严达 (Daniel Yan)| yanda@uab.edu
计算机科学系助理教授 | 美国阿拉巴马大学伯明翰分校
[欢迎随时跳过文字看最后的讲座视频直接了解 T-thinker]。
什么?是不是又是一个关于设计大同小异的并行编程框架的炒作?是不是又是把各种简单烂大街问题(join, connected components, single-source shortest paths, PageRanks)统一一下编程接口(答案是不,我们处理更高级多样的计算问题)?这个与我有什么关系?
别急着离开… 接下来几段马上告诉你!与以往的并行编程框架不同,T-thinker 是针对计算密集型(compute-intensive)任务的。
相反,现有编程框架是针对数据密集型(data-intensive)任务的,在处理是针对计算密集型任务时可能比单机上的串行程序还慢(哪怕你用上 1000 台电脑同时算)!你不相信?我来列举一下证据。
这个现象早在 10 年前就有人发现了:Siddharth Suri 和 Sergei Vassilvitskii 在 2011 年的 WWW 会议上发表题为《Counting triangles and the curse of the last reducer》的论文, 开创性地提出了数三角形算法的 MapReduce 版本(根据谷歌引用,目前高引达 480 多次)。
然而一年以后 Shumo Chu 和 James Cheng 在他们 ACM TKDD 期刊论文《Triangle listing in massive networks》中犀利地指出: Siddharth Suri 和 Sergei Vassilvitskii 的 MapReduce 方法使用 1636 台电脑花费了整整 5.33 分钟才完成一个数三角形的任务,而 Shumo Chu 和 James Cheng 提出的单机外存串行算法在同样的任务上仅仅花费 0.5 分钟!
换句话说,为了使用分布式框架,Siddharth Suri 和 Sergei Vassilvitskii 花费了 1636 倍的计算资源却获得了 10 倍的性能降速!无独有偶,Frank McSherry 等人在他们 HotOS 2015 研讨会论文《Scalability! But at what COST?》中犀利地指出,现有的顶点式图计算系统其性能和在笔记本上跑一个简单的串行程序其实差不多。这之后,Frank McSherry 更是在他题为《COST in the land of databases》的部落格(https://github.com/frankmcsherry/blog/blob/master/posts/2017-09-23.md) 进一步 diss 了大数据系统研究(具体见图 1)…
![]()
图 1:Frank McSherry 部落格 “COST in the Land of Databases” 对大数据系统的相关评论。
这里性能问题的根源在于,对于一个含有 n 个点的图,其数三角形的复杂度是 O(n^1.5),而一般数据密集型框架最擅长的是迭代(iterative)计算,即运行有限的迭代轮数(比如常数或者 O(log n)),而且每轮的代价和输入呈线性关系(即 O(n))。换句话说,数据密集型框架擅长的算法的总工作量仅限于 O(n log n)的量级。
该结论被很多人已经注意到,例如樊文飞等在 PVLDB’13 上发表的论文《Making queries tractable on big data with preprocessing》以及 Lu Qin 等在 SIGMOD’14 上发表的论文《Scalable big graph processing in MapReduce》均指出可扩展性好的 MapReduce 程序是 O(n log n)的,而笔者领衔发表在 PVLDB’14 的论文《Pregel algorithms for graph connectivity problems with performance guarantees》对在谷歌的 Pregel 框架下的图计算程序给出了同样的结论。相反,T-thinker 框架可以轻松处理 NP 难的计算问题,保证计算性能随着 CPU 核数增加而显著提高!
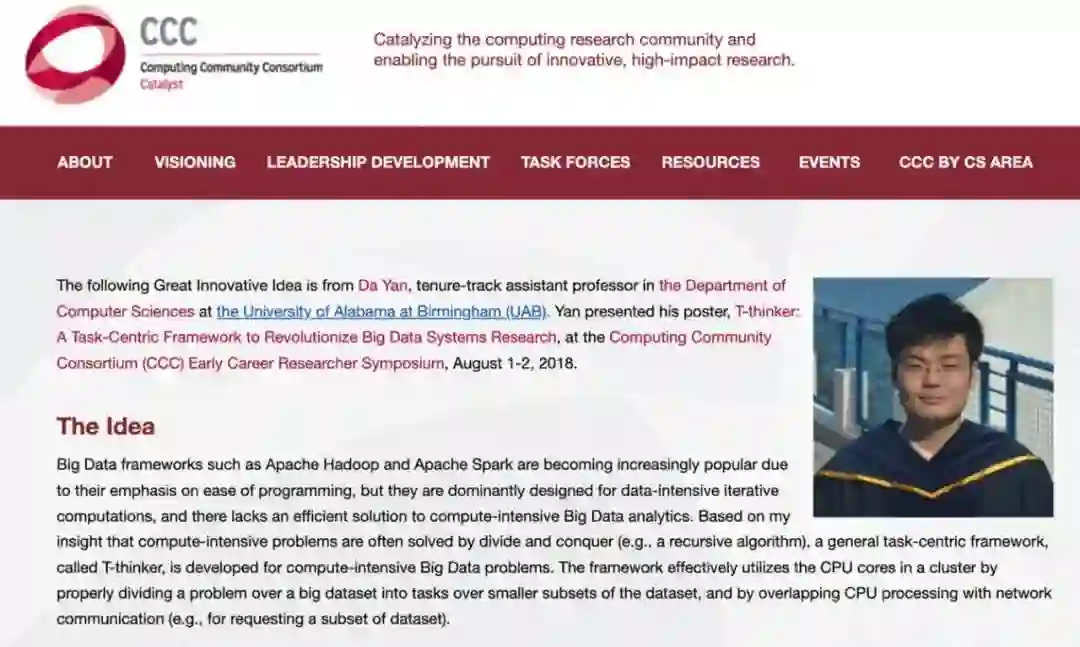
如果现在还没说服你继续读下去,而你恰好是搞大数据系统和算法研究的学者(业界见文本最后哈,不要走开!),那让我们看看 T-thinker 的研究可以在顶级计算机会议和期刊上有多高产!值得注意的是,T-thinker 是一个非常新的 topic:初步的概念发表在笔者等在 PPoPP’19 上的海报(poster)论文《T-thinker: A Task-Centric Distributed Framework For Compute-Intensive Divide-and-Conquer Algorithms》上,并且被计算研究协会(CRA)的计算社区联盟(CCC)评为伟大的新创意之一(https://cra.org/ccc/great-innovative-ideas/t-thinker-a-task-centric-framework-to-revolutionize-big-data-systems-research/,见图 2)。可以看 YouTube 的小伙伴们的可以戳这里看 T-thinker 相关的介绍性短视频: https://www.youtube.com/watch?v=3ub2ACLlg6M (见图 3)。
![]()
图 2:T-thinker 被评为 CCC Great Innovative Idea。
![]()
图 3:CCC 早期职业学者研讨会上笔者对 T-thinker 的介绍性短视频
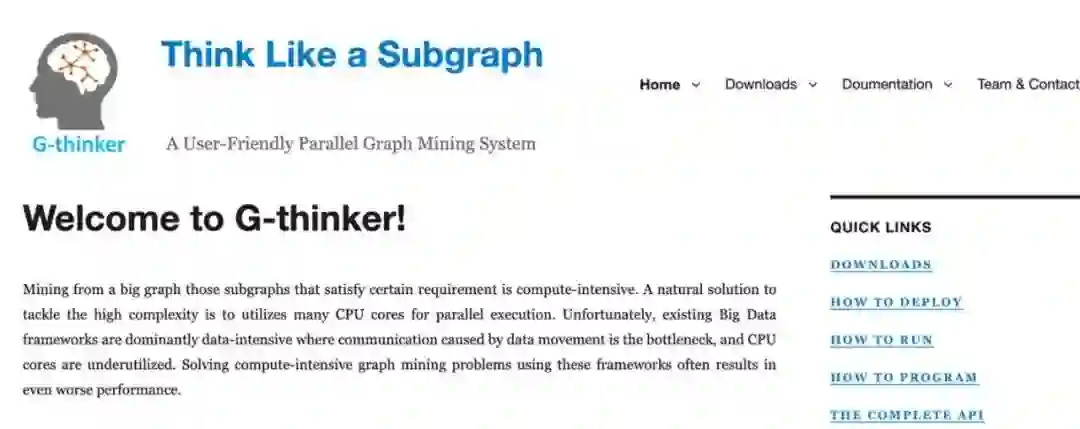
从 2020 年开始笔者的研究团队开始根据 T-thinker 框架开发了一系列大数据挖掘系统,均发表在数据库最顶级的会议及期刊上。第一个系统是 G-thinker,用于解决从大图上寻找满足用户定义的条件的子图实例的问题,比如数三角形,找高密度子图(比如对应社交团体)以及子图匹配。G-thinker 可以通过 https://bit.ly/gthinker 访问(见图 4),其开发获得美国科学基金(NSF),南部大数据中枢(South BD Hub)以及微软的 Azure 云平台的资助。发表的相关论文顶会顶刊云集,包括:
-
G-thinker: A Distributed Framework for Mining Subgraphs in a Big Graph (ICDE’20)
-
Scalable Mining of Maximal Quasi-Cliques: An Algorithm-System Codesign Approach (PVLDB’20)
-
G-thinker: A General Distributed Framework for Finding Qualified Subgraphs in a Big Graph with Load Balancing (VLDB Journal 2022)
-
Parallel Mining of Large Maximal Quasi-Cliques (VLDB Journal, accepted in 2021)
-
Maximal Directed Quasi-Clique Mining (ICDE’22)
笔者博士生郭桂木(同济大学硕士)在 G-thinker 研究方面做出了重要贡献,并于今年(2022)获得了美国新泽西州 Rowan 大学长聘轨制助理教授的职位。其他博士在读团队成员也是顶会顶刊论文云集,并正不断着手开发新的基于 T-thinker 框架的数据挖掘系统。
![]()
第二个基于 T-thinker 框架的系统是 PrefixFPM,用于在事务(transaction)数据库上挖掘各种频繁的模式 (pattern),即被超过一定指定数量事务包含的模式。模式的类型由用户灵活指定,包括 itemset,子树,子图,甚至是子矩阵。发表的相关论文也是顶会顶刊云集,包括:
-
PrefixFPM: A Parallel Framework for General-Purpose Frequent Pattern Mining (ICDE’20)
-
Parallel Mining of Frequent Subtree Patterns (LSGDA@VLDB’20, invited keynote)
-
PrefixFPM: A Parallel Framework for General-Purpose Mining of Frequent and Closed Patterns (VLDB Journal 2022)
-
Mining Order-Preserving Submatrices Under Data Uncertainty: A Possible-World Approach and Efficient Approximation Methods (ACM TODS, accepted in 2022)
频繁模式挖掘的另一个环境设定是考虑一个单独的大事务,比如一张大图或者一个地理空间数据集 (for colocation patterns)。与该环境设定对应的系统笔者的博士生 Lyuheng Yuan(UPenn 硕士)正在如火如荼的开发中,相信不久后就会面世。
第三个基于 T-thinker 框架的系统是 TreeServer,用于构建基于决策树的各种预测模型,包括 deep forest 这样的大模型。相关论文《Distributed Task-Based Training of Tree Models》今年在 ICDE’22 上发表。
值得注意的是,T-thinker 系列系统的研究仅仅刚刚开始,而且笔者研究团队目前还有好多相关系统已经筹划好排着队等待开发!相信还有非常多的研究机会等待大家发掘(行动要快喔)!笔者第一个博士生郭桂木(大弟子)在 IEEE BigData 2020 对这个方向有个教程报告(tutorial),您有兴趣的话欢迎访问 https://www.youtube.com/watch?v=uq4CndPj6pY 观看。希望到这里我已经说服你来了解下 T-thinker 到底是什么,以及我们 T-thinker 的相关工作了。
什么?你是工业界的且对发系统论文不感兴趣?别走开啊,注意我们的题目:T-thinker 是继 MapReduce, Apache Spark 之后的下一代大数据并行编程框架!T-thinker 克服了现在数据密集型系统对计算密集型任务的执行低效问题,但是它同样可以高效支持数据密集型任务!发现了吗?T-thinker 可能是取代 Spark 等大数据编程框架的下一代编程模型!注意到没有,现在大家都用 Spark 已经没什么人用过时的 MapReduce 了…
想不想成为自己公司第一个启动 T-thinker 编程框架项目或者 T-thinker 云平台支持的负责人?还等什么,赶快听一下下面为时一小时干货满满的讲座,详细了解下 T-thinker 的技术概念吧!
![]()
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com