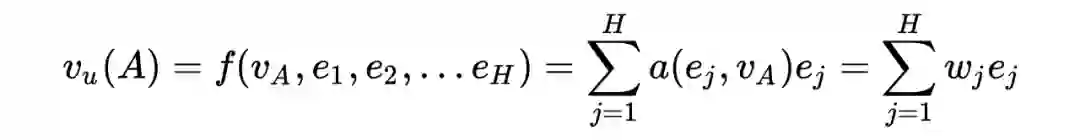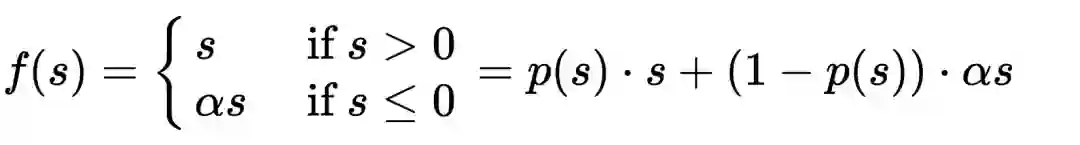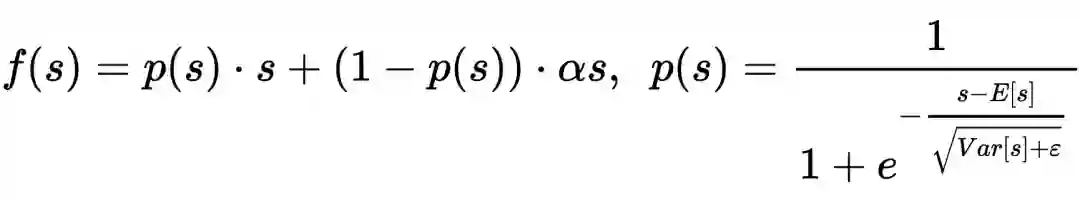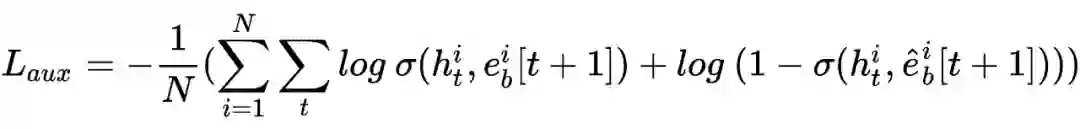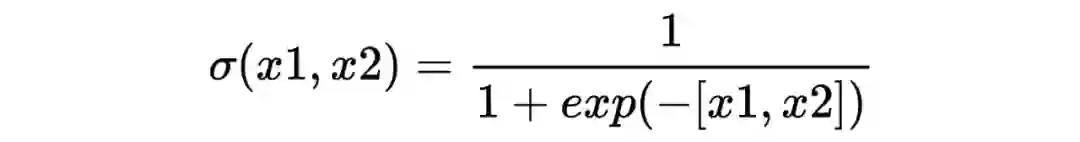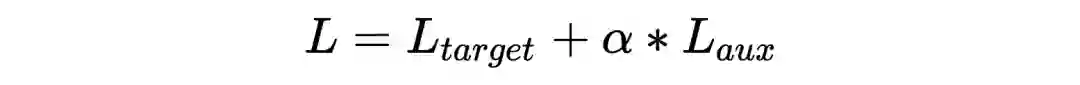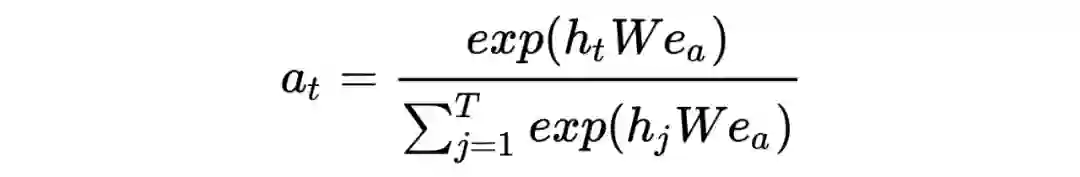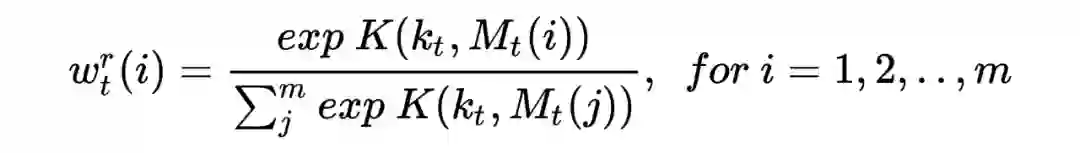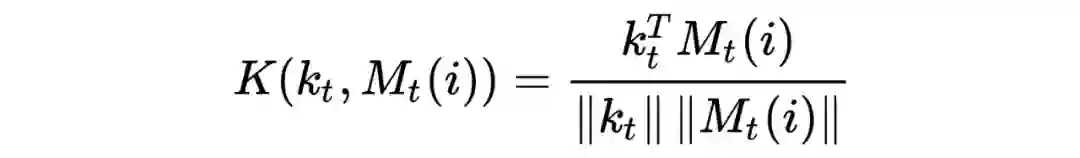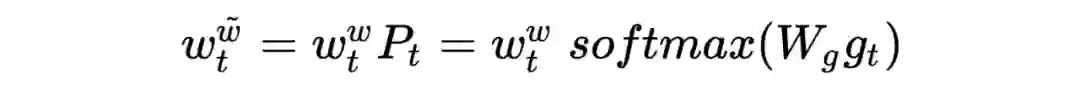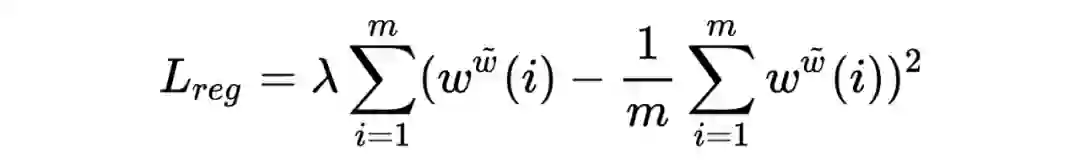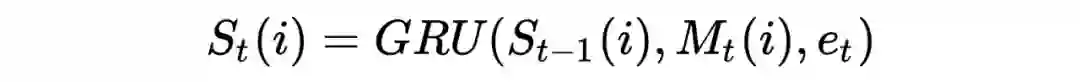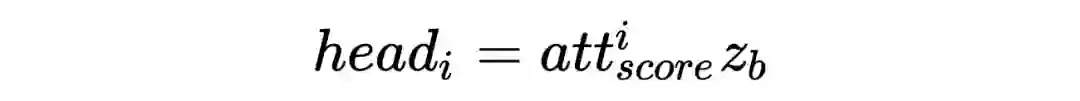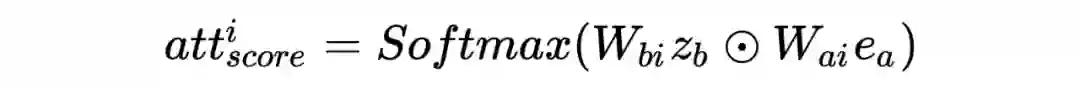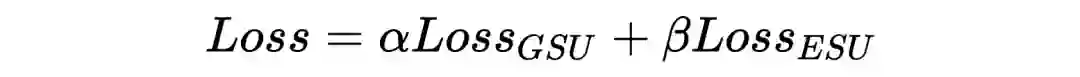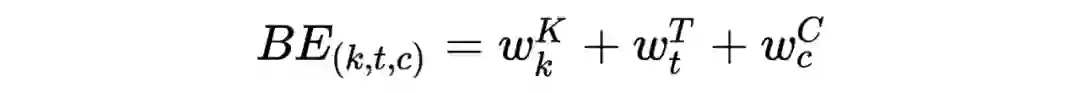©作者 | Glenn
单位 | 腾讯
研究方向 | 数据挖掘、计算广告
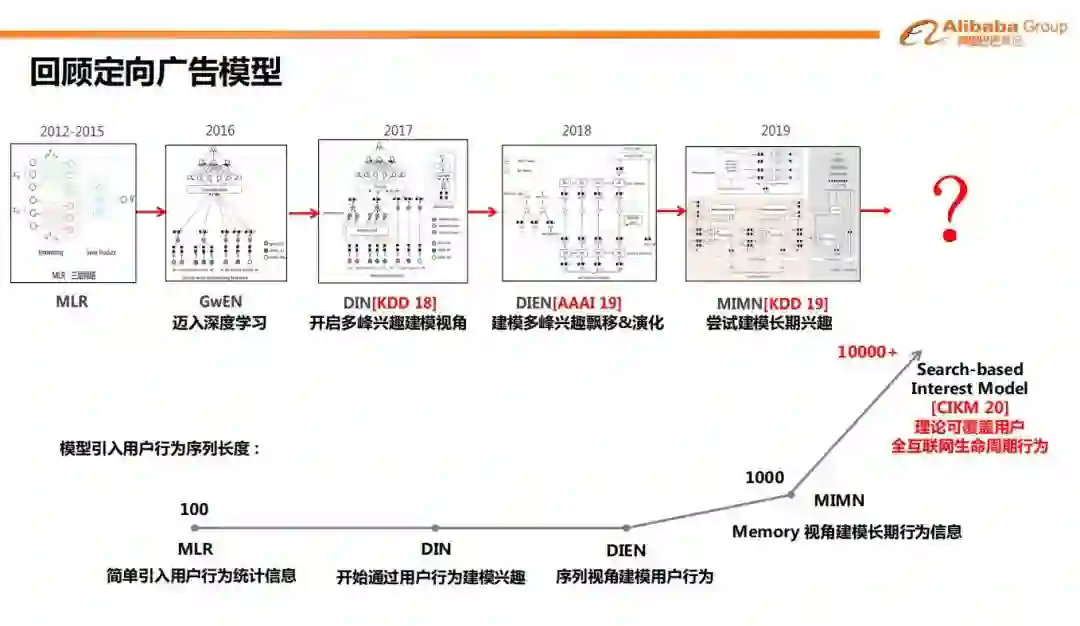
如下图
[1][2]
,阿里妈妈的精排模型,经历了从传统 LR、MLR 到深度模型 GwEN,再到用户兴趣建模的过程。
传统的深度模型(如GwEN),一般采用 Embedding&MLP 的形式,它会将用户的所有兴趣信息转化为一个定长的向量。但用户的兴趣是多样的,定长的向量可能不足以表达。而且评估用户对于不同商品/广告的兴趣时,应该使用不同的行为(
判断用户是否喜欢衣服,应该关注用户对衣服的历史行为与兴趣程度;判断用户是否喜欢包包,则关注用户对包包的历史行为 )。因此盖坤团队提出 DIN,从用户行为中提取与目标商品相关的多峰兴趣;
DIN 模型更多是从挖掘多峰兴趣角度出发,没有考虑行为的序列信息,兴趣的变化也能给模型提供信息,因此有了 DIEN;这两个模型后,用户兴趣建模划分出了 2 个研究分支,一个是用户长期兴趣建模(MIMN、SIM),该分支依然是盖坤团队主导的;另一个分支则是从 session 的角度,对行为做进一步划分(DSIN)。
DIN [3][4]
2.1 简介
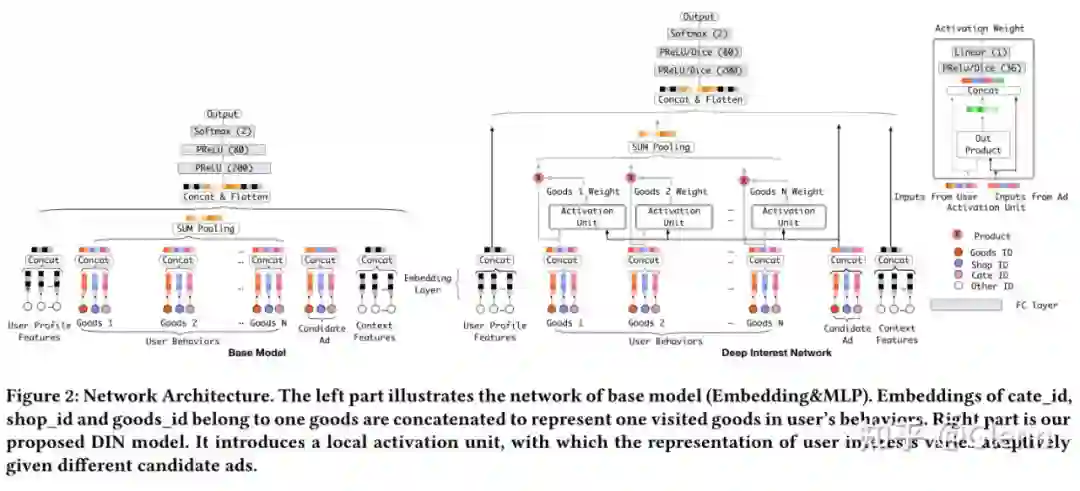
如上左图是传统的 Embedding & MLP 模型,处理行为数据采用 sum-pooling 得到定长的 embedding
[2,3]
。
这里行为的定义可以是广告点击、商品购买、加购物车等,每个行为节点由 3 个 embedding 拼接组成(商品 ID、商品类别 ID、商铺 ID)。
右图是 DIN 的模型结构,作者将每个行为节点(
)与候选节点做交叉得到权重(即途中的 activation unit),再通过 weighted-sum-pooling 的模型得到行为的 embedding,即
其中,u 是用户,A 是商品/广告,
为候选商品的 embedding。这样,对于每个候选商品,提取的用户行为 embedding 是不同的。
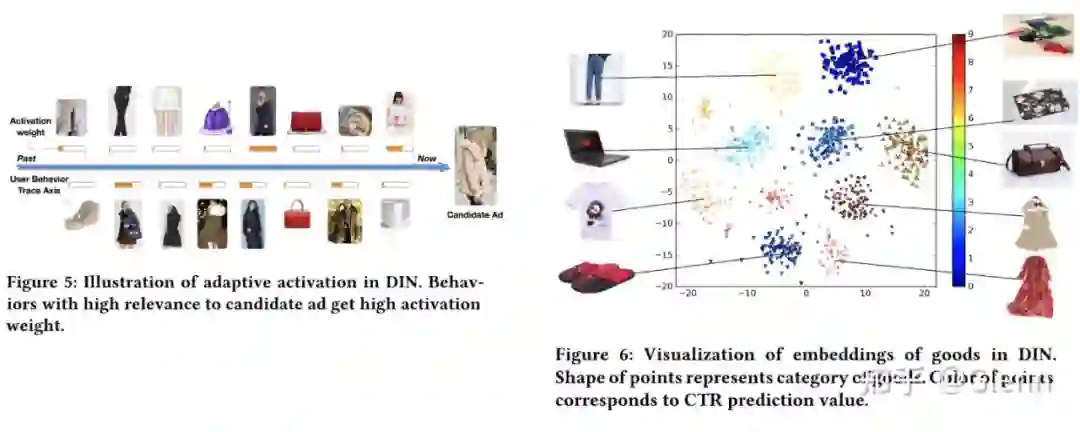
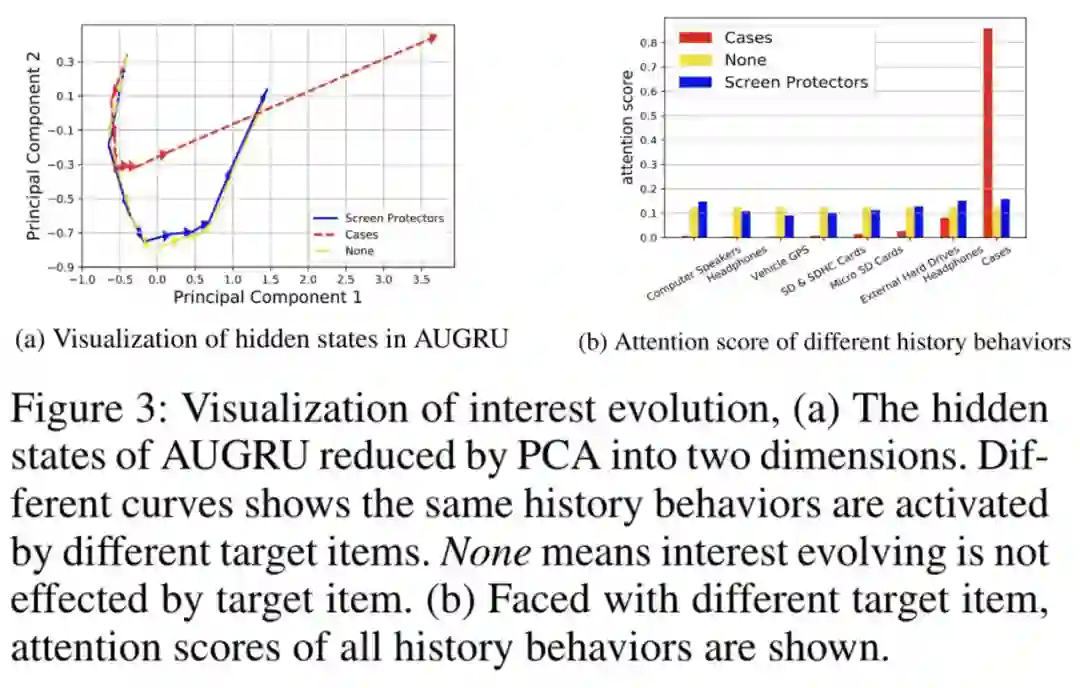
作者在实验部分可视化了 activation unit 的结果,和候选商品相关的行为节点会贡献较大的权重,符合认知
2.2 创新细节
这种行为兴趣的建模方式,在实际应用时会遇到一些问题:
1. 行为数据的参数量巨大(商品 ID 可能就百/千万),模型容易过拟合;引入 L2 正则,参数量大训练缓慢。
2. 针对不同的候选节点,用户的兴趣 embedding 不同,波动大会影响 MLP 部分的模型收敛。
1. 提出 Mini-batch Aware Regularization。L2 正则缓慢的原因是每个 mini-batch 会对模型的所有参数做正则,但其实每个 minibatch 只使用了部分的商品 ID。因此更好的做法是,每个 mini-batch 只对使用到的商品 ID 计算 L2 正则。实验证明,通过这种方式,能有效缓解过拟合现象,同时确保训练效率。
2. 作者针对 MLP 部分的激活函数(PReLU)做优化,提出更具泛化性的 Dice,这种激活函数可以根据输入数据的均值和方差,动态调整函数形态。在后续的论文中,模型也延用了这种激活函数。
2.3 优缺点
1. 该模型能动态获取用户的多种兴趣。但没有考虑行为的先后关系(序列)、兴趣的变化过程等。
2. 候选商品与每个行为节点计算权重,仅适用较短的行为序列(论文中采用 14 天的曝光日志,每个用户平均 35 个行为)。
3. 对比传统的 Embedding&MLP 的模型,计算复杂度提升。上线时也做了一些 GPU-CPU 的计算优化。
DIEN
3.1 简介 [5][6]
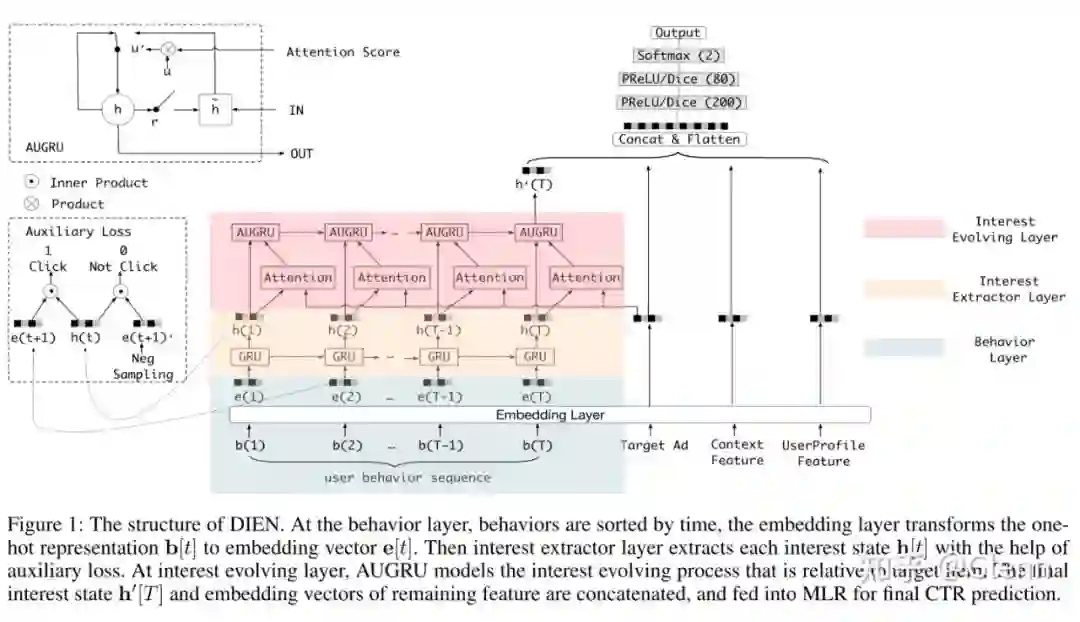
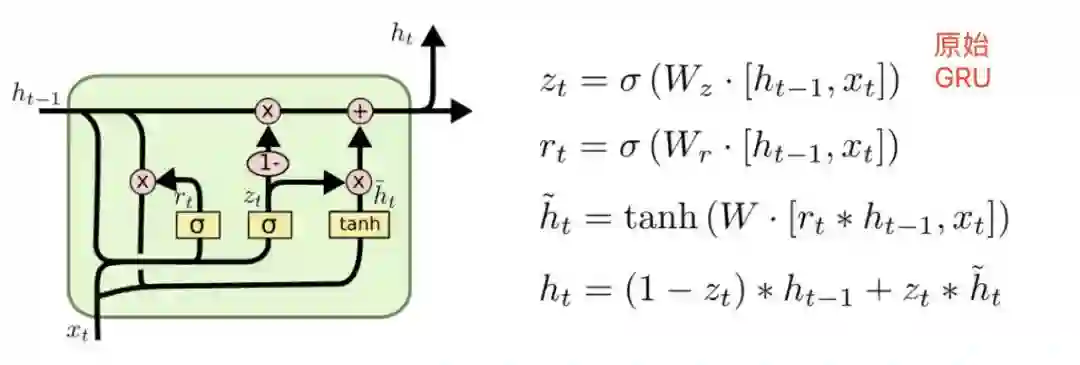
针对 DIN 没有考虑行为先后关系、兴趣变化过程的问题,盖坤团队继续优化模型结构,引入 GRU 提取行为序列中的信息,并结合 DIN 中目标 AD 与行为节点计算权重的模式(Attention),提出 AUGRU 进一步挖掘兴趣变化中的信息。
3.2 创新点
提出了兴趣提取层(Interest Extractor Layer)和兴趣演进层(Interset Evolving Layer)两个创新点:
实际业务场景中,用户的行为序列可能比较长(14 天数据平均 30+ 长度),为了避免梯度消失,作者采用 GRU 提取隐式信息。
考虑到整个模型结构较复杂,只有一个最终 loss 不足以训练时序结构。作者
在特征提取层引入了辅助 loss 。
具体的,GRU 本身也是用于预测下一个行为节点,故可以引入此任务做辅助。假设用户 i 的行为序列为
,在时刻 t,GRU 的输出为
,t+1 时刻的行为节点为
,我们随机采样的其他节点为
。则辅助 loss 为
其中,
整体 Loss 为:
兴趣提取层主要学习序列信息,但是序列中那些节点更有助于判别用户对候选 AD 的兴趣呢?作者借鉴 DIN 的方法,提出 Attention 的机制,计算兴趣提取层中每个隐层输出与候选 AD 的相关性。
考虑到隐层行为本身是序列相关了,为了不打破这种序列关系,作者考虑将相关性计算融入序列,提出 AUGRU。
具体的,是将上述计算的权重,作为 GRU 更新门 [7] 的一部分,如下
实验中,作者也可视化了引入权重后,序列 embedding 会有较强的指向性变化(如下左图中,曲线是对演进层每个输出做 PCA 后链接其他的结果,黄色是没有 attention 的结果,蓝色是目标 AD 与行为均不相关时的结果,红色是目标 AD 与某个行为相关时的结果)。
3.3 优缺点
1. 引入 GRU 提取行为序列信息,但模型结构复杂,上线时除了做 GPU-CPU 的计算优化,作者还提到模型压缩,互殴去相对轻量级的模型上线
2. 吃不下过长的行为序列,LSTM/GRU 一般能承受的行为序列长度为 30-50;实验中采用 49 天数据,每个样本行为序列为 14 天(序列长度 150 截断)
MIMN [8][9]
4.1 动机和目标
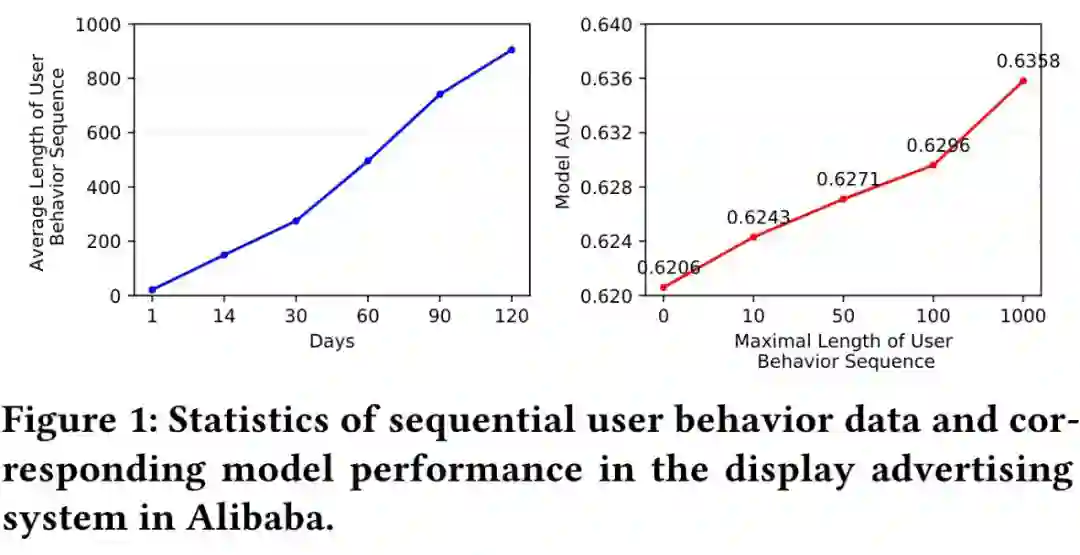
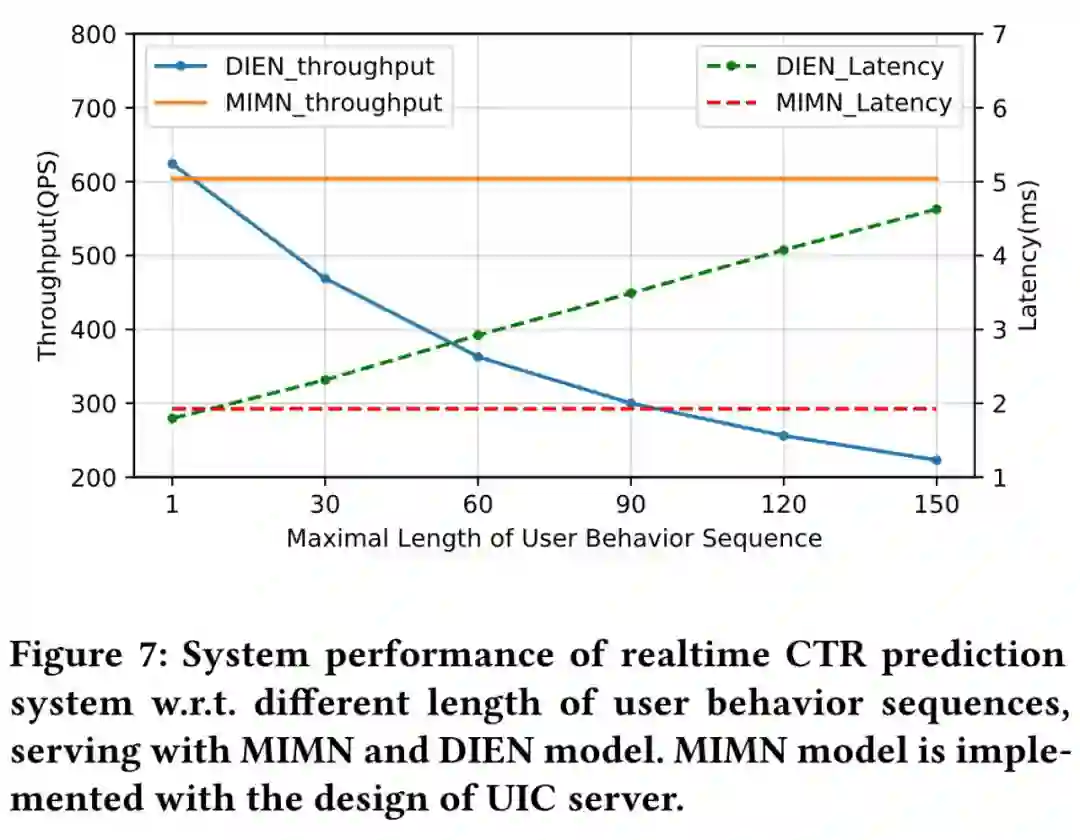
DIN、DIEN 处理的序列长度都有限(最大为 150),而离线实验验证,采用的行为序列越长,模型收益越大。因此意愿上是期望使用更长(1000)的行为序列(long-life),但长的行为序列会带来两个问题。
1. 存储限制:天猫广告业务上,6 亿用户,14 天行为序列(最大长度 150),消耗 1TB 的存储,如果序列长度放开到 1000,预计消耗 6TB(估计也用不到,毕竟大序列的可能都属于长尾)。
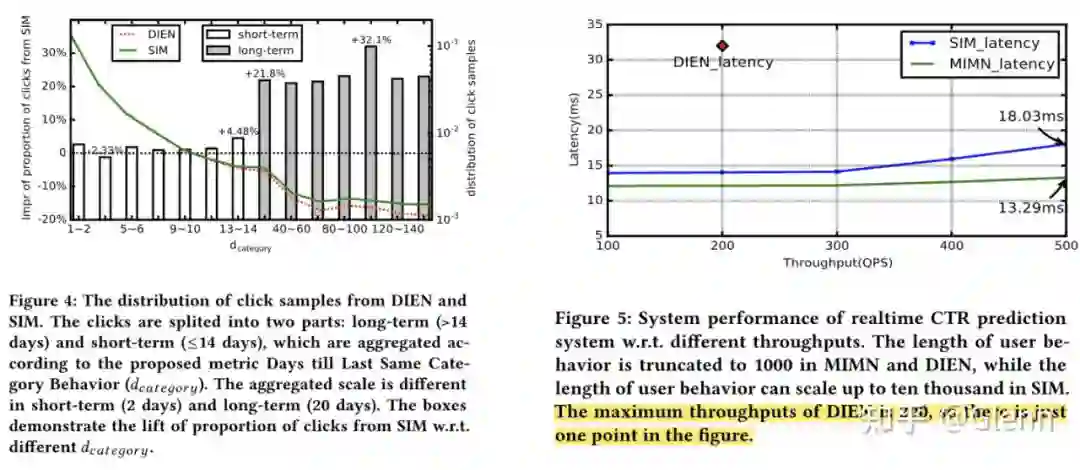
2. 时延限制:精排一般是 10ms,DIEN 上线已经达到 14ms,如果继续拉大序列长度,预计时延会达到 30ms。
针对上述两个问题,作者开始了优化 MIMN 的优化之路。
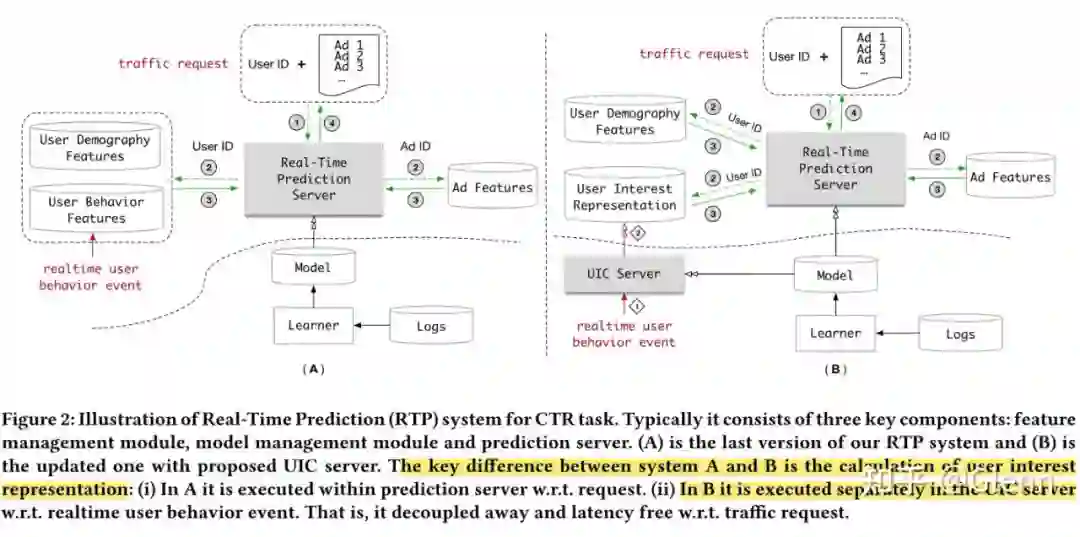
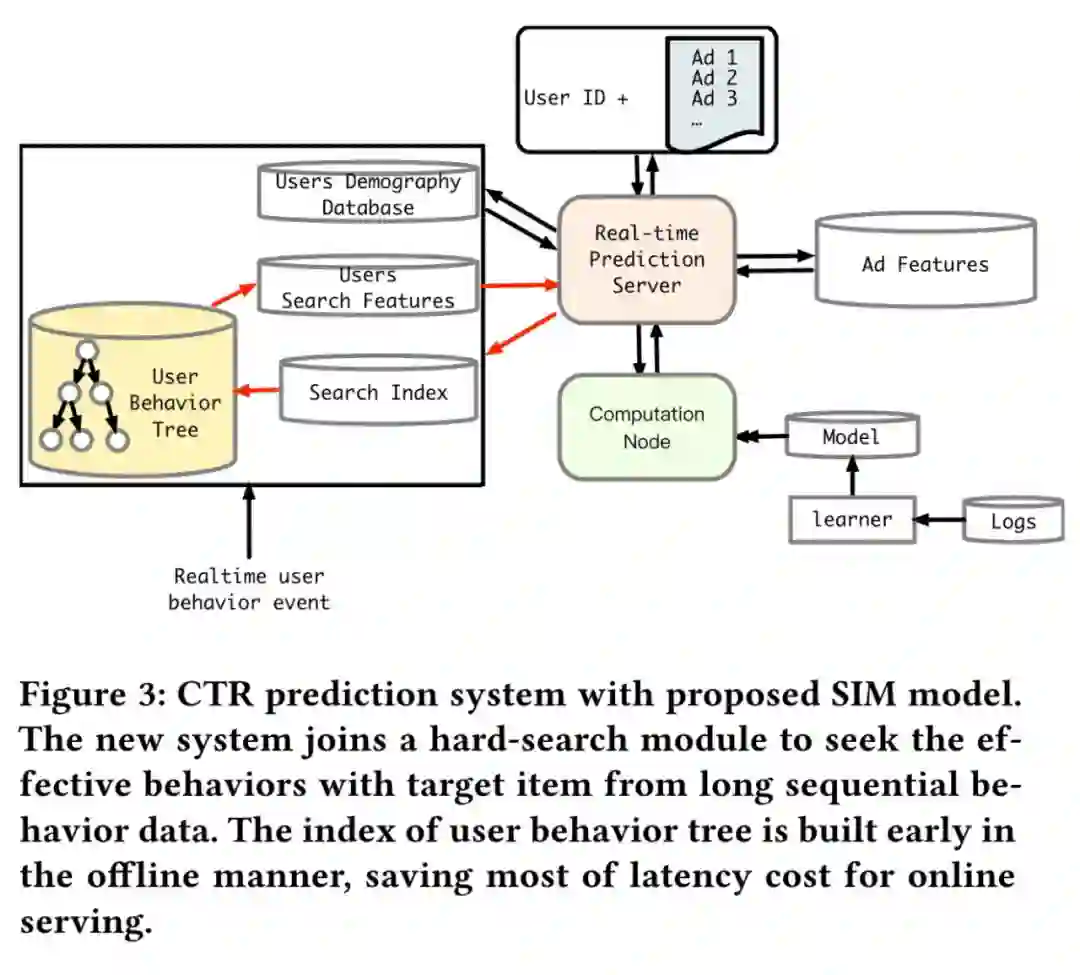
4.2 计算分离(User Interest Center)
维护一个离线的用户兴趣中心,存储当前时刻的兴趣 embedding 结果(存储序列消耗资源大,存不下),每次有新的用户行为进来时更新 embedding。广告请求来时,给 UIC 发请求,获取兴趣 embedding 供线上计算。
4.3 长序列兴趣提取
UIC 的解决方案会引入一个新问题,
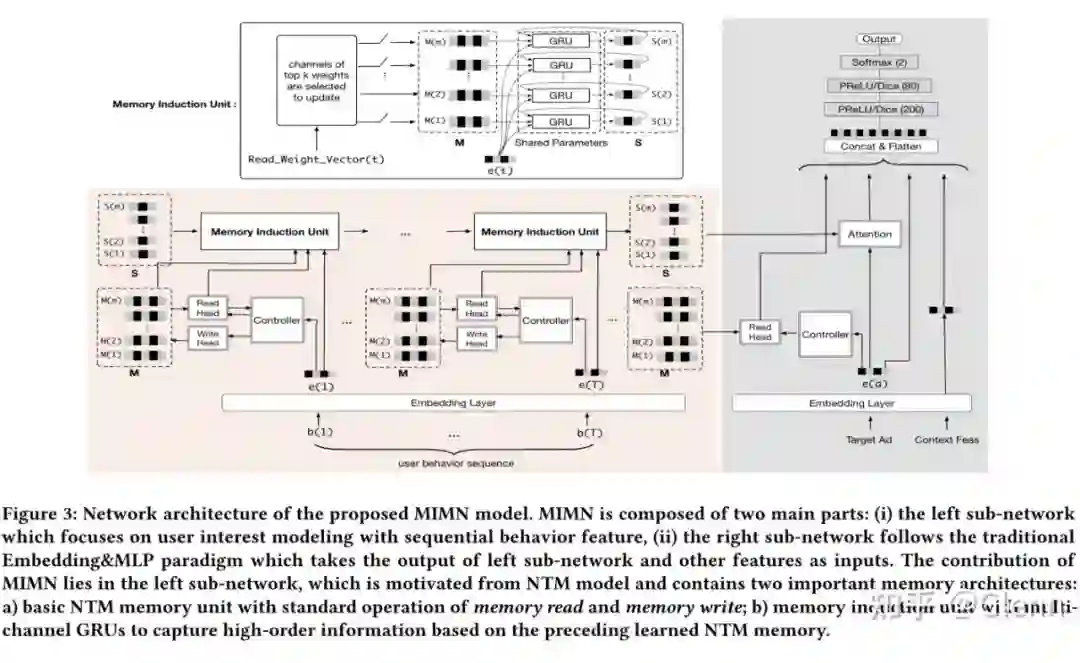
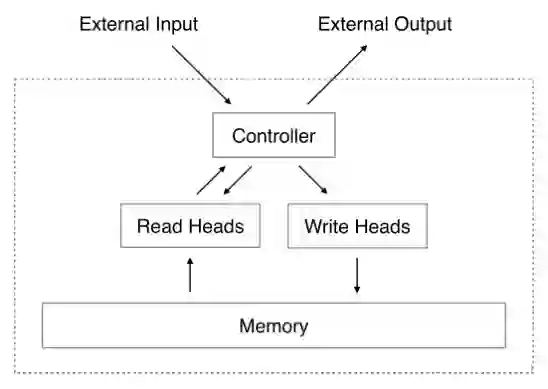
如果保存当前时刻的 embedding,并且这个结果是能增量更新的? 作者借助记忆网络 NTM 来处理这个问题。整体模型结构如下,左下角部分为行为序列处理结构,Controller、Read Head、Witer Head、M 均为 NTM 的原始模型结构,Memory Induction Unit 为作者创新的部分。
离线计算时,左下角的结构能得到当前时刻每个用户的行为序列特征 S,兴趣矩阵 M,并存储在 TAIR 存储系统中。线上请求到来时,查询 TAIR 里对应用户的特征序列和兴趣矩阵,并将候选 AD 的 embedding(
)输入模型的 Controller 部分,今儿提取相关的兴趣和序列结果,作为 MLP 模型输入的一部分。
论文重点介绍了 NTM、Memory Induction Unit 两部分:
这是 Google 于 14 年提出的记忆网络结构,该结构由 Controller、Memory 两部分构成,Memory 存储了一个记忆矩阵
。这里,作者把矩阵的每一行想象成一种兴趣类型。Controller 可以想象成 MLP/LSTM 等结构。
1)读操作:在线请求时用,输入是候选商品 /AD 的 embedding
将外部输入经过 Controller 得到读操作头
计算存储矩阵中每一行结果(论文里作者当作用户某种类型的兴趣)与读操作的相关性,作为特征的权重,即
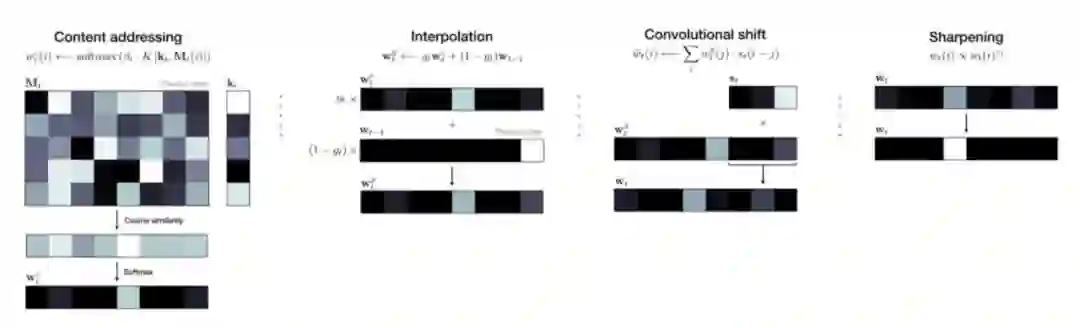
*论文里介绍的相对简单,其实还包含了平滑、锐化等操作,更进一步的了解可以参考 [10]。
2)写操作:离线计算,初始训练/用户新增行为时用
将新增行为经过 Controller 得到写操作头,包含 Erase Vector(
)和 Add Vector(
)两部分
*具体操作可以参考 [11]
(1)存储利用的归一化(Memory Utilization Regularization)
这是针对写操作的一种优化。行为序列中的 Item 也存在马太效应,大量热门 item 的进入,导致写操作存在大量相同的输入(写操作头相同),此时存储矩阵中的某些行被频繁更新,某些行却被忽略。作者提出优化写操作头的构造方法 。
具体的,假设原来的写操作权重为
,作者引入累积更新权重、对写操作头做了新一层的封装,如下:
在此基础上,作者在损失函数增加了正则化项限制累积更新权重的方差
(2)Memory Induction Unit(MIU)
NTM 的结构没有提取时序信息,作者提出 MIU 的结构,获取每个时刻行为序列的结果。具体的,对于时刻 t,作者从读操作权重中选择 top k,即
4.4 优缺点
1. 时延:提出计算分离的模式,使得模型处理长序列(序列长度为 1000)都不存在时延的压力,如下图
2. 存储:提出 NTM 的结构,存储系统只需要为每个用户维护存储矩阵 Mt 和序列矩阵 S,不需要单独保存行为序列,存储量从 6T 转为 2.7T
3. 效果:计算分离后,兴趣的提取无法很好的和候选 AD / 商品交互(仅通过存储矩阵实现交互),可能会对效果有损
4. 同步:时序模块的结果和 ctr 模型是异步更新的,行为序列频繁更新可能导致模型效果波动,需要有一定的回滚机制
5. 适用性:
当用户行为丰富且行为更新频率没有远高于请求时,可以使用该模型。这是因为该模型时针对长序列行为建模的,行为数据不丰富当然不必使用。而如果用户行为更新频繁,ctr 模型都来不及更新,可能会使预测结果产生波动。
6. 其他:
作者提到双 11 时虽然行为数据丰富,但用户行为特殊,提取出来做特征效果反而下降 。
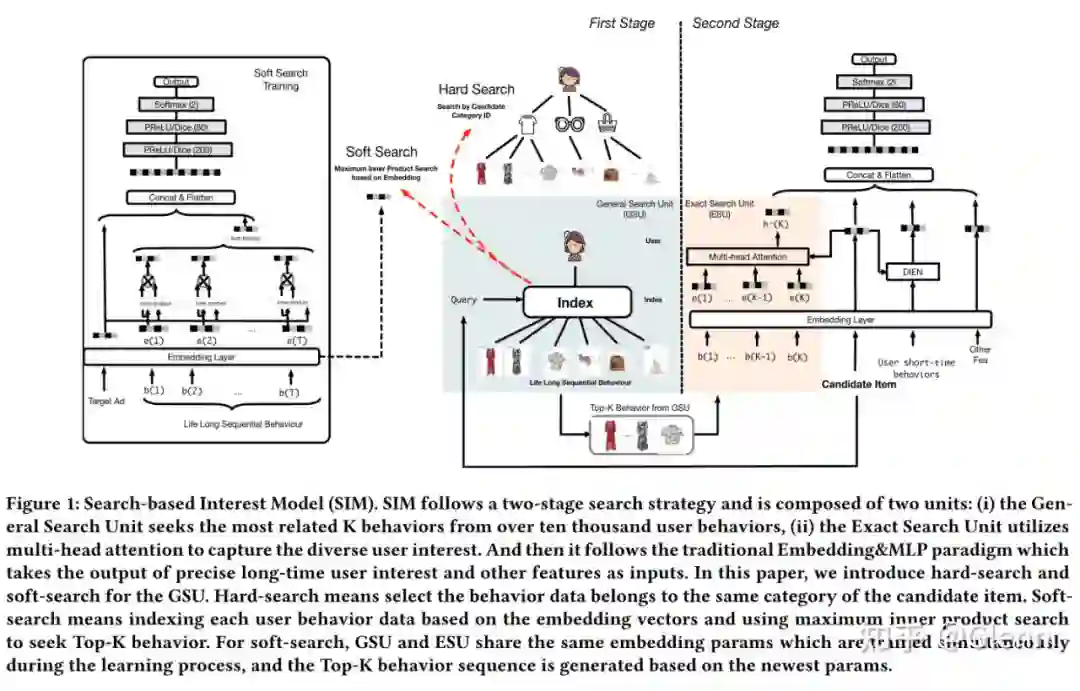
SIM [12][13]
5.1 简介
MIMN 虽然通过计算分离的方式确保了时延方面无压力,但也带来了
更新频率不一致,行为序列无法与候选 AD 更好的交互 等问题。线上使用时,作者发现当
序列长度超过 1k 时,MIMN 效果会变差 (也是因为无法与候选 AD 交互)。
基于这些问题,作者干脆直接模仿推荐系统多阶段过滤的方法,第一阶段通过相对粗略的搜索模式,提取行为序列中与候选 AD 较相关的节点,第二阶段通过精准搜索的模式,得到序列与候选 AD 的关系,并形成 embedding 供 MLP 使用。这个模型能吃下的最大序列长度为 54000,能满足工业界提取长期用户兴趣的需求
5.2 泛搜索结构(第一阶段)
如上图左侧所示,作者的重点是提取长期行为中(短期的默认全取,论文的工业数据集中短期指 14 天内的行为),与候选商品相关的行为节点。作者提出两种匹配
方法:
1. Hard Search:核心思想是只提取和候选商品相同类目的行为信息。具体的,在线维护一个“用户 ID -商品类目 ID -行为商品 ID”的双层索引数据。请求到来时,直接检索对应类目的行为商品序列。
2. Soft Search:通过类似 ANN 的商品召回结构,获取与候选商品相关的行为节点。
Serving 阶段:假设行为序列为
,候选 AD 的 embedding 为
,则基于 dot-product + 近邻搜索(ALSH)的方式(
),得到最相关的 Top K 个长期行为。
模型训练阶段:通过采样的方式得到若干行为,通过加权 sum-pooling 的方法得到行为 embedding(
),与目标 AD 的 embedding 拼接后送入 MLP 训练 CTR 模型,得到行为的 embedding 结果。
实际业务中,发现两种搜索模式的效果并没有太大差异,而性能上,明显 Hard Search 更有优势,因此线上采用 Hard Search(存储消耗 22TB。。。)
5.3 精准搜索结构(第二阶段)
该阶段,模型的输入分为 4 部分,用户画像,候选商品,短期行为序列和筛选出的长期行为序列(
),短期行为序列的信息提取采用 DIEN 的结构。而筛选的长期行为序列
,因为行为发生时间与当前有一定距离,作者单独使用的 attention 结构去提取特征。 作者引入行为发生时间与当前时刻的时间差信息
,并编码成 embedding(
),与行为序列的 embedding(
)做拼接,作为长期行为节点的 embedding(
)。然后利用 multi-head attention 的机制提取 emebdding 特征送入 MLP,即
整体的 Loss 为两阶段 loss 的加权和(第一阶段采用 hard search 时
,否则
)
5.4 优缺点
1. 从实验看,SIM 基本能满足工业界对用户长期兴趣提取的要求,对比 DIEN,模型在对长期兴趣的提取效果是显著的。如下左图,横坐标表示的是用户当前时刻点击了某类别商品与上一次点击该类别商品的时间差,曲线表示样本分布情况,可以看到点击样本的
基本在 14 天以内。直方图表示对比 DIEN,SIM 的 AUC 提升情况,可以看到对于命中长期兴趣的点击样本,SIM 的效果远优于 DIEN。
2. 时延方面,SIM 因为要处理 1w+ 的序列信息,性能比 MIMN 要弱一些,但18ms的时延也基本满足实时性的要求。
3. SIM 号称能够处理的序列长度是 54000,对于阿里广告业务而言,相当于 180 天的广告行为,已基本覆盖用户长期兴趣建模所需的时间长度。
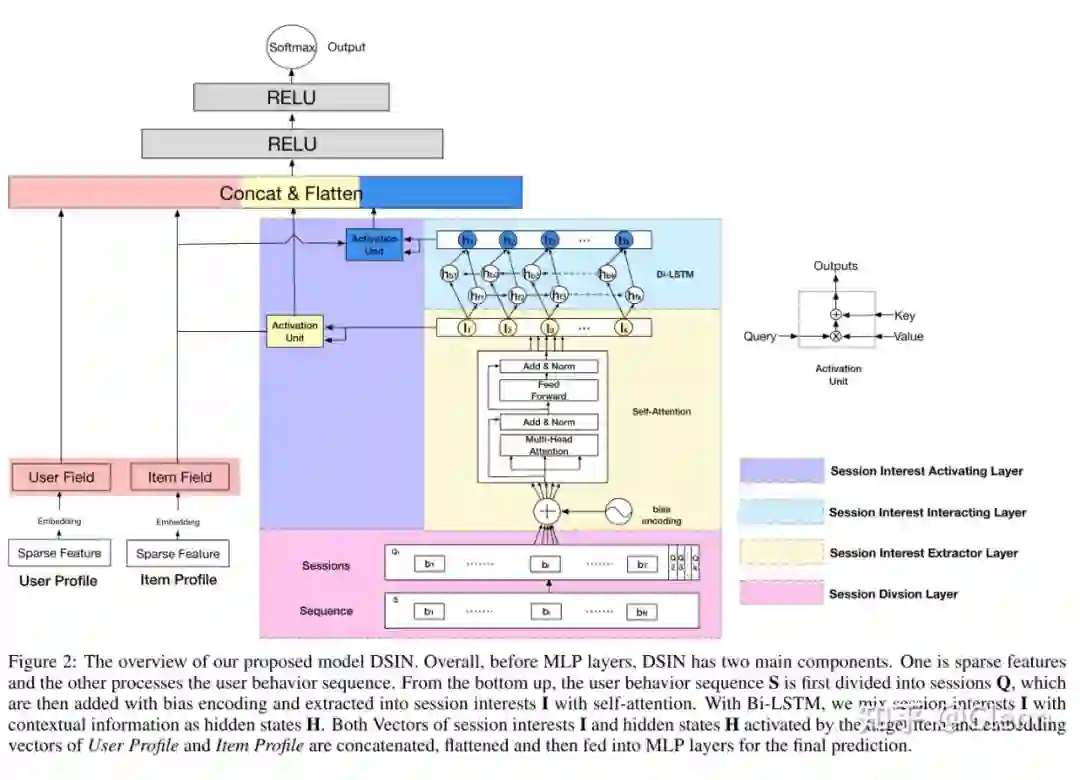
DSIN [14][15]
6.1 动机的目标
这篇论文没有从提取长期行为的角度出发,而是在时间间隔上做文章。DIEN 直接将 14 天的行为无差别的拼接,没有考虑 session 的概念,但是用户的行为,在不同的 Session 中有明显差异。如下图,作者将行为间隔不超过 30min 的部分归纳为一个 session,发现,同一个 session 内,用户点击的商品具有明显的指向性,而不同 session 间,用户的点击行为有明显差异。
6.2 创新点
针对这一现象,作者将行为划分为多个 session,并提出兴趣抽取、兴趣交互(序列)、兴趣激活层 3 部分。
1. 兴趣抽取(Session Inerest Extractor Layer)
该部分作者使用 transformer 的结果,首先引入了 bias-encoding(会对每个 session,每个行为节点的位置,每个 embedding-bit 位构建全局共享的 embedding),即
其中,K 是 session 的个数,T 是每个 session 内行为节点的个数,C 是每个行为节点的 embedding 大小。
则 transformer 的输入为行为序列与 bias-encoding 的相加结果,即
。
接着通过 multi-head self-attention 的机制,得到多个兴趣结果(
)。
2. 兴趣交互(Session Inerest Interacting Layer)
该层作者提出通过 Bi-LSTM 的结构提取兴趣序列信息,
。
3. 兴趣激活(Session Inerest Activating Layer)
借鉴 DIN、DIEN 的思想,将兴趣、序列信息分别和目标 AD 做 Attention,加权求和后得到 MLP 的输入,即
后记
本文回顾了阿里妈妈,精排阶段-用户兴趣模型的发展过程,GWEN->DIN->DIEN->MIMN->SIM->DSIN
[16][17]
。这一系列的变动,从无用户行为输入,到提取多峰兴趣,再到短期行为特征,最后长短期兴趣提取。基本上,模型也能满足业界对兴趣建模的大部分需求。
但实际应用中,SIM 的检索树要吃 22TB 内存,MIMN 整个模型结构和上线方案都比较复杂(不太优雅)。用户兴趣的提取,除了直接将行为序列灌入模型,是否还有别的补充方法,比如在画像建模时,就直接构建 [时间窗 X 类 目 X 行为类型 X 强度] 的商品类目兴趣。虽然从模型的角度看,这种建模会削弱候选 AD 与行为节点的交互,但也能在一定程度补充用户兴趣特征的缺失,同时长期兴趣的构建通过这种模式也会比较稳定。
当前模型仅处理广告点击序列的信息,如果同时考虑用户浏览、加购物车、与商家是否有沟通、其他组件的点击等行为,序列将非常长且多样化,是否还可以设计新的模型进一步优化(或者离线画像帮忙分担,特别是长期兴趣部分)。
[1] DataFunTalk:阿里新一代Rank技术 https://zhuanlan.zhihu.com/p/442477196
[2] 新智元:【阿里算法天才盖坤】解读阿里深度学习实践,CTR 预估、MLR 模型、兴趣分布网络等 https://zhuanlan.zhihu.com/p/35599271
[3] DIN论文 https://arxiv.org/pdf/1706.06978.pdf
[4] 王喆:推荐系统中的注意力机制——阿里深度兴趣网络(DIN) https://zhuanlan.zhihu.com/p/51623339
[5] DIEN 论文 https://arxiv.org/pdf/1809.03672.pdf
[6] yymWater:详解阿里之Deep Interest Evolution Network(AAAI 2019) https://zhuanlan.zhihu.com/p/50758485
[7] Evan:深入理解lstm及其变种gru https://zhuanlan.zhihu.com/p/34203833
[8] MIMN 论文 https://arxiv.org/pdf/1905.09248.pdf
[9] 被包养的程序猿丶:阿里妈妈长期用户历史行为建模——MIMN模型详解 https://zhuanlan.zhihu.com/p/94432395
[10] 呜呜哈:记忆网络之Neural Turing Machines https://zhuanlan.zhihu.com/p/30383994
[11] 徐阿衡:论文笔记 - 从神经图灵机 NTM 到可微分神经计算机 DNC https://zhuanlan.zhihu.com/p/33852794
[12] SIM 论文 https://arxiv.org/pdf/2006.05639.pdf
[13] 梦醒潇湘:[SIM论文] 超长兴趣建模视角CTR预估:Search-based Interest Model https://zhuanlan.zhihu.com/p/154401513
[14] DSIN 论文 https://arxiv.org/pdf/1905.06482.pdf
[15] Ethan Wong:DSIN(Deep Session Interest Network )分享 https://zhuanlan.zhihu.com/p/89700141
[16] kylin:深度兴趣网络DIN-DIEN-DSIN https://zhuanlan.zhihu.com/p/101541576
[17] 小范同学:推荐系统CTR预估:用户兴趣建模 https://zhuanlan.zhihu.com/p/416350009
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读 ,也可以是学术热点剖析 、科研心得 或竞赛经验讲解 等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品 ,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬 ,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱: hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02 )快速投稿,备注:姓名-投稿
△长按添加PaperWeekly小编
🔍
现在,在「知乎」 也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」 订阅我们的专栏吧