演讲 | 刘铁岩:对偶学习推动人工智能的新浪潮


12 月 17 日,中国人工智能学会、中国工程院战略咨询中心主办,今日头条、IEEE《计算科学评论》协办的2016机器智能前沿论坛暨2016 BYTE CUP 国际机器学习竞赛颁奖仪式在中国工程院举办,论坛邀请到今日头条、微软、IBM 等业界科学家以及清华大学、北京大学、Santa Fe 研究所、Georgia Institute of Technology(佐治亚理工)等国内外知名院校学者共同探讨了机器学习的研究现状、前沿创新及应用发展等问题。微软亚洲研究院首席研究员刘铁岩博士受邀发表演讲。本文由机器之心授权转载。
对偶学习推动人工智能的新浪潮
刘铁岩
谢谢大家,感谢组委会的邀请,让我有这个机会与大家分享我们的研究工作。我刚才坐在台下聆听了孙茂松老师和 David 的报告,都获益匪浅。首先,老师非常全面的回顾了机器翻译的历史,又有高屋建瓴的讨论,让我们从中学到了很多的东西。其次,很荣幸我的报告排在 David 之后,做优化和机器学习的同事们应该都非常熟悉 David 的 No Free Lunch Theory,尤其在今天全世界都希望用神经网络这「一招鲜」来解决所有问题的时候,更应该仔细琢磨一下这个定理,对大家会有很大的启示。
今天我分享的主题是对偶学习。在对这个主题进行深入讨论之前,我想同大家一起回顾一下最近这段时间人工智能领域的一些飞速发展。我举几个例子,首先是语音识别。

可能很多同学都看到过这则新闻,微软研究院在语音识别方面取得了重大突破,第一次机器学习算法在日常对话场景下取得了和人一样好的语音识别能力,词错误率降低至 5.9%。
第二个例子是有关图像识别和物体分割,在这方面微软研究院同样也有世界领先的研究成果。

2015 年,我们研究院发明的 ResNet 算法在 ImageNet 比赛中力拔头筹,超过了人类的识别水平。人眼辨识图像的错误率大概为 5.1%,而 ResNet 的错误率低至 3.5%。今年,在 COCO 物体分割竞赛中,我们研究院同样获得了第一名,和第二名拉开了很大的差距。物体分割比图像分类更难,不但要识别出图片里有什么,还要能够把它的轮廓勾勒出来。
第三个例子是机器翻译,最近相关产业界的发展突飞猛进。这一方向微软同样有着世界领先的技术。
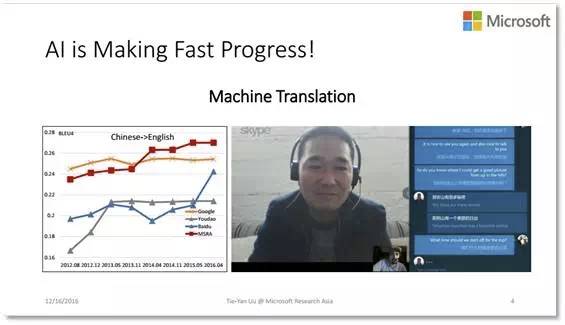
比如在微软的 Skype Translator 软件里,对话双方可以用不同语言进行交流,系统实现实时语音翻译。如果今天会场上大家使用 Skype Translator 的话,可能就不需要聘请同声传译公司了。
第四个例子,最近这段时间人工智能之所以吸引了那么多的眼球,一个重要原因就是它在一些需要极高智商的比赛中取得了关键性胜利。比如 AlphaGo 4:1 战胜了围棋世界冠军李世石。在这场人机大战之后,DeepMind 的科学家没有停止他们的训练,据说今天的 AlphaGo 已经达到了人类专业围棋十三段的水平,十三段对决九段那简直就是秒杀。
人工智能的这些成果非常令人振奋,那么这些成果背后又是怎样的技术呢?这就不得不提到深度学习和增强学习。
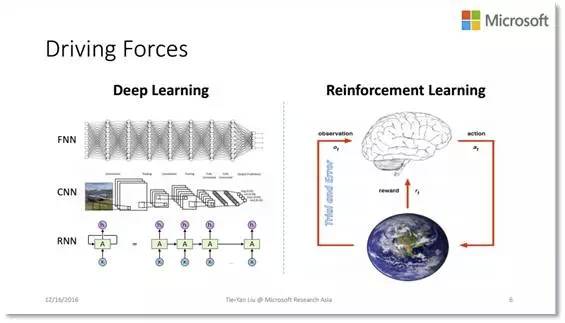
深度学习使用的是非常复杂,层次很深,容量很大的非线性模型,如深层神经网络,这样的模型可以很好的拟合大量的训练数据,从而在很多识别任务中表现突出。增强学习是一种持续学习技术,它不断地和环境进行交互,根据环境的反馈更新模型。这两种技术还可以相互结合,我们称之为深度增强学习。AlphaGo 背后的核心技术就是深度增强学习。那么,到底深度学习和增强学习是不是真的已经非常完美,可以解决我们面临的所有人工智能问题呢?
其实答案是否定的。仔细分析一下,就会发现这两项技术都存在本质的弱点。首先,目前深度学习的成功离不开大量的有标签训练数据。但是获得海量有标签数据的代价是非常高的,在某些特定的邻域甚至是不可能完成的任务。比如医疗领域的疑难杂症,本身样本就非常少,有钱也无法取得大量的有标签数据。正所谓成也萧何,败也萧何,大数据推动了深度学习的成功,但也成为了深度学习进一步发展的瓶颈。其次,增强学习虽然不需要利用传统意义上的有标签数据,但是它的学习效率并不高,需要跟环境进行大量交互从而获得反馈用以更新模型。然而,有时和环境的频繁交互并不现实。比如,在我们学开车的时候,依赖于频繁地和环境(周围的路况,其他的车辆)进行交互是很危险的,可能还没学会开车就已经发生交通事故了。这就解释了为什么增强学习取得成功的领域很多都是模拟环境,比如说打电子游戏、下围棋等等,它们规则明确,可以无限次重复。但当把增强学习应用到一些实际场景里,需要和实际用户进行交互,还可能带有无法挽回的风险,是不是还能取得同样的效果呢?目前还没有被证实。

了解了深度学习和增强学习的弱点以后,我们不禁要问:有没有一种新的学习范式可以克服他们的弱点?能否可以不依赖于那么多有标签的数据,能否不需要跟真实环境做那么多次交互,就可以学到有效的模型?为了回答这个问题,我们首先来对现有的人工智能任务做一个仔细的分析。

通过分析,我们发现了一个非常重要的现象:现实中,有意义、有实用价值的人工智能任务,往往是成对出现的。比如在做机器翻译的时候,我们关心从英语翻译到汉语,我们同样也关心从汉语翻译回英语。再比如,在语音领域,我们既关心语音识别的问题,也关心语音合成的问题(TTS)。图像领域,我们既关心图像识别,也关心图像生成。类似这样的对偶任务还有很多,比如在对话引擎、搜索引擎等场景中都有对偶任务。这种现象给了我们什么启示呢?
第一点,由于存在特殊的对偶结构,两个任务可以互相提供反馈信息,而这些反馈信息可以用来训练深度学习模型。也就是说,即便没有人为标注的数据,有了对偶结构,我们也可以做深度学习了。第二,这两个对偶任务,可以互相充当对方的环境,这样我们就不必跟真实的环境做交互,这两个对偶任务之间的交互就可以产生有效的反馈信号了。总而言之,如果我们能充分地利用对偶结构,就有望解决刚才提到的深度学习和增强学习的瓶颈——训练数据从哪里来、和环境的交互怎么持续进行下去。
基于以上的思考,我们提出了一个新的学习范式,叫做对偶学习。它的思路非常简单。我们假设学习过程中有两个智能体,其中一个智能体从事的是原任务,就是从 X 到 Y 的学习任务;而另外一个智能体从事的是对偶任务,也就是从 Y 到 X 的学习任务。假如我们把 X 用第一个智能体的模型 F 映射成 Y,再利用第二个智能体的模型 G 把它反映射成 X’。通过比较 X 和 X'我们其实就可以获得非常有用的反馈信号。
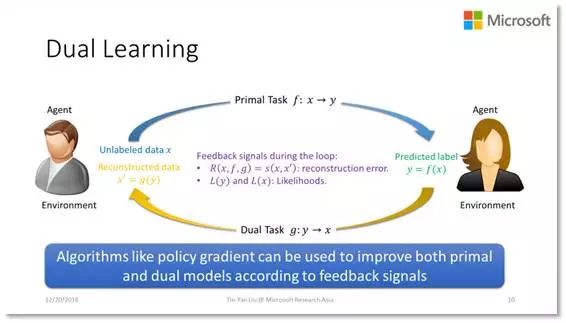
其实这个做法在刚才孙茂松老师的演讲中已经提到过,有人曾经用这种翻过去再翻回来的方式判断机器翻译模型的好坏。如果 X 和 X'的差异很大,就说明这个翻译系统不靠谱,说明模型 F 和 G 至少有一个不好;如果 X 和 X'很接近,就给了我们一个利好的消息,就是这两个模型都不错。除了比较 X 和 X'的差异,其实还有很多其他的反馈信息可以被利用。下面我们以机器翻译为例,做个详细的说明。
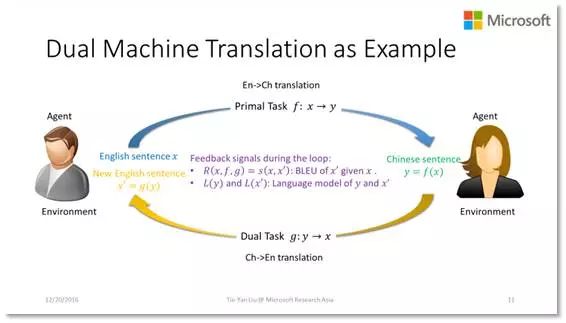
假设我们有一个英文的句子 X,通过翻译模型 F 的作用,得到一个中文句子 Y。那么 Y 作为一个中文句子是不是符合语法,是不是顺畅,X 到 Y 之间的关系是否和英汉词典一致等等,都可以作为反馈信息。同样,当我们用模型 G 把 Y 再变成英文句子 X'以后,也可以去衡量 X'是不是符合语法,是否顺畅、X'与 Y 的关系是否与英汉词典一致,以及 X'和 X 是否相似等等,都可以作为反馈信息。利用这些反馈信息,我们可以使用包括 Policy Gradient 在内的方法,来一轮一轮地更新我们的模型,直到最终得到两个满意的模型。
上面的这个过程可以无限循环下去,每次随机地抽选一个单语语句,做对偶学习,更新模型,然后再抽选下一个单语语句,进行对偶学习。那么这个过程会不会收敛呢?其答案是肯定的,以机器翻译为例,我们可以证明,只要机器翻译模型 F 和 G 的解码部分都使用的是随机算法,比如 beam search,这个对偶学习过程就一定是收敛的,也就是说你最终会学到两个稳定的模型 F 和 G。
那么接下来,我们就来看看这样的稳定模型是否有效。我们对比的算法是一个非常经典的神经机器翻译方法,而且用的是他们自己开源的代码。为了训练这个对比算法,我们使用了全部的双语标注数据。而我们自己提出的对偶学习算法并不需要双语标注数据,用单语数据就可以进行学习和迭代了。不过万事开头难,我们还是要给这个学习过程一个初始化。在初始化过程中,我们使用了 10% 的双语语料训练了一个相对比较弱的模型,然后用对偶学习的迭代过程不断提高它。也就是说,在初始化完成之后,我们就不再使用任何双语的标注语料了,而是靠两个对偶任务互相提供反馈信息进行模型训练。好,那我们来看看实验结果如何。

这两张图展示了法英和英法翻译的实验结果。以第一张图为例,最左边这根柱子对应的是用 10% 双语语料训练的初始模型;最右边这根柱子对应的是用 100% 双语语料训练的翻译模型。可以看出,初始模型确实比较弱。当我们使用对偶学习的方法,虽然不再利用任何有标注的双语数据,我们仍可以很快的接近甚至超过用百分之百的双语语料训练出来的模型。这个结果非常令人振奋。不仅如此,我们的实验发现,对偶学习更不容易饱和,因为无标签的单语数据非常丰富、非常多样化,因此通过不断调节单语数据源和调整反馈信息,可以持续提高模型的有效性。相反,使用双语语料比较容易饱和,过几遍数据以后,当信息被挖掘得足够充分,想要再提升模型精度就变得非常困难了。
如上这种振奋人心的结果是否只局限在机器翻译领域呢?其他领域是否也可以使用类似的方法得到提升呢?答案是肯定的,前面我提到的很多人工智能的任务都具有对偶结构,因此都可以用对偶学习来解决。
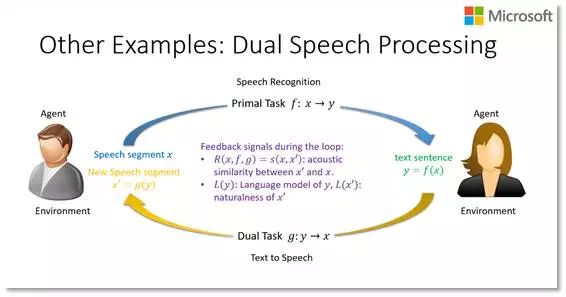
这张 PPT 展示了在语音识别和语音合成方面如何定义反馈信号,从而进行对偶学习。
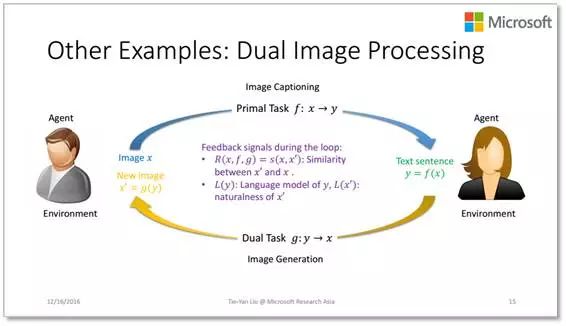
同样,这张 PPT 展示了在图像识别和图像生成方面如何定义反馈信号,从而进行对偶学习。
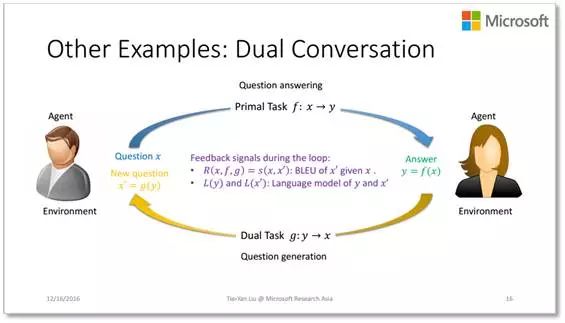
而这张 PPT 则展示了在对话引擎方面如何定义反馈信号,从而进行对偶学习。
说到这里,可能很多人会有疑问,虽然我们说对偶学习应用很宽泛,但是我们举的例子都有一个共同特点,就是真实的物理世界里确实存在两个对偶的任务。那么,如果我们要解决的问题并不存在一个天然的对偶任务怎么办?其实这个也没关系,即使没有物理上的对偶性,也可以通过虚拟的对偶性来完成对偶学习。我举两个例子。第一个是在深度神经网络领域常用的 Auto Encoder,仔细分析一下,它其实是对偶学习的一个特例。
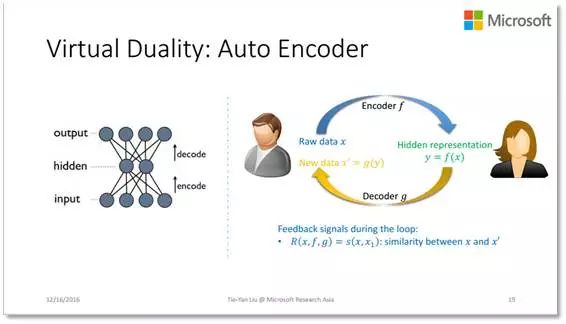
Auto Encoder 原本的任务是要学习从输入层到隐层的一个映射(即编码),为了有效地学习这种映射,我们人为添加了一个虚拟任务:就是从隐层到输入层的逆映射(即解码,请注意图中的输出跟输入是一样的数据),这样就形成了机器学习的闭环。如果用对偶学习的语言描述一下,就是这张图:通过人为增加解码回路,使虚拟的对偶性得以成立,从而实现对偶学习。不过需要指出的是,Auto Encoder 和对偶学习有一些小差别,Auto Encoder 只关心单边任务的模型(也就是编码器),而在标准的对偶学习中,我们同时关心两个模型,想把它们都学好。
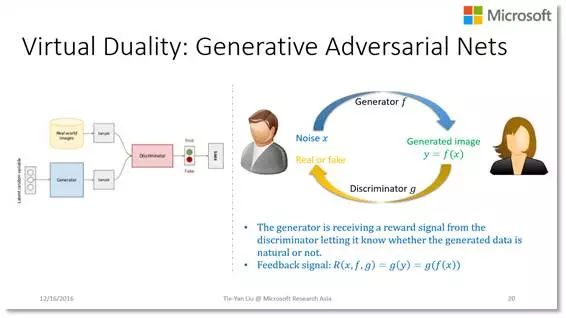
另一个例子是最近这两年特别火的——Generative Adversarial Nets(GAN)。它的目标是学习一个图像生成器,为此通过一个鉴别器不断给生成器提供反馈信息(也就是判别生成器生成的东西是真是假)。这样的博弈过程可以获得一个非常有效的图像生成器,用它可以自动制造训练样本来进行深度学习。很显然,GAN 也可以用对偶学习的语言进行描述,并且它也只是对偶学习的一个特例:它只关心单边生成器的有效性,而标准的对偶学习会同时关心生成器和鉴别器的有效性。
到此为止,无论是天然的对偶学习,还是虚拟的对偶学习,都是用来解决无监督学习问题的。那么,如果实际中我们的训练数据已经非常多了,对偶学习的思想还有用吗?我们的答案是:有用,而且非常有用。
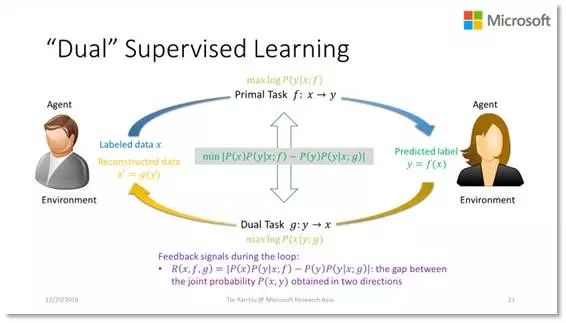
让我们来看一下监督学习的例子。我们有一个样本 X,原任务是要预测它的标签 Y。为此,我们可以使用已有的很多监督学习技术加以实现。但如果我们再给它人为增加一条对偶回路会怎样呢?假设存在一个对偶任务,是从标签 Y 到 X 的预测。那么原任务和对偶任务其实存在着非常内在的联系。利用全概率公式和贝叶斯公式我们可以很容易知道,这两个任务背后的条件概率是互相约束的,利用这一点可以构造一个非常强的正则项来提高模型的学习效率。我们在机器翻译上的实验表明,加入这个对偶正则项,翻译模型的 BLEU score 有大幅度的提升。
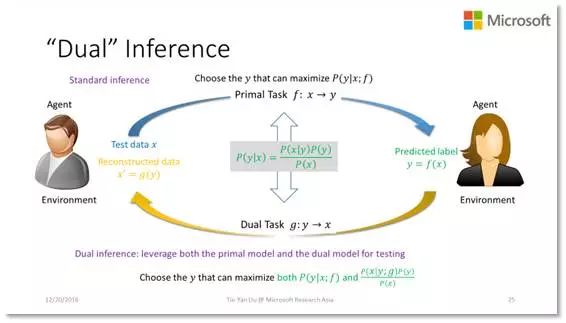
同样的道理,对偶学习的思想甚至可以提高 inference 的性能。假设我们的模型已经训练好了,原任务是要用它来做预测。传统的做法是,给定一个样本 X,基于已有模型,寻找能够使其条件概率 P(Y|X) 最大化的 Y 作为 inference 的结果。如果我们运用对偶学习的思想,就会发现问题还可以反过来看。从对偶任务的模型出发,利用贝叶斯公式,同样也可以导出条件概率 P(Y|X) 来。按理说这两个条件概率应该是一致的,但是因为原任务和对偶任务是独立进行的,实际中它们可能并不完全一致,那么如果综合考虑这两个条件概率,我们的置信度会得到提升。相应地,inference 的结果也会得到明显的提升。
到此为止我们介绍了对偶学习在无监督学习上的应用、在没有天然对偶结构时如何使用虚拟回路实现对偶学习、以及如何把对偶学习的思想延展到有监督学习和 inference 之中。
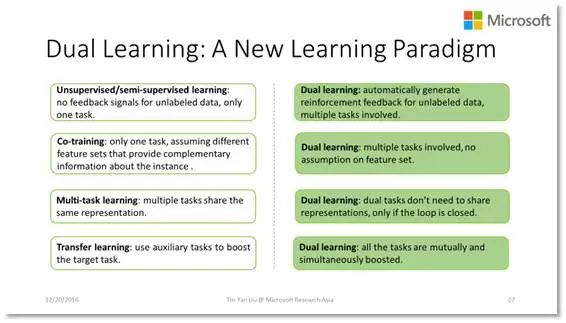
事实上,对偶学习是一个新的学习范式,而不单是一个技巧。它和我们熟知的很多学习范式,如无监督学习、半监督学习、co-training、多任务学习、迁移学习都有联系,又有显著不同。它提供了一个看待这个世界的不同视角,对很多难题提供了新的解题思路。我们非常有信心对偶学习在更多的领域将会取得成功。我们组的同事们正在这个方向上积极探索,也希望在座的各位能够加入我们,一起去推动对偶学习的发展,掀起人工智能的新浪潮,谢谢大家!

刘铁岩,微软亚洲研究院首席研究员,美国卡内基-梅隆大学(CMU)客座教授、英国诺丁汉大学荣誉教授、中国科技大学、中山大学、南开大学兼职博导。刘博士的研究兴趣包括:人工智能、机器学习、信息检索、数据挖掘等。他的先锋性工作促进了机器学习与信息检索之间的融合,被国际学术界公认为“排序学习”领域的代表人物,他在该领域的学术论文已被引用近万次,并受斯普林格出版社之邀撰写了该领域的首部学术专著(并成为斯普林格计算机领域华人作者的十大畅销书之一)。近年来,刘博士在博弈机器学习、深度学习、分布式机器学习等方面也颇有建树,他的研究工作多次获得最佳论文奖、最高引用论文奖、研究突破奖,并被广泛应用在微软的产品和在线服务中。他曾受邀担任了包括SIGIR、WWW、KDD、NIPS、AAAI在内的顶级国际会议的组委会主席、程序委员会主席、或领域主席;以及包括ACM TOIS、ACM TWEB、Neurocomputing在内的国际期刊的副主编。他是国际电子电气工程师学会(IEEE)院士,美国计算机学会(ACM)杰出会员,中国计算机学会(CCF)高级会员、杰出演讲者、学术工委,中文信息学会信息检索专委会副主任。
你也许还想看:
感谢你关注“微软研究院AI头条”,我们期待你的留言和投稿,共建交流平台。来稿请寄:msraai@microsoft.com。




