滴滴KDD 2019 论文详解:基于深度价值网络的多司机智能派单模型

通过系统的离线模拟实验以及在滴滴平台的在线AB实验证明,这种基于深度强化学习的派单算法相比现有最好的方法能进一步显著提升平台各项效率及用户体验。
作者 | 滴滴 AI Labs
编辑 | Pita
世界数据挖掘领域顶级学术会议KDD2019继续在美国阿拉斯加州安克雷奇市举行。本次KDD大会首次采用双盲评审制,共吸引了全球范围内约1879篇论文投递。其中,Applied Data Science track收到约 700 篇论文投稿,最终45篇被接收为Oral论文,100篇被接收为Poster论文;而Research track 共收到了 1179 篇投稿,最终111篇被接收为Oral论文,63篇被接收为Poster论文。
今年,滴滴共有三篇Oral论文入选KDD2019,研究内容涵盖基于深度学习方法自动化地生成工单摘要、基于深度强化学习与半马尔科夫决策过程进行智能派单及模仿学习和GAN在环境重构的探索。
本文是对滴滴Oral论文《A Deep Value-networkBased Approach for Multi-Driver Order Dispatching》的详细解读。滴滴AI Labs技术团队在KDD2018 Oral 论文《Large‑Scale Order Dispatch in On‑DemandRide‑Hailing Platforms: A Learning and Planning Approach》的基础上,新提出了一种新的基于深度强化学习与半马尔科夫决策过程的智能派单应用,在同时考虑时间与空间的长期优化目标的基础上利用深度神经网络进行更准确有效的价值估计。通过系统的离线模拟实验以及在滴滴平台的在线AB实验证明,这种基于深度强化学习的派单算法相比现有最好的方法能进一步显著提升平台各项效率及用户体验。

研究背景
当下滴滴网约车采用的全局最优的派单模式,是通过搜索1.5-2秒内所有可能的司机乘客匹配,由算法综合考虑接驾距离、道路拥堵情况等因素,自动将订单匹配给最合适的司机接单,让全局乘客接驾时间最短。本文所述的算法也是在这一派单模式基础下的改进。
司机在不同时间地点会有不同的未来收益期望 (“热区”vs”冷区”)。准确地估计这样的收益 (或者价值) 期望对于提升派单效率有重要的意义。下面两个简单的例子可以更形象的说明这一点。
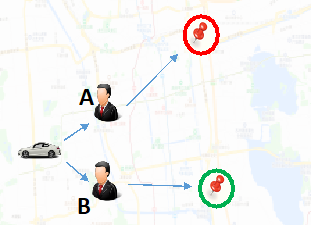
第一个例子是供给受限的情况,这里有一个司机,两个乘客A跟B分别前往”热区”和”冷区”,假设其他影响派单的因素完全一样 (接驾距离、安全合规、合规司机收入倾斜、服务分等)。那么可以认为把乘客A派给司机是更优的选择 (实际情况更为复杂,比如在供需不平衡的情况下引入排队机制),因为司机在完成A订单后可以更好的满足”热区”运力不足的需求,从而在整体上减少司机的空车时间,达到调节供需的作用;
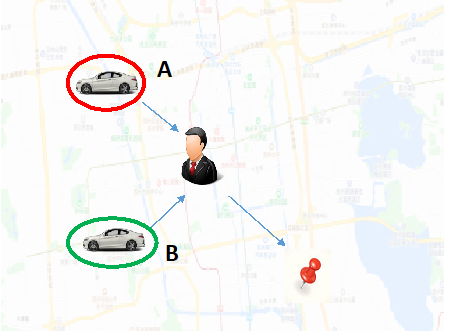
第二个例子是需求受限的情况。假设这里有一个乘客,司机A跟B分别在”冷区”和”热区”,而其他影响派单的因素完全一样,那么在这个情况下,可以认为把订单派给A会是更好的选择,因为B在”热区”期望上能比A更快地接到下一单,这样长期来看总体上最小化了A跟B的空车时间。
深度价值网络的强化学习和匹配规划 (Learning andPlanning)
在上面两个例子中说明,不管是供给端还是需求端受限,我们都可以通过在派单决策中系统的考虑冷”热区”之间关系来提升系统效率。下面我们从数学上对派单问题进行建模并给出冷”热区”在强化学习框架下的定义。
派单可以看成一个系列决策问题,我们将其建模为带有时间延展性的马尔科夫决策过程,也称为Semi-MDP。与标准MDP类似,司机从一个状态 (时间、地点、情景式特征) 出发,通过接单或者空车游走的动作 (option),转移到下一个状态,并获得相应奖励 (对于接单的动作是订单的金额,空车游走或者上下线则为0)。这里与标准MDP最大的不同在于动作带有时间延展性,不同动作时间跨度不同,这一点很重要,会体现在训练使用的Bellman equation中。
在Semi-MDP的框架下我们可以写出强化学习中价值函数的定义,表示司机从一个状态出发,在给定的派单策略下,直到一天结束的期望收益
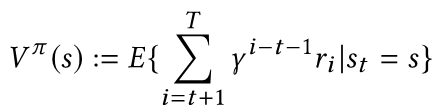
跟标准MDP类似,我们可以写出基于价值函数的一步转移Bellman方程
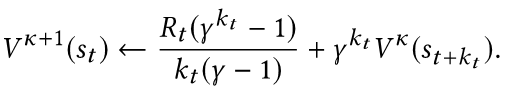
上面的公式表示了司机从状态St经过k个时间步长转移到St+k,并收获奖励R。这里跟标准MDP最大的不同在于等式右边第一项等效即时奖励,不是直接用R,而是对R做了一个跟步长k相关的衰减。在Semi-MDP框架下两个带来同样收益的动作,时间跨度小的动作的等效即时奖励更大。另一角度来看,这可以理解为对广泛应用于实际的reward clipping做了一个平滑 (smoothing) 处理,用连续衰减代替了截断处理 (clipping)。
我们用一个深度神经网络来表示价值函数,为了增加策略估计中递归迭代的稳定性一般需要使用一个慢速更新的目标网络 (target network),或者使用下面要介绍的在训练中加入Lipschitz正则化的方法。
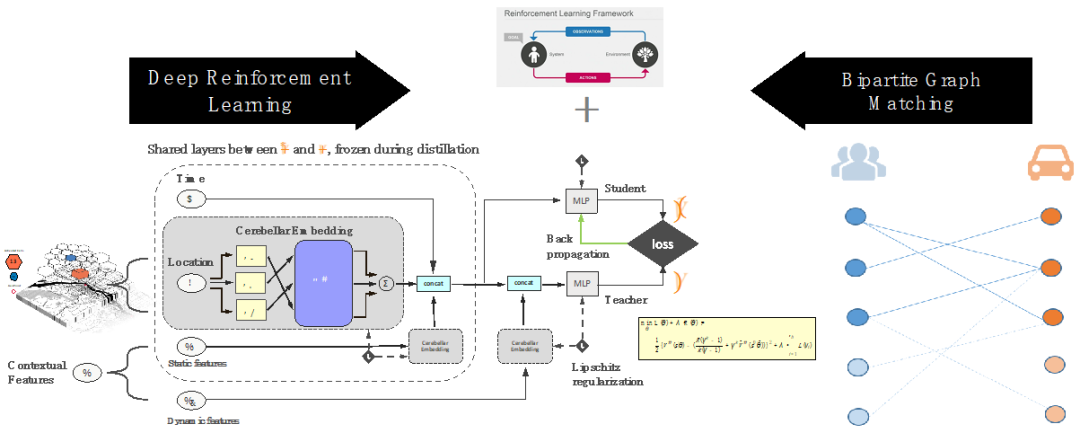
一般的强化学习应用,执行策略只需要针对价值函数应用贪心算法,但在线上派单的环境下我们需要调和多司机与多订单之间的派单限制,所以我们通过解二分图优化问题来进行全局规划。线上每2秒派单一次,每次派单会求解一个组合优化匹配问题,目标函数是在满足派单的限制下使得匹配结果总体边权和最高
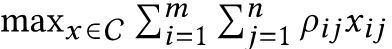
这里我们使用基于价值函数以及时序差分误差 (TD Error) 的方法来计算每个订单与司机的匹配分值
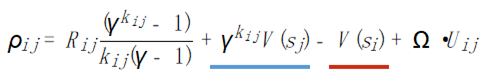
简单来看,这里的匹配分数跟订单终点价值成正比,跟司机当前状态价值成反比,这使得在派单决策中同时考虑到长期收益 (时间维度上的优化) 以及二分图匹配得到的空间上最优解,两者的结合达到时空优化 (spatiotemporal optimality) 的目标。最后,我们在边权计算中加入了对用户体验的刻画,最终的权值综合考虑了长期价值司机收益以及用户体验多个目标。
如何学习针对派单的时空价值函数?
我们使用神经网络来表示上面定义的价值函数,训练通过Bellman方程的价值迭代,如何保证非线性迭代的稳定性以及如何表达状态空间是学习成功的关键。下面我们分为四个部分来介绍我们针对学习的难点提出的技术中的创新。
Cerebellar Embedding
机器学习应用中很重要的一步是如何进行状态表达。我们提出一种新的基于对状态空间不同大小的重叠划分的embedding网络结构。可以促进训练中的知识转移,帮助网络学习多层次的抽象特征,同时能解决训练数据分布稀疏不均的问题。例如人学习人工智能,我们会对人工智能领域进行不同的划分比如强化学习、监督学习,或者图像识别,自然语言处理,推荐系统,或者优化,统计,控制,具体的应用相当于训练数据,会同时激活其中多个分类,比如派单应用会激活 (activate) 强化学习,推荐系统,优化控制等。通过解决不同应用,我们学习掌握到不同类别的知识 (高层次的抽象概念)。当拿到一个新的应用,我们可以很快将这个应用映射到我们掌握的类别上,并利用我们对这些类别的知识来快速地求解这个新的应用,这也就是我们常说的泛化 (generalization) 能力。同样地,我们提出的这个新的网络结构能够提升泛化,形成更丰富的状态表达。
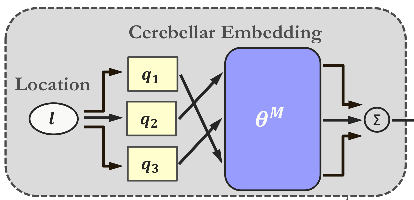
具体在派单中,比如对地理位置的表达,我们使用了大小不同的六边形格子系统对地理空间进行划分,这样具体的地点的状态相当于包含这个地点的多个大小不同的格子对应embedding向量的加总表示。这样学习可以达到两个作用,一是帮助网络学习比经纬度更抽象的概念比如街道,小区,城市等;其次是针对不同区域比如市中心或者郊区网络能自适应学习结合不同分割精度来获得更准确的状态表达。
Lipschitz正则化 (regularization)
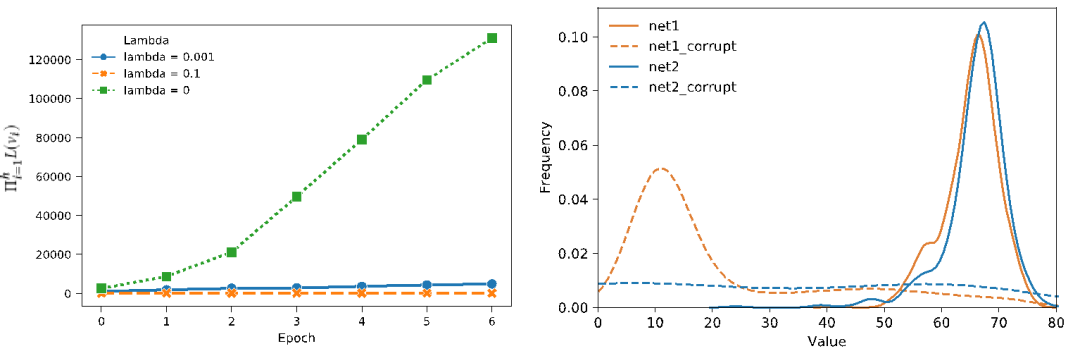
在训练中我们提出一种新的结合了Lipschitz正则化的策略估计方法,通过直接控制Lipschitz常量来学习得到一个更光滑的价值函数。价值函数光滑程度的重要性主要体现在增强状态输入之间关联性以及提高非线性价值迭代的收敛性两方面。如下图所示,黄色跟蓝色分别代表使用了和没有使用Lipschitz正则化的神经网络。一开始两个网络的输入分布几乎重合,在对网络参数加入了相等大小的噪声后,蓝色分布发生了剧烈变化,而黄色分布则体现了对噪声的鲁棒性。
情景随机化 (contextrandomization)
我们学习的状态价值函数带有实时特征,为了使这部分特征有更好的泛化能力我们在训练中使用了类似于Domain Randomization的方法我们称为情景随机化。具体来讲我们会在训练之前基于历史数据建立一个所有实时特征的基于KD Tree的时空索引,在训练时针对每个训练数据的时空状态我们会在索引中查找历史上所有落在这个时空状态附近的实时特征,并从中随机采样用于训练。通过这样使得价值函数在训练中适应不同情况下的实时性,增强对现实中的噪声及variance的泛化能力。
多城市迁移学习 (multi-city transfer learning)
现实中派单具有很强的区域性,一般以城市为中心,不同的城市因为地理位置,气候特征等不同而在供需动态等方面有不同的特性,这可以看作一个典型的多任务学习问题。我们针对派单中的价值估计提出了一种基于progressive network的新的多城市迁移学习框架,可以有效地利用数据量丰富的城市数据来促进对数据稀疏的城市的价值估计;另外,通过在迁移过程中针对不同输入建立不同lateral connection网络能够在训练中更专注于有效的迁移 (比如实时特征的处理) 以及通过训练决定迁移的具体方式及强度 (调整lateral connection的权重)。
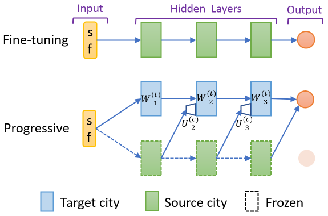
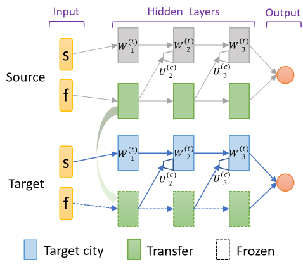
模拟及线上实验结果
我们分别通过线下模拟以及线上AB测试来验证方法的有效性。在基于现实数据的线下模拟实验中,我们与其他四种不同方法进行了系统的多城市多天的对比。在为期多周线上AB测试中,在三个不同城市从不同维度上 (应答率,完单率,司机总收入) 与线上默认方法进行了对比。结果均显示,我们提出的基于神经网络长期价值估计的强化学习派单算法能进一步显著提升平台司机收入以及用户体验。
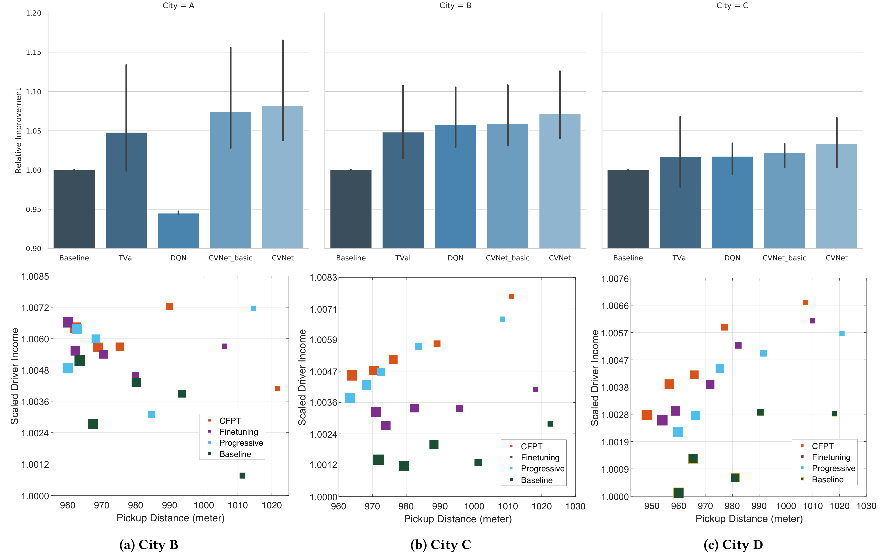
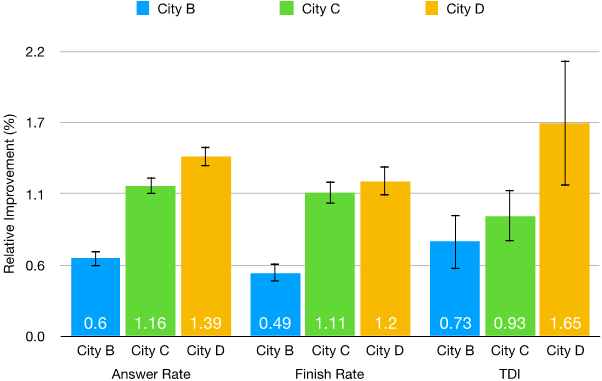
论文全文:https://www.kdd.org/kdd2019/accepted-papers/view/a-deep-value-network-based-approach-for-multi-driver-order-dispatching






