GAN进展到哪了?看这几篇《2018最佳生成式对抗网络论文》
【导读】前段时间介绍了2018年有意思的几篇GAN论文,现在继续推出第二弹解读~
作者|Damian Bogunowicz
点击查看往期回顾:2018年有意思的几篇GAN论文
本篇文章继续介绍两篇论文:
Large Scale GAN Training for High Fidelity Natural Image Synthesis- DeepMind的BigGAN利用Google TPU v3 Pod数百个核心的强大功能,大规模创建高分辨率图像。
ESRGAN: Enhanced Super-Resolution Generative Adversarial Networks:增强型超分辨率生成对抗网络 - 2017年的超分辨率GAN(SRGAN)是将低分辨率图像映射到高分辨率图像的最佳网络之一。 这项工作通过几个有趣的技巧改进了SRGAN。 有人可能会说这只是渐进式改进,但实施的想法真的很聪明!

【讲义下载】
请关注专知公众号(点击上方蓝色专知关注)
后台回复“GAN2019” 就可以获取最佳GAN论文的下载链接~
专知2019年《深度学习:算法到实战》精品课程,欢迎扫码报名学习!

Large Scale GAN Training for High Fidelity Natural Image Synthesis
地址:
http://www.zhuanzhi.ai/paper/6e298366502ea96485aebd288bdcef35
主要思想:

尽管GAN领域的进步令人印象深刻,但使用深度神经网络的图像生成仍然很困难。尽管人们对这个领域非常感兴趣,但我相信在生成图像时还有很多尚未开发的潜力。跟踪GAN进度和衡量其质量的方法之一是初始分数(IS)。该指标既考虑了生成图像的质量,也考虑了它们的多样性。使用来自ImageNet数据集的128x128图像作为示例,来自数据集的真实图像实现 IS= 233 。之前最先进方法是IS = 52.5 ,BigGAN已经将标准提高到 IS = 166.3 !这怎么可能?作者展示了GAN如何从大规模的训练中受益。利用巨大的计算资源可以显着提升性能,同时保持培训过程相对稳定。这样可以创建无与伦比的高分辨率图像(512x512)。
方法:
本研究的重要性并非来自对GAN框架的任何重大修改。在这里,主要贡献来自于使用大量可用的计算能力(由谷歌提供),以使训练更加强大。这涉及使用较大的模型(相对于现有技术的网络参数增加4倍)和较大的批次(增加几乎一个数量级)。结果证明这是非常有益的:
使用大批量(一批2048张图像)允许每批次覆盖更多模式。这样,判别器和生成器得益于更好的梯度。
将每层中的宽度(通道数)加倍可以增加模型的容量,从而有助于提高性能。有趣的是,增加深度会对性能产生负面影响。
额外使用类嵌入可加速训练过程。使用类嵌入意味着在数据集的类标签上调整生成器的输出。
最后,该方法还受益于分层潜在空间 - 注入噪声向量 ž 分成多层,而不是仅在初始层。这不仅可以提高网络性能,还可以加快培训过程。
结果:
大规模训练可以实现高质量的生成图像。然而,它带来了自身的挑战,例如不稳定。作者表明,即使稳定性可以通过正规化方法(尤其是鉴别器)来实施,但网络的质量必然会受到影响。聪明的解决方法是放松对权重的限制,并允许训练在后期阶段崩溃。然后,我们可以应用早期停止技术来在崩溃之前选择一组权重。这些重量通常足以达到令人印象深刻的效果。

类和潜在空间中的良好插值能力证实该模型不是简单地记忆数据。 它能够提出自己的,令人难以置信的发明!

尽管挑选最佳结果可能很诱人,但该论文的作者也对失败案例进行了评论。 虽然诸如a)之类的简单类允许无缝图像生成,但困难的类b)对于生成器来说很难再现。 有许多因素会影响这种现象,例如 类在数据集中的表示程度,以及我们的眼睛对特定对象的敏感程度。 虽然景观图像中的小瑕疵不太可能引起我们的注意,但我们对“怪异”的人脸或姿势非常在意。
ESRGAN: Enhanced Super-Resolution Generative Adversarial Networks
地址:
http://www.zhuanzhi.ai/paper/c61d53470443a49699b11c348e45f1b7
主要思想:

SRGAN的输出与ESRGAN的输出,与作为参考的真实图像。生成的HR图像是LR输入的四倍。 ESRGAN在锐度和细节方面优于其前身。
SRGAN是2017年超分辨率(SR)算法领域的最先进技术。它的任务是拍摄低分辨率(LR)图像并输出其高分辨率(HR)表示。网络的第一个优化目标是最小化恢复的HR图像和真实图像之间的均方误差(MSE)。这相当于最大化峰值信噪比(PSNR),这是用于评估SR算法的常用度量。然而,这有利于过于光滑的纹理。这就是为什么网络的第二个目标是尽量减少感知损失。这有助于捕获纹理细节和高频内容。结果,网络已经学会在这两个相互矛盾的目标之间找到一个最佳点。通过强制GAN跟踪目标,网络产生LR输入的高质量HR表示。一年后,SRGAN方法(由Twitter的科学家提出)得到了中国和新加坡研究人员的改进。新网络可以创建更逼真的纹理,减少工件数量。这是通过几个聪明的技巧实现的。

Residual Dense Blocks转换 - 以获得更好的性能。
方法:
ESRGAN采用SRGAN并采用了几种巧妙的技巧来提高生成图像的质量。 这四项改进是:
引入对生成器架构的更改(从Residual Blocks切换到RRDB,删除批量规范化)。
用相对鉴别器代替普通鉴别器。
关于感知损失,在激活之前使用特征图,而不是在激活之后。
预先训练网络以首先针对PSNR进行优化,然后使用GAN对其进行微调。
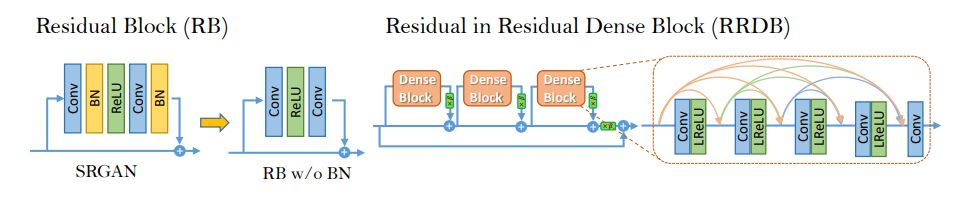
首先,我们从网络中删除批量规范化。其次,我们介绍了结合多级剩余网络和密集连接的RRDB。这为网络提供了更高的捕获信息的能力。
介绍网络架构的主要变化 - 与SRGAN中的生成器使用残差层不同,ESRGAN还受益于密集连接。这不仅可以增加网络的深度,还可以实现更复杂的结构。这样,网络可以学习更精细的细节。此外,ESRGAN不使用批量标准化。学习如何规范化层之间的数据分布是许多深度神经网络中的一般做法。但是,在SR算法(特别是使用GAN的算法)的情况下,它往往会引入令人不快的伪像并限制泛化能力。删除批量标准化可提高稳定性并降低计算成本(减少学习参数)。
用相对判别器取代普通的判别器 - 使用相对判别器,网络不仅可以从生成的数据接收梯度,还可以从实际数据接收梯度。这提高了边缘和纹理的质量。
重新审视感知损失 - 感知损失试图比较重建图像之间的感知相似性 G(X_LR)和真实图像 X_HR。通过预先训练的VGG网络运行两个输入,我们在第j次卷积和激活后以特征映射的形式接收它们的表示 φ ( G(X_LR)) 和 φ ( X_(HR)) 。 SRGAN的任务之一是尽量减少这些表示之间的差异。 ESRGAN的情况仍然如此。但是,我们在第j次卷积之后但在激活之前采用表示。
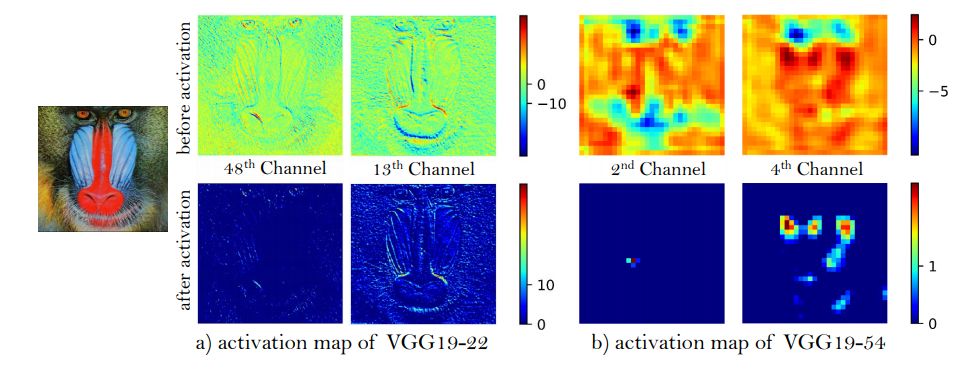
随着我们越来越深入,激活后的层往往会给我们提供更少的信息。 这导致监督薄弱和性能低下。 因此,使用预激活特征映射更有益。
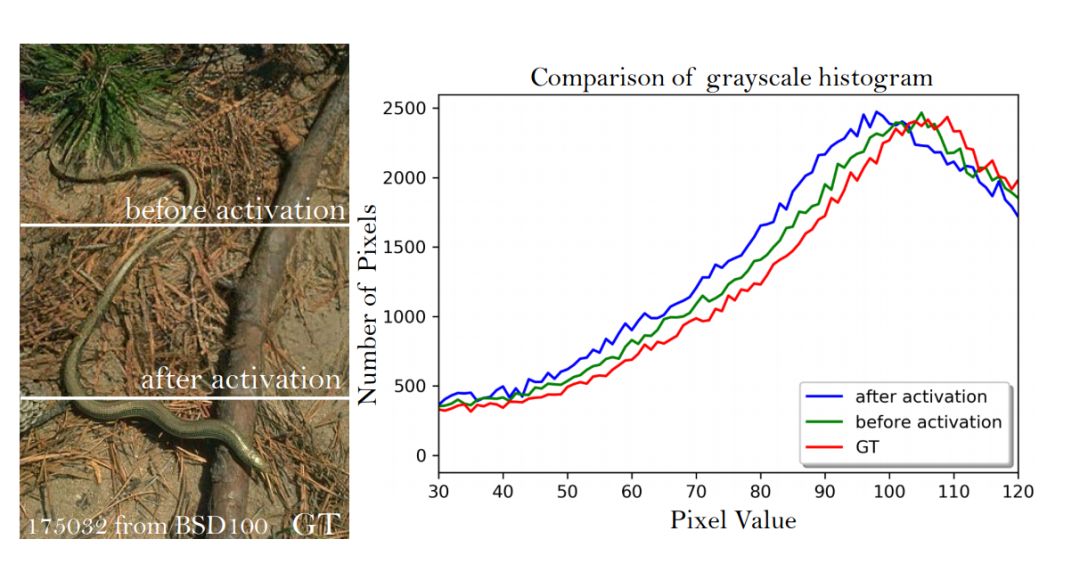
另外,与真实图像相比,激活后特征图还导致不一致的重建亮度。
网络插值
结果:
实验类似于在SRGAN上进行的实验。目标是将LR图像缩放4倍,并获得尺寸为128x128的高质量SR图像。
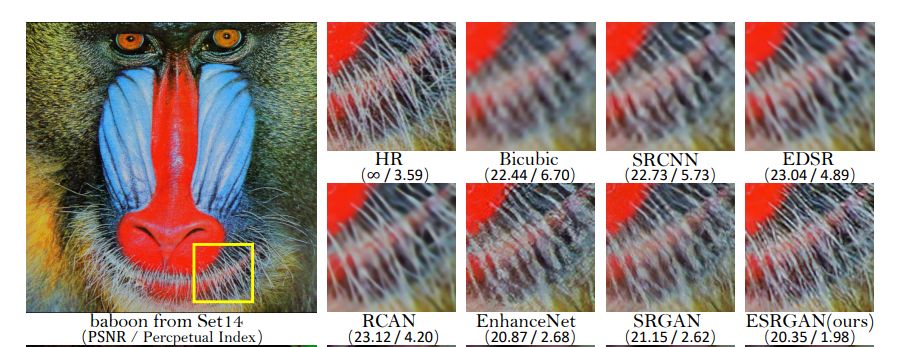
目前,ESRGAN是超分辨率的最先进技术。

在两个相互矛盾的目标中间插值:最小化PSNR或最大化感知相似性
作者在PIRM-SR挑战中对他们的网络进行了测试,其中ESRGAN以最佳感知指数赢得了第一名。
原文链接:
https://dtransposed.github.io/blog/Best-of-GANs-2018-(Part-2-out-of-2).html
-END-
专 · 知
专知《深度学习:算法到实战》课程全部完成!467位同学在学习,现在报名,限时优惠!网易云课堂人工智能畅销榜首位!
请加专知小助手微信(扫一扫如下二维码添加),咨询《深度学习:算法到实战》参团限时优惠报名~

欢迎微信扫一扫加入专知人工智能知识星球群,获取专业知识教程视频资料和与专家交流咨询!

请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

点击“阅读原文”,了解报名专知《深度学习:算法到实战》课程

