, 0]])
opy = np.array([[0, 0, 0],
[0, I_height, 0],
[0, 0, 0]])
# Convolve to get the first feature map DY
CA0 = sp.convolve2d(A, opy, mode='same')
CY0 = sp.convolve2d(Y, op1, mode='same')
DY=CA0+CY0
# Convolve to get the second feature map DX
CA1 = sp.convolve2d(A, opx, mode='same')
CX0 = sp.convolve2d(X, op1, mode='same')
DX=CA1+CX0
# Apply half rectifying nonlinearity
DX[np.where(DX<0)]=0
DY[np.where(DY<0)]=0
# Subtract from a constant (extra layer with a bias unit)
result_y=I_height-DY.sum()
result_x=I_width-DX.sum()
# Check the result
assert(pos_x == int(result_x))
assert(pos_y == int(result_y))
print result_x
print result_y
一个热点位图进行坐标转换、一个卷积层、一个非线性激励、一个求和以及最后从一个减法,无需学习,50多行Python代码,搞定。
接下来让我们试试在GAN上进行合成生成任务,其中一个还有坐标特征,另一个没有。在论文的附录中有这么一个表格:
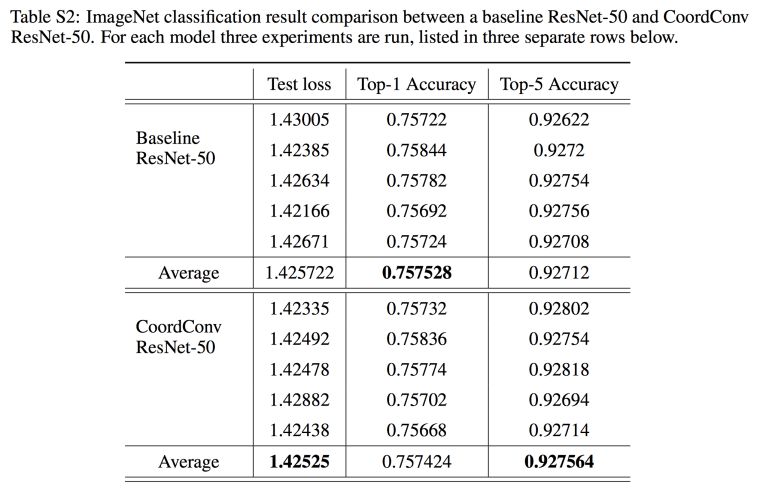
他们尝试在ImageNet上将坐标特征添加到ResNet-50网络的第一个图层上。我猜作者希望在这里看到较大的提升,因为ImageNet的类别读数并不是位置的函数(如果这里存在偏差,那么训练时的数据增强过程就应该完全清除)。
所以他们用100个GPU进行了测试(100个啊!),但是直到小数点后第三位,结果才有些许提升。100个GPU就提高了这么一点儿,要不然让谷歌或者Facebook的人用10000个GPU试试,说不定能在小数点后第二位就看到变化了呢(逃)。
总结
这篇论文的确吸引人,它在当下“一切向计算力看齐”的大背景下还能揭露深度学习的缺陷实属不易。但为什么是Uber提出这个问题?如果是一些学生做出这样的成绩也就罢了,但是Uber AI不是搞自动驾驶的吗?
更有意思的是这篇论文在推特上受到很多人,甚至深度学习专家的表扬。他们太过于看重GPU的表现力了,殊不知这明明只需要几行Python就能解决……
原文地址:blog.piekniewski.info/2018/07/14/autopsy-dl-paper/





