【ICML2020】基于模型的强化学习方法教程,279页ppt
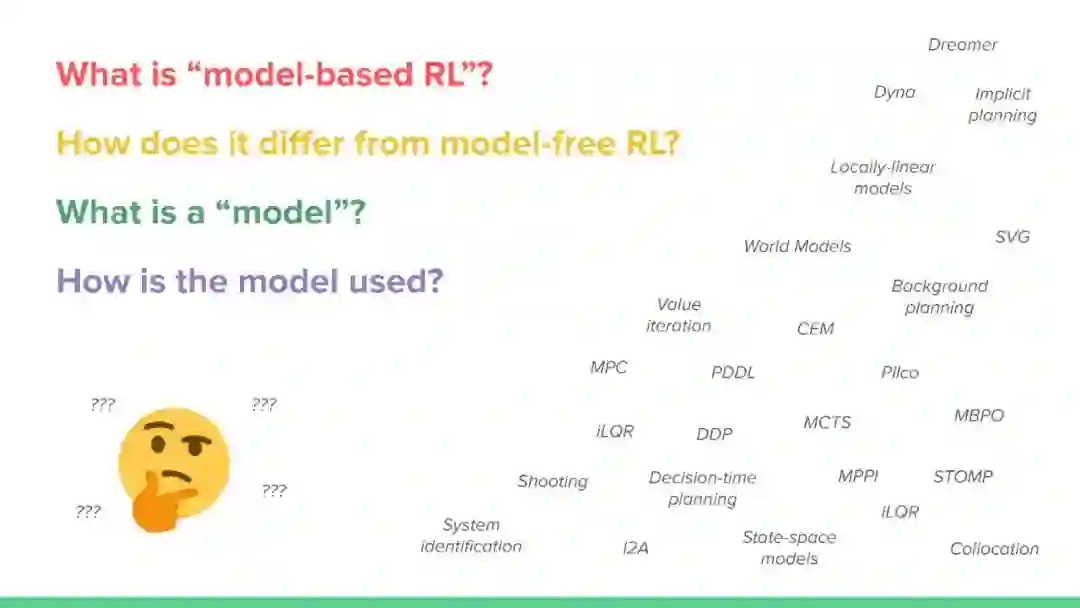
本教程对基于模型的强化学习(MBRL)领域进行了广泛的概述,特别强调了深度方法。MBRL方法利用环境模型来进行决策——而不是将环境视为一个黑箱——并且提供了超越无模型RL的独特机会和挑战。我们将讨论学习过渡和奖励模式的方法,如何有效地使用这些模式来做出更好的决策,以及规划和学习之间的关系。我们还强调了在典型的RL设置之外利用世界模型的方式,以及在设计未来的MBRL系统时,从人类认知中可以得到什么启示。

https://sites.google.com/view/mbrl-tutorial
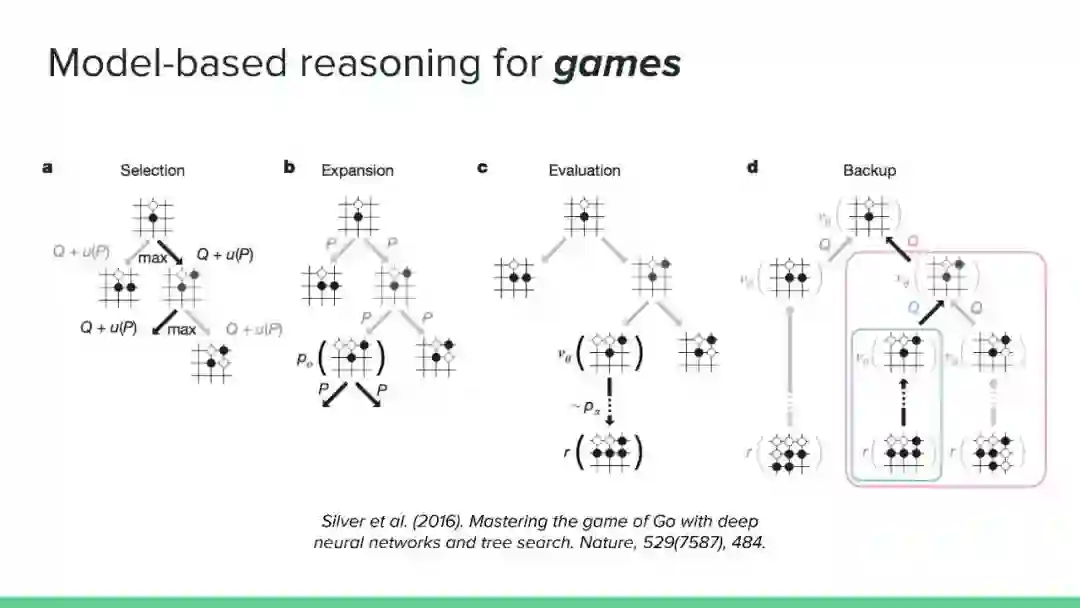
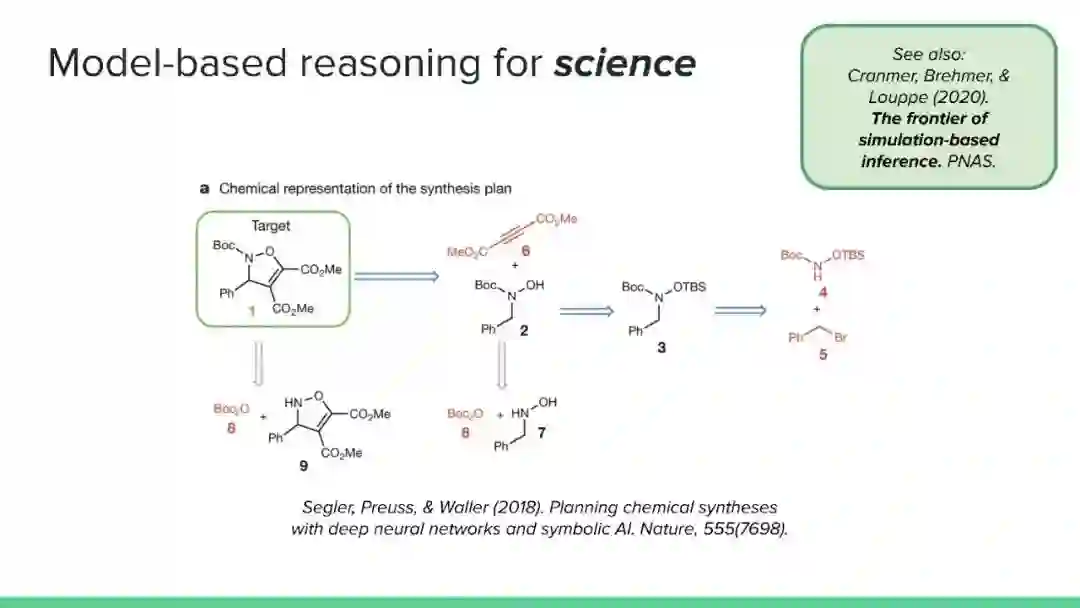
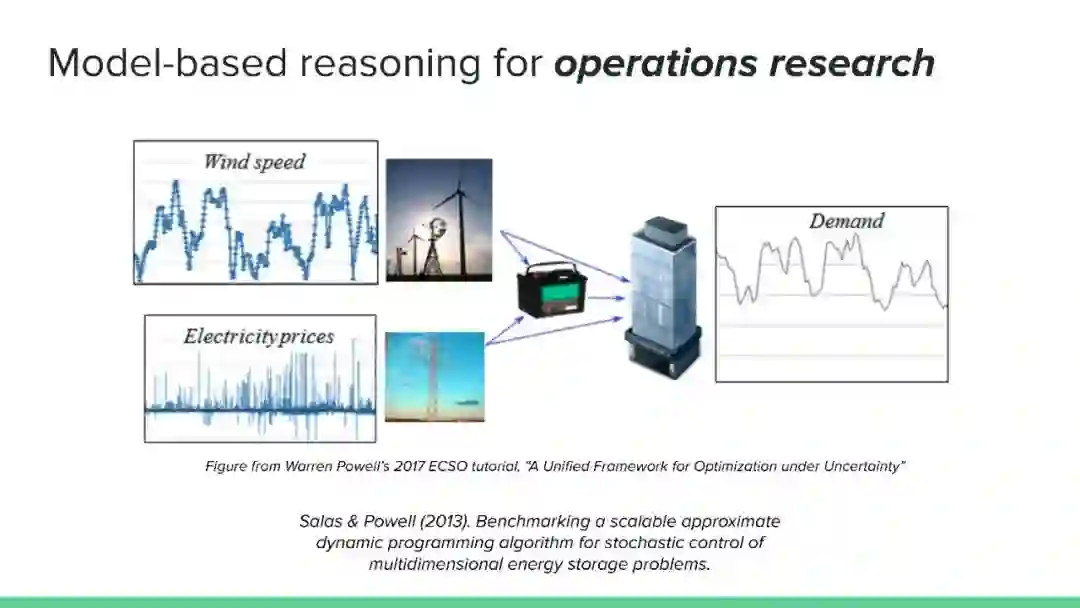
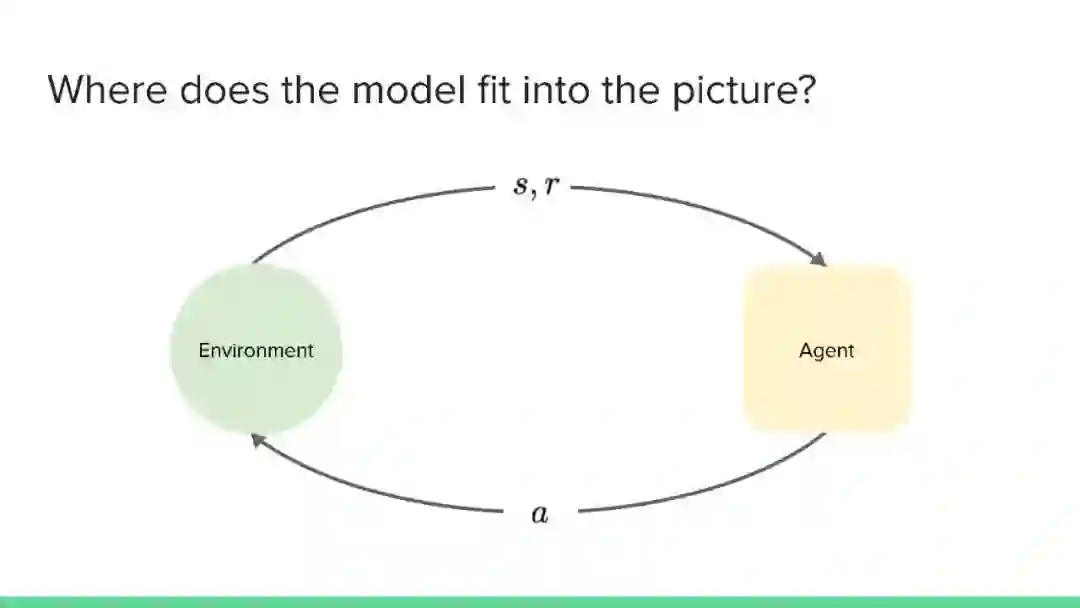
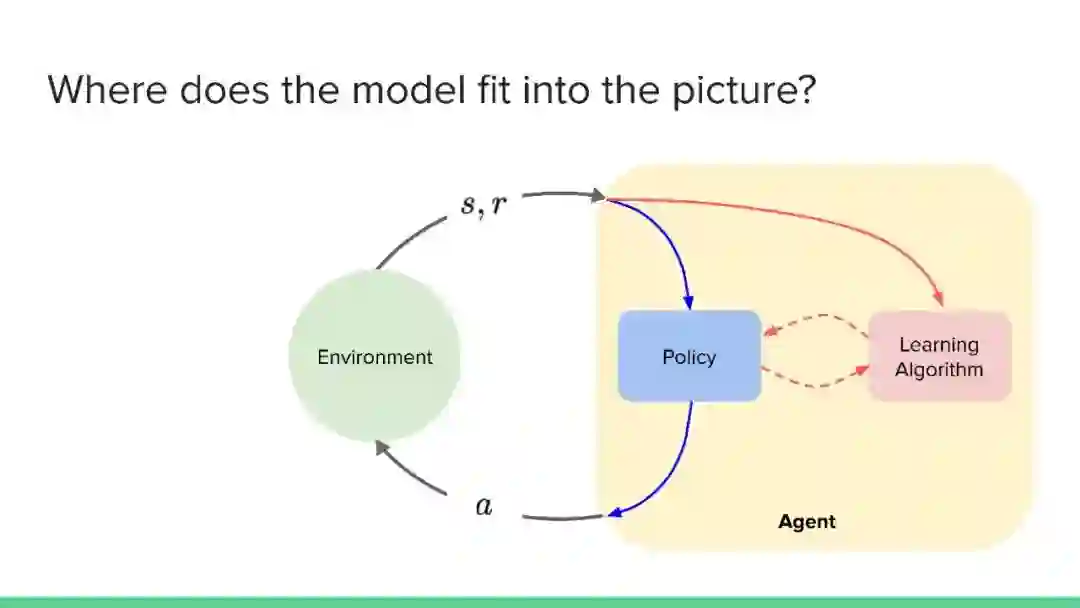
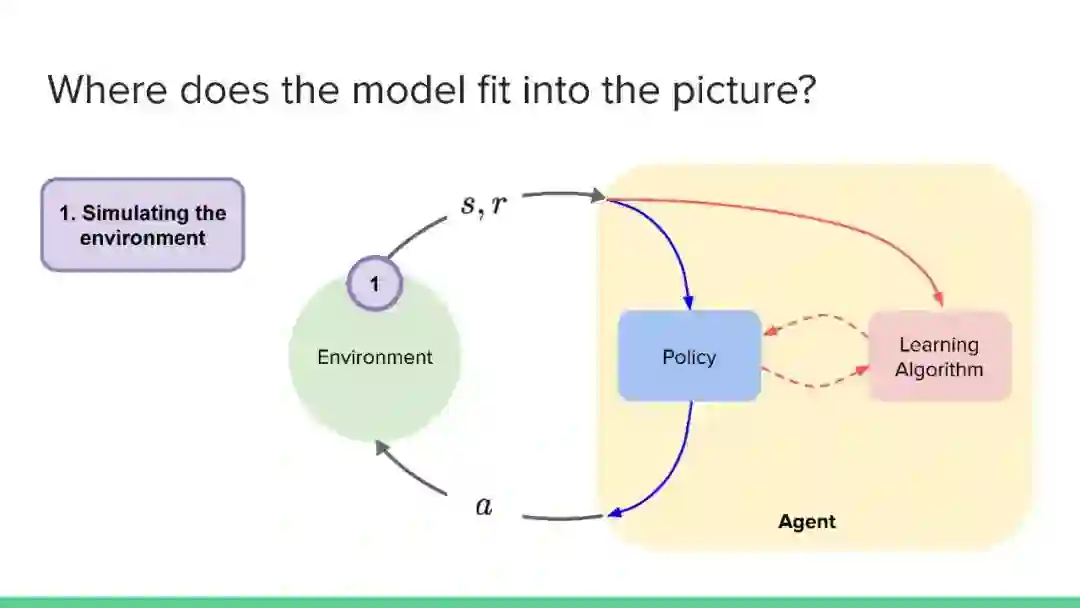
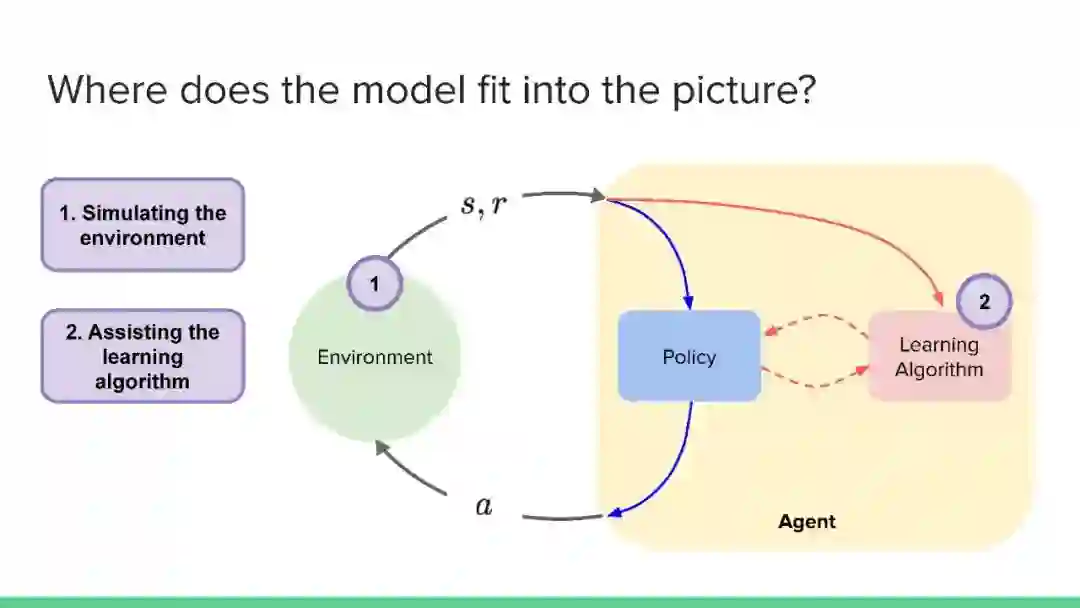
近年来,强化学习领域取得了令人印象深刻的成果,但主要集中在无模型方法上。然而,社区认识到纯无模型方法的局限性,从高样本复杂性、需要对不安全的结果进行抽样,到稳定性和再现性问题。相比之下,尽管基于模型的方法在机器人、工程、认知和神经科学等领域具有很大的影响力,但在机器学习社区中,这些方法的开发还不够充分(但发展迅速)。它们提供了一系列独特的优势和挑战,以及互补的数学工具。本教程的目的是使基于模型的方法更被机器学习社区所认可和接受。鉴于最近基于模型的规划的成功应用,如AlphaGo,我们认为对这一主题的全面理解是非常及时的需求。在教程结束时,观众应该获得:
数学背景,阅读并跟进相关文献。
对所涉及的算法有直观的理解(并能够访问他们可以使用和试验的轻量级示例代码)。
在应用基于模型的方法时所涉及到的权衡和挑战。
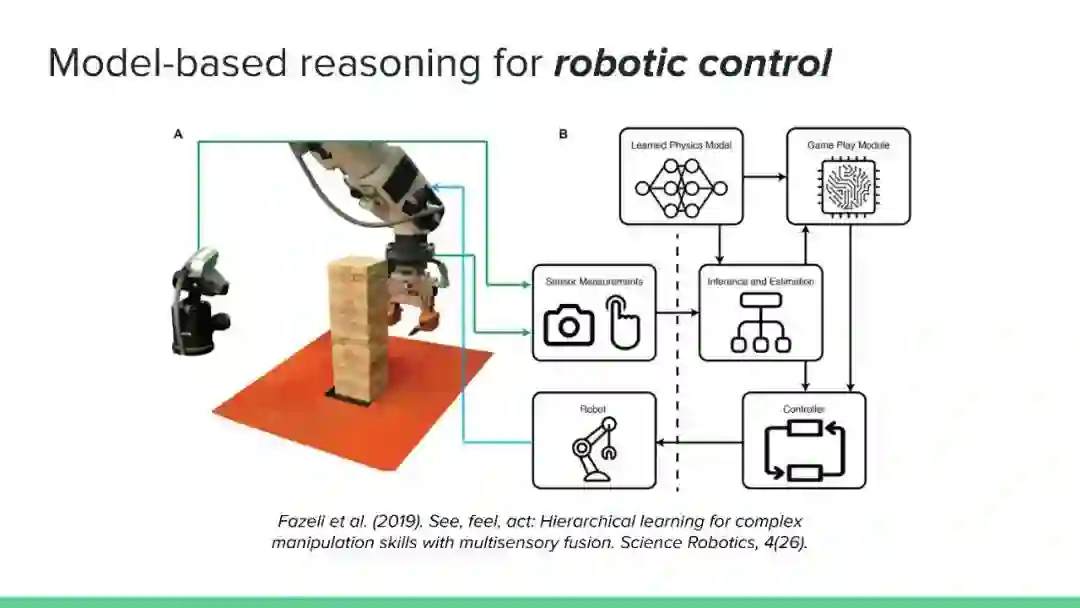
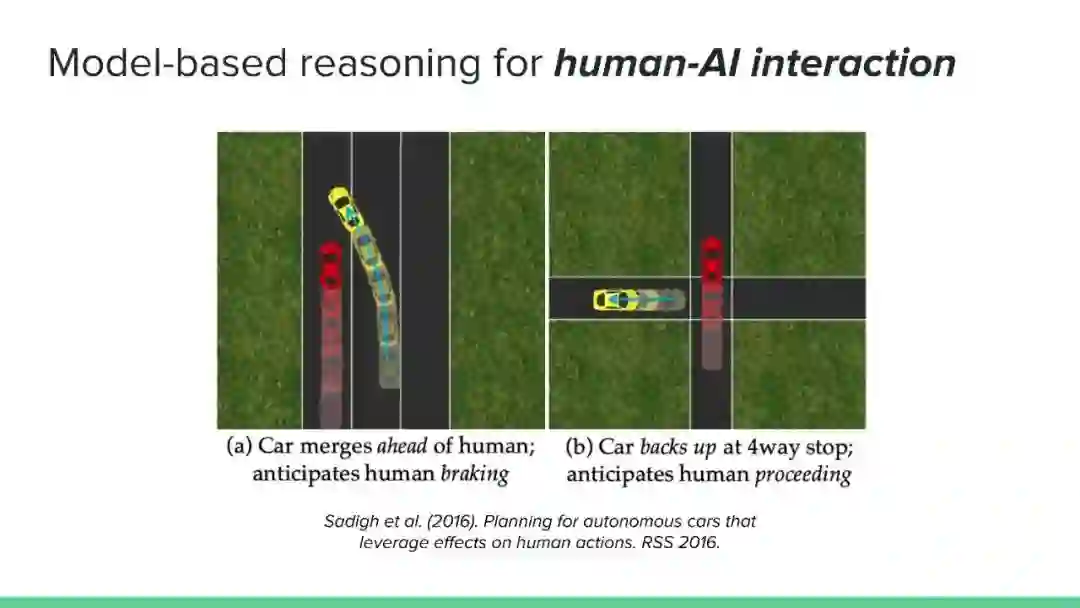
对可以应用基于模型的推理的问题的多样性的认识。
理解这些方法如何适应更广泛的强化学习和决策理论,以及与无模型方法的关系。











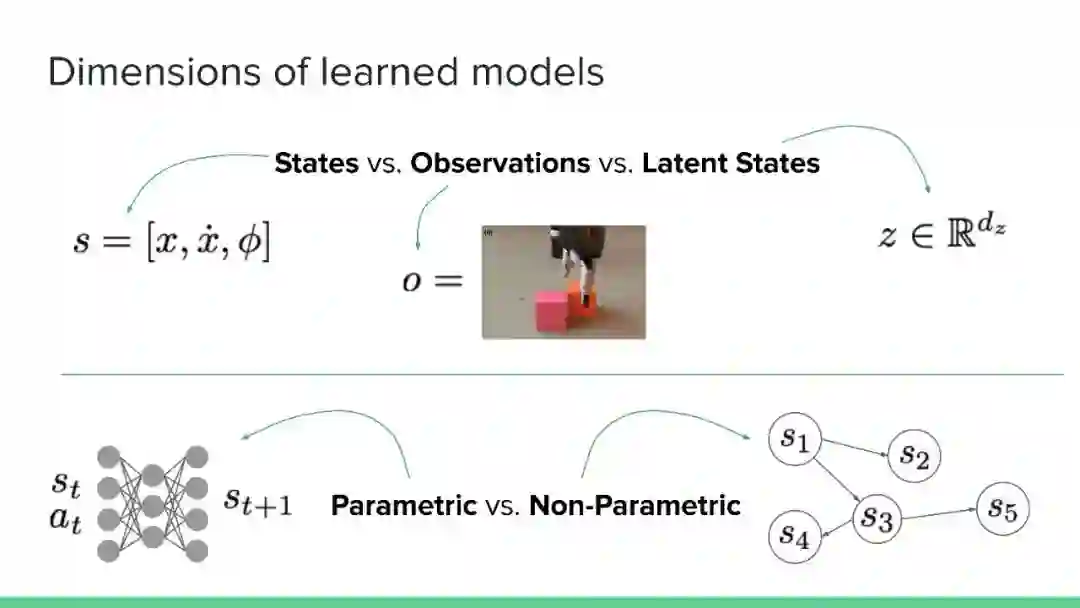
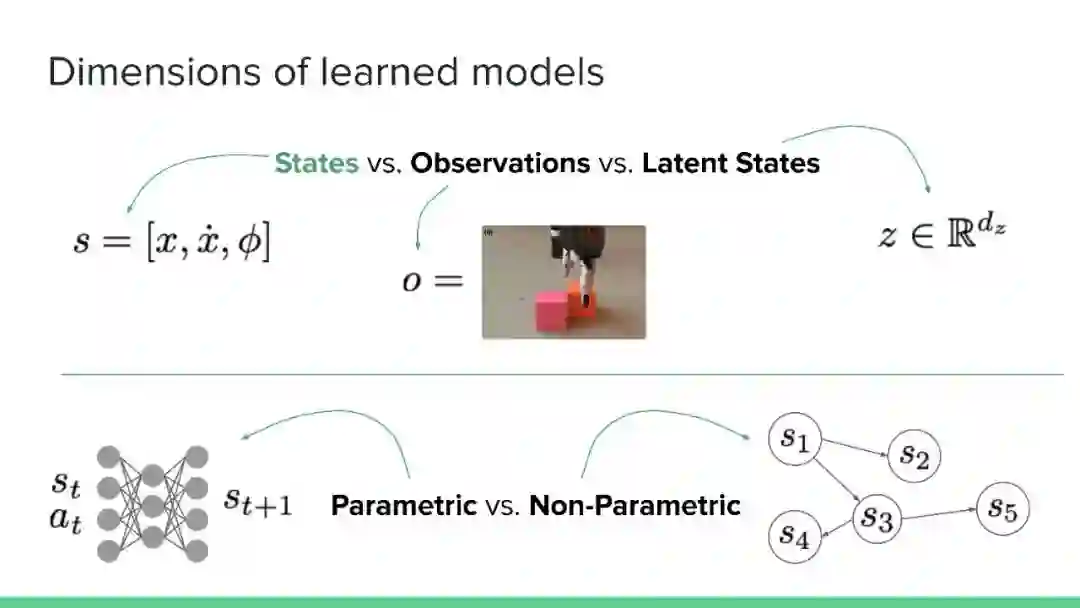


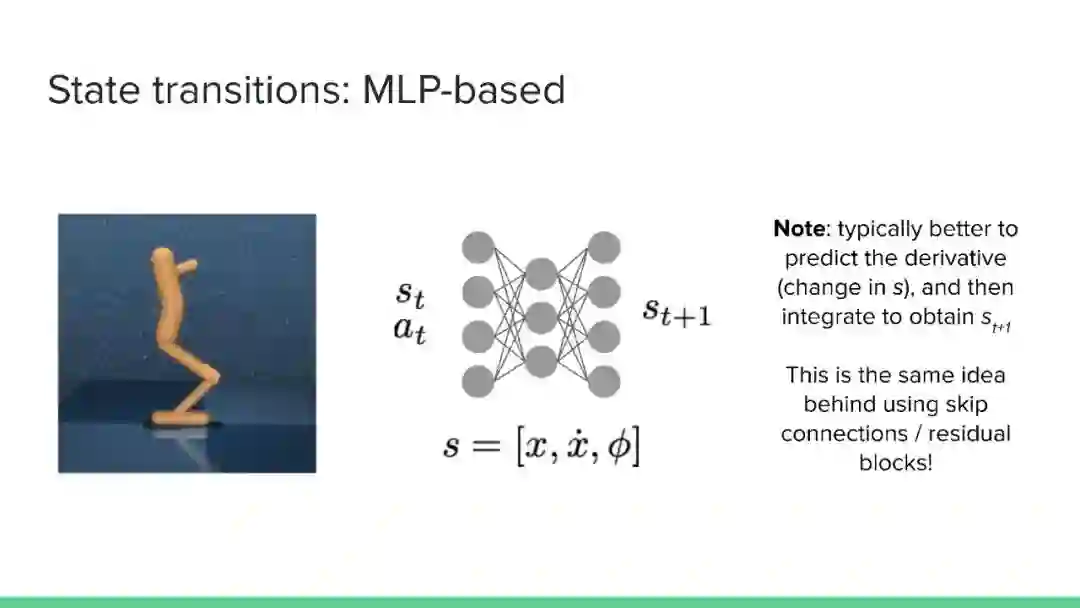
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“MBRL” 可以获取《【ICML2020】基于模型的强化学习方法教程,279页ppt》专知下载链接索引



登录查看更多
相关内容



相关VIP内容
相关资讯
相关论文