杨强:应对对抗攻击、结合AutoML,是联邦学习接下来的研究重点| CCF-GAIR 2020

作者 | 丛末
1
联邦学习研究背景
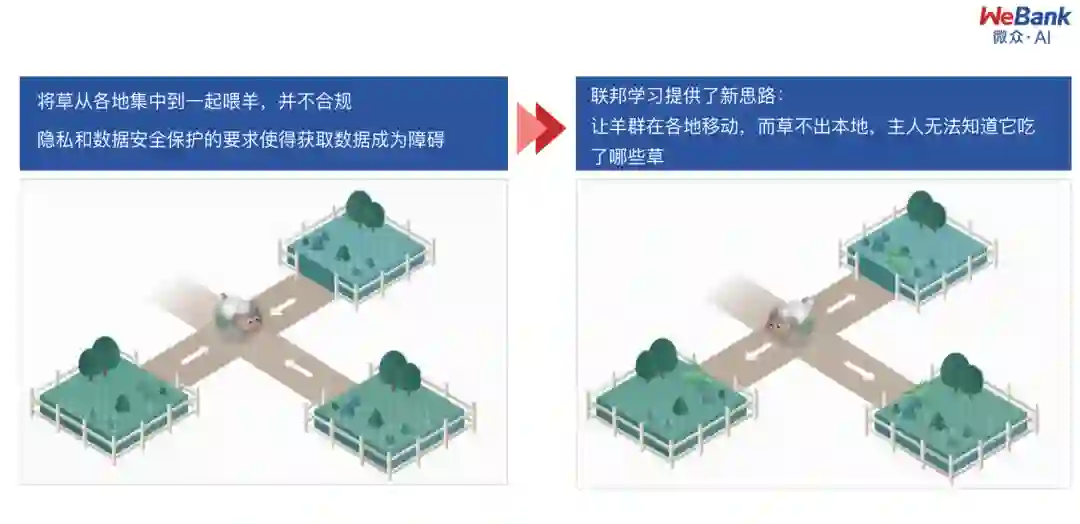
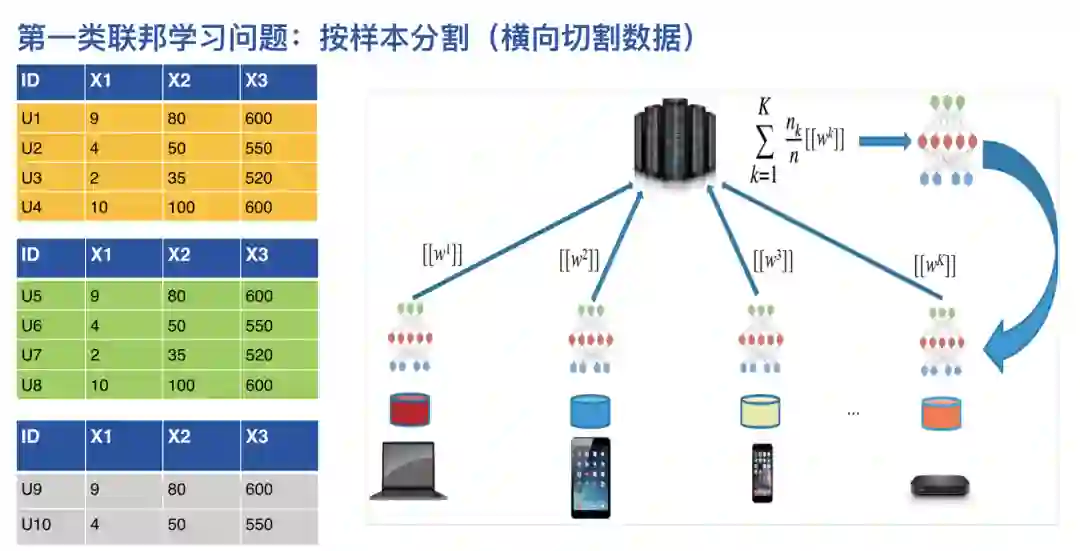
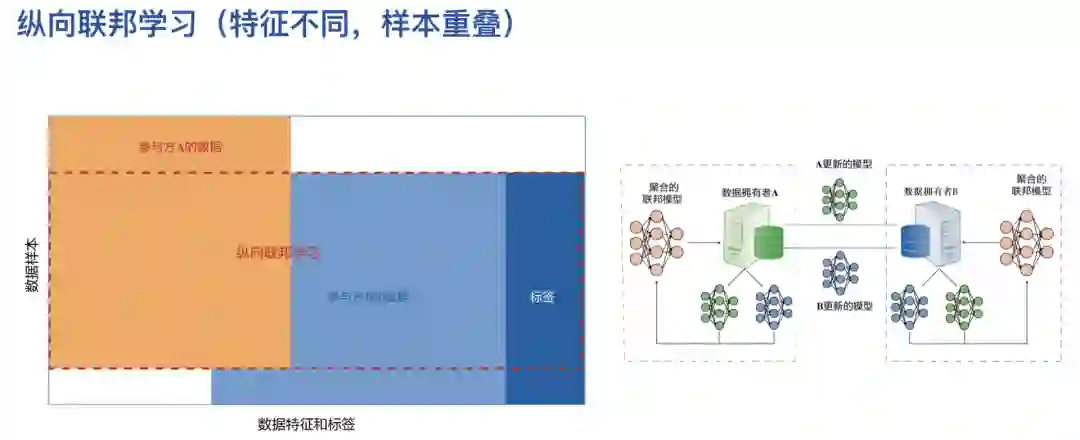
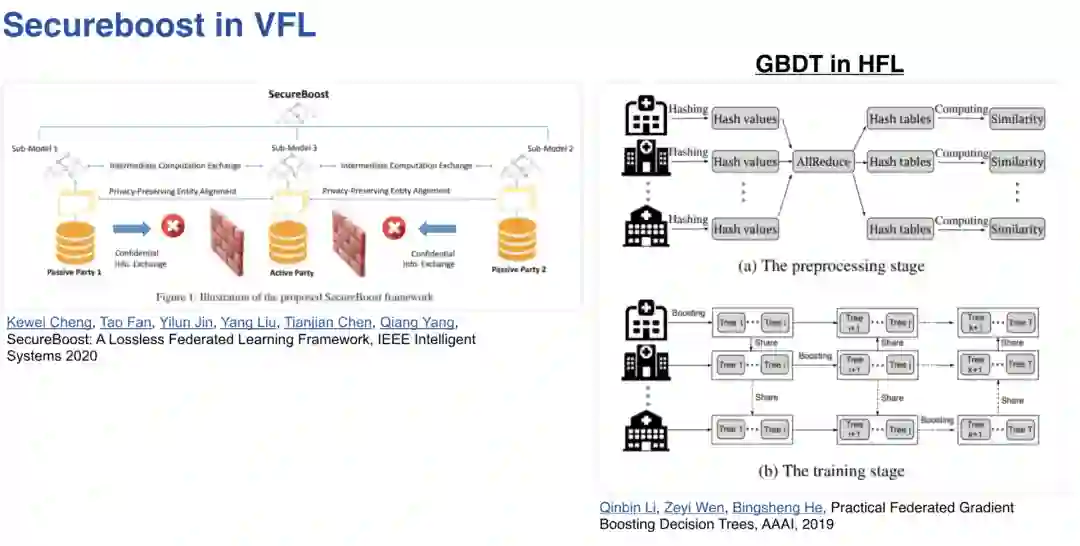
首先看一下联邦学习的研究背景。


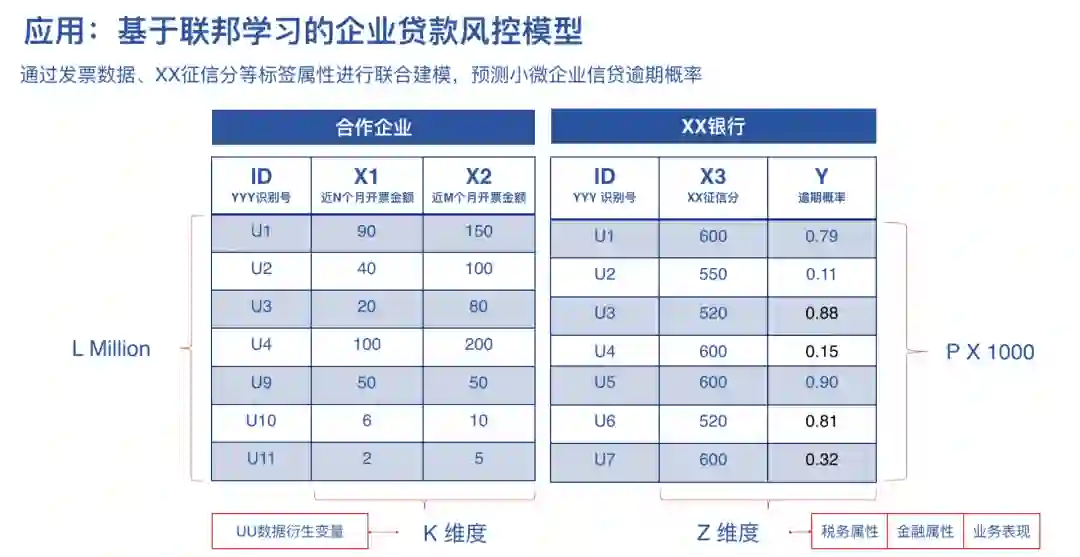
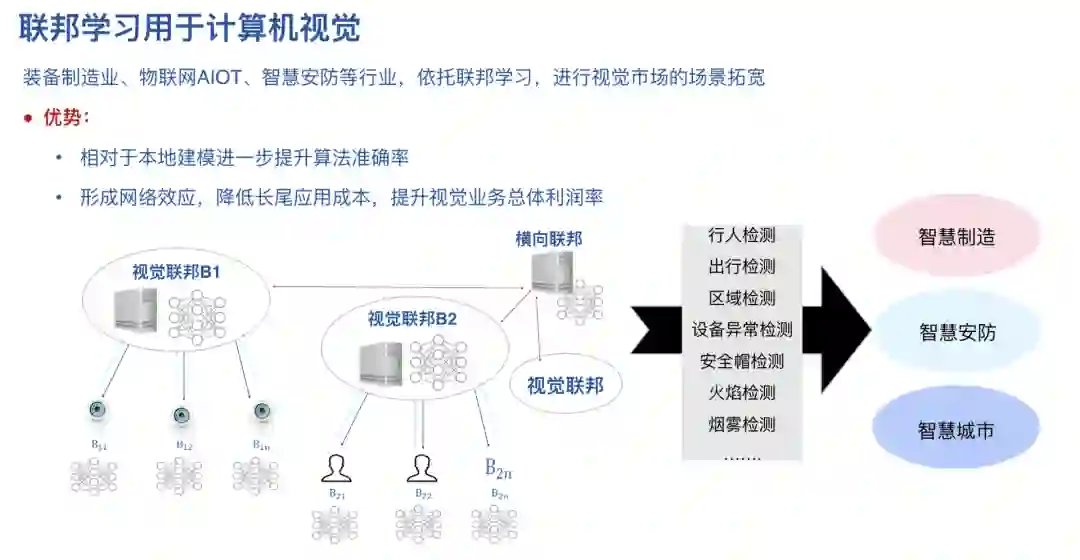
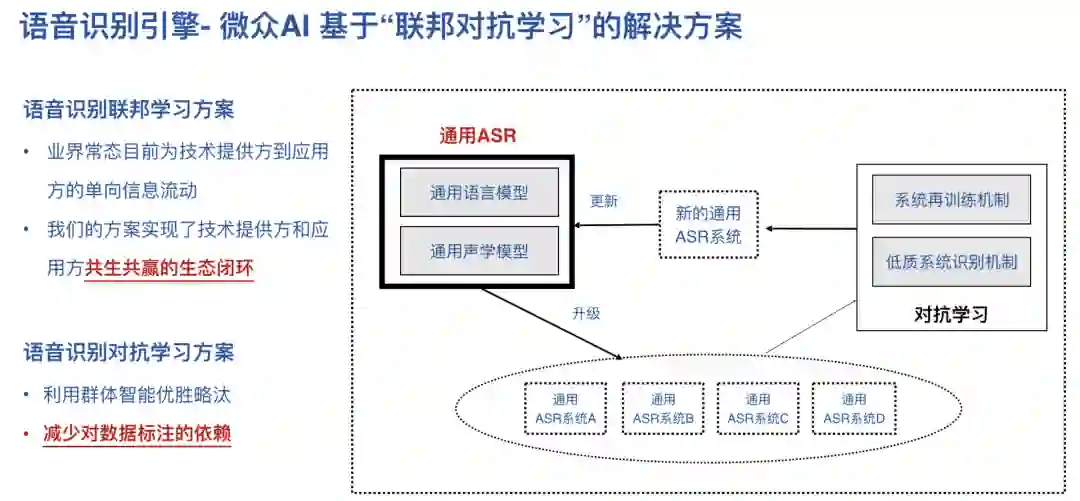
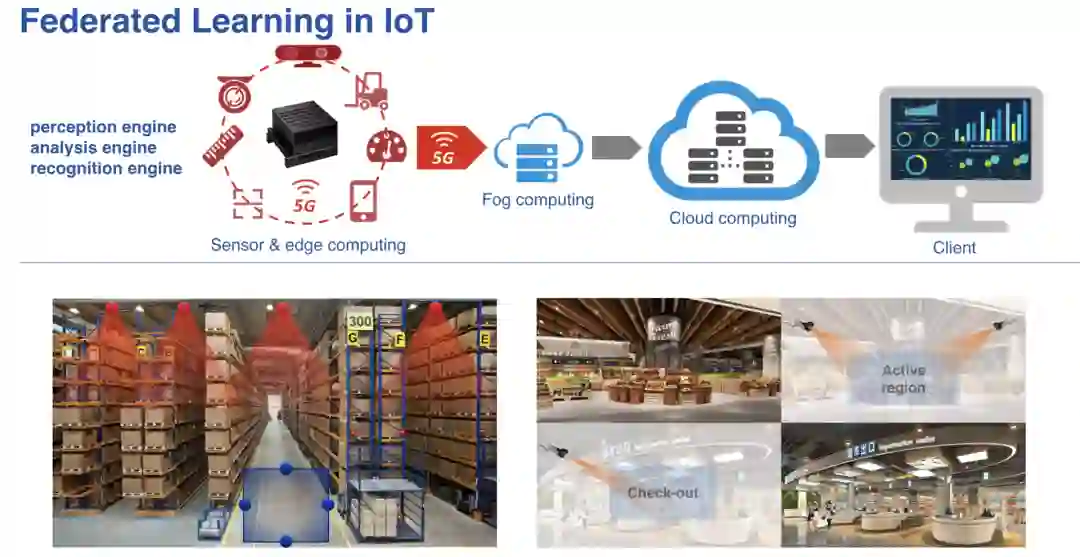
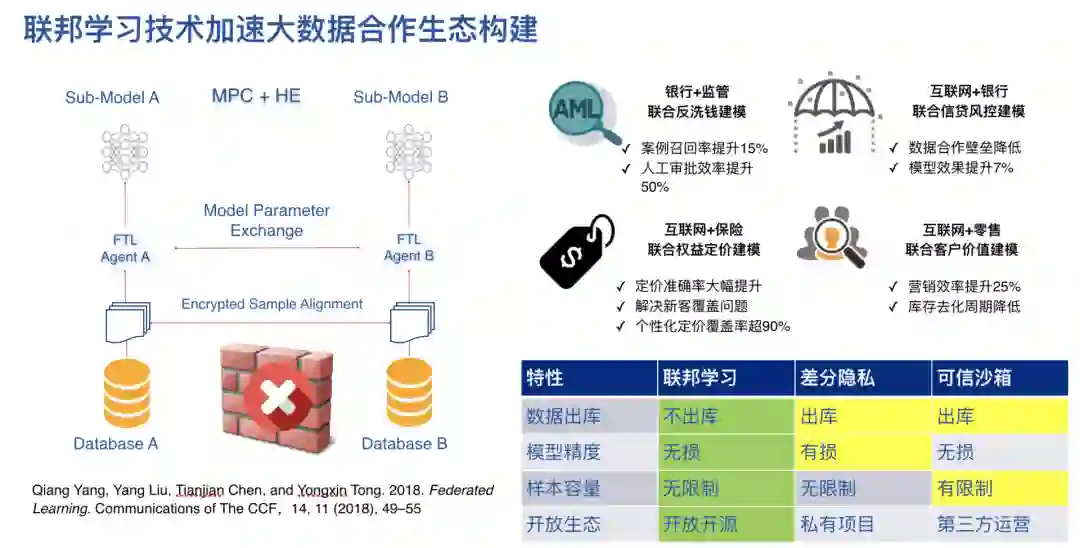
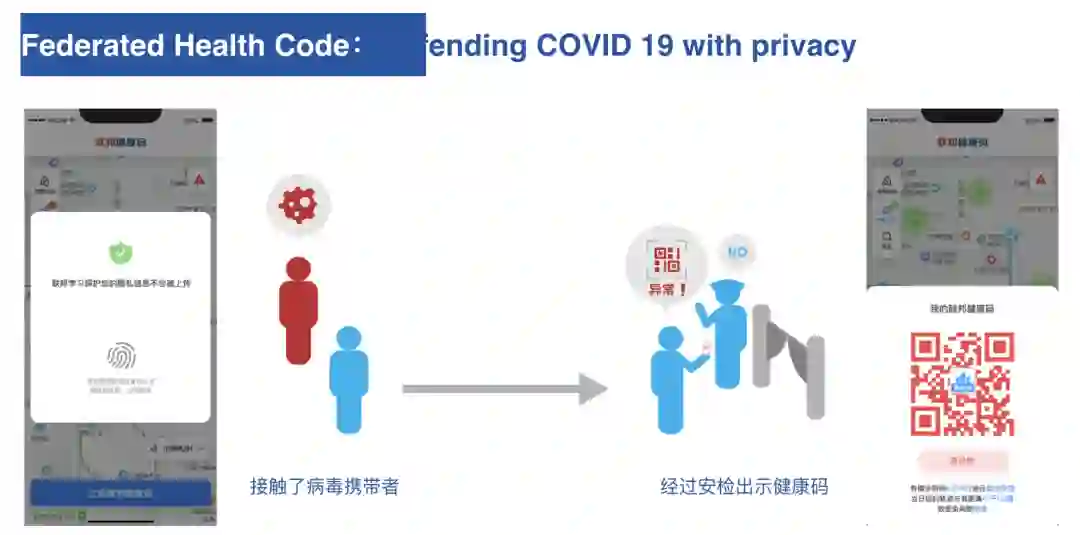
4
联邦学习和迁移学习的结合研究
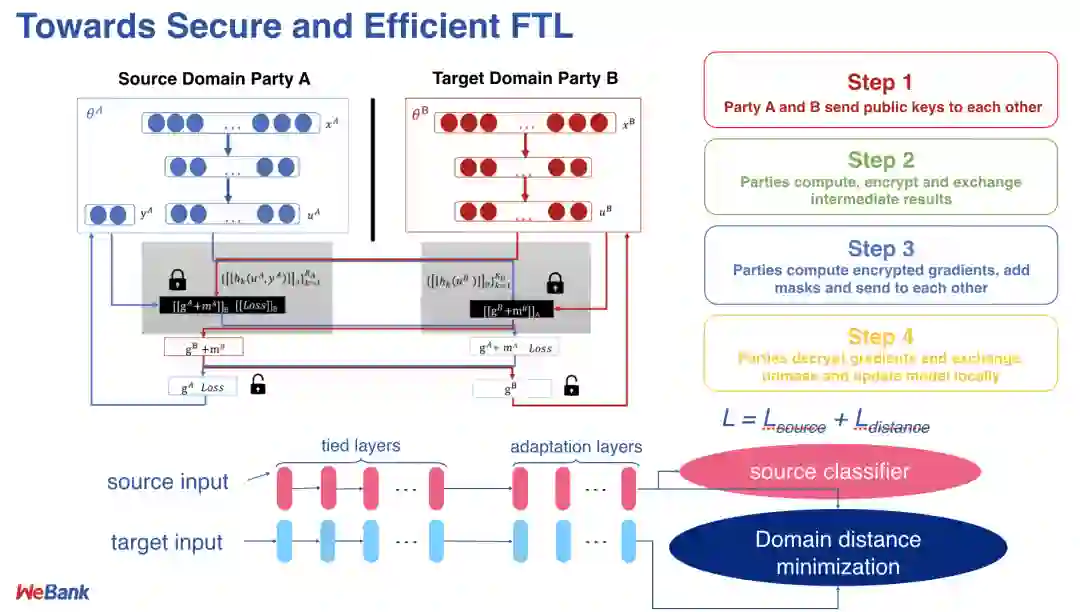
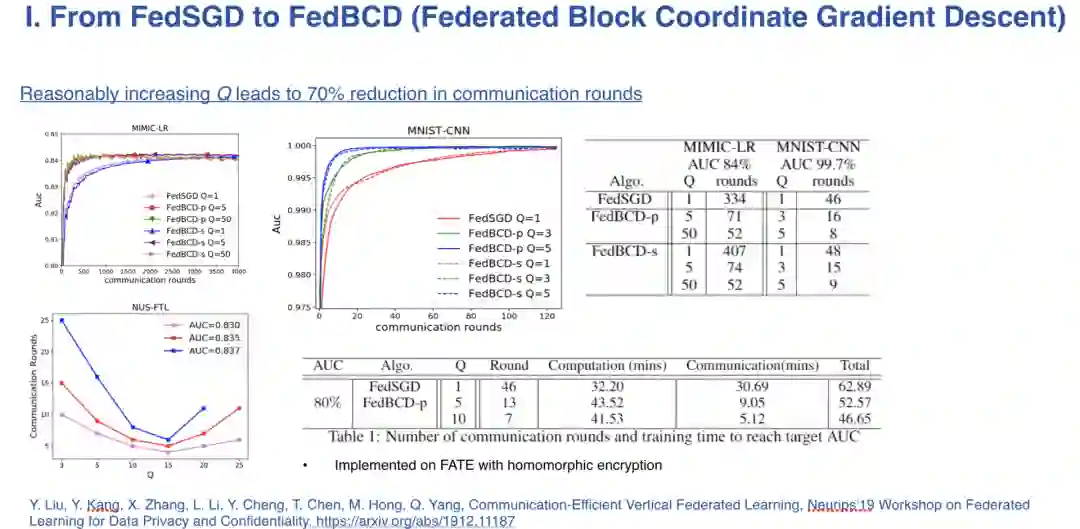
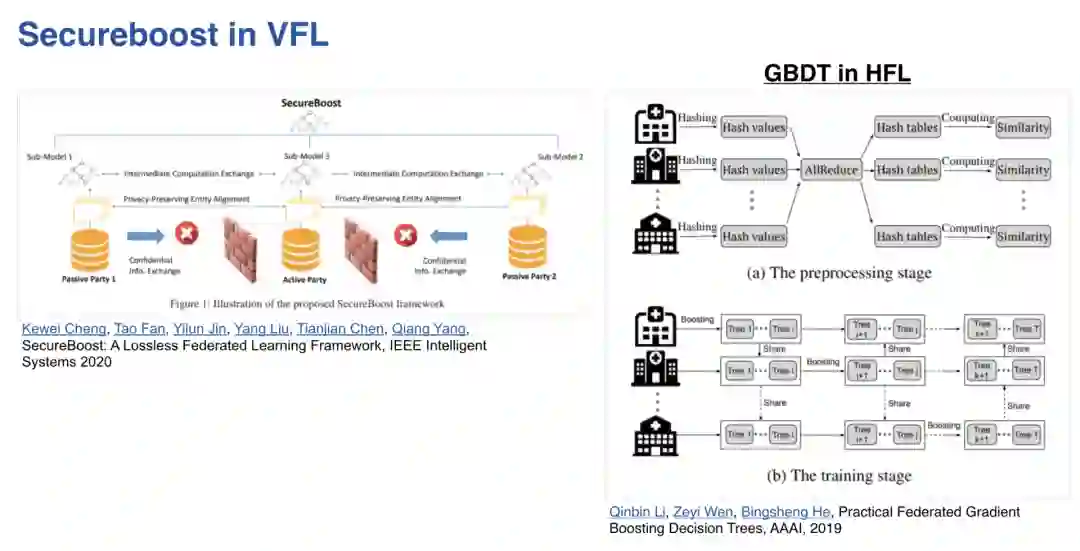

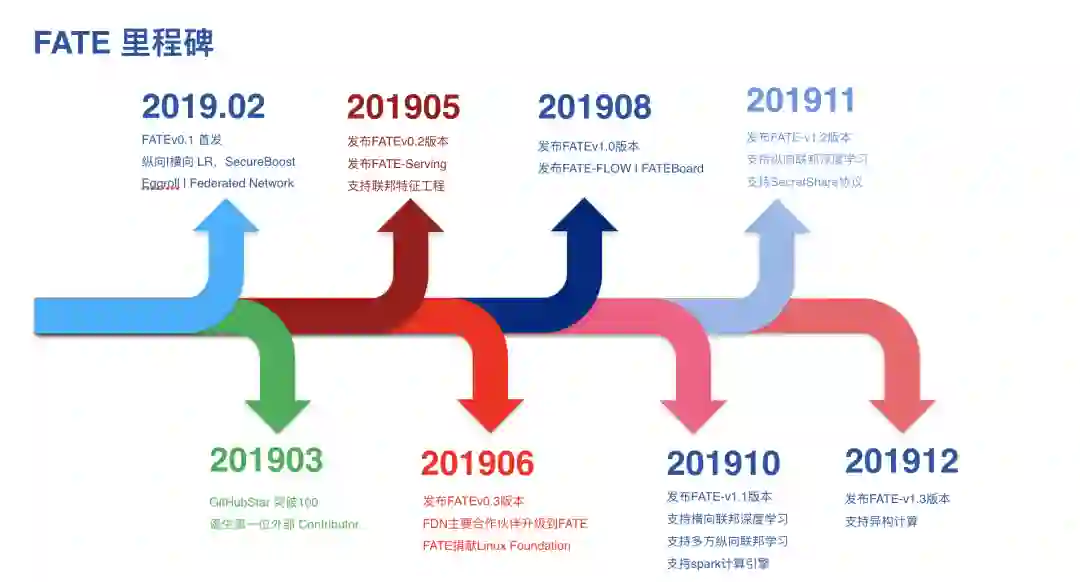
5
联邦学习接下来的重点研究方向
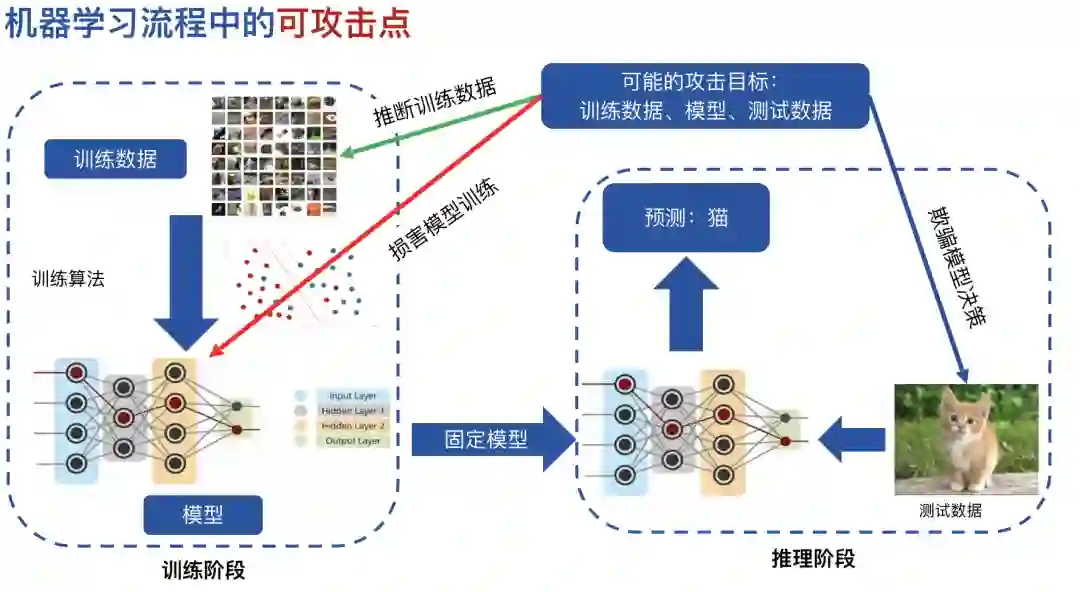
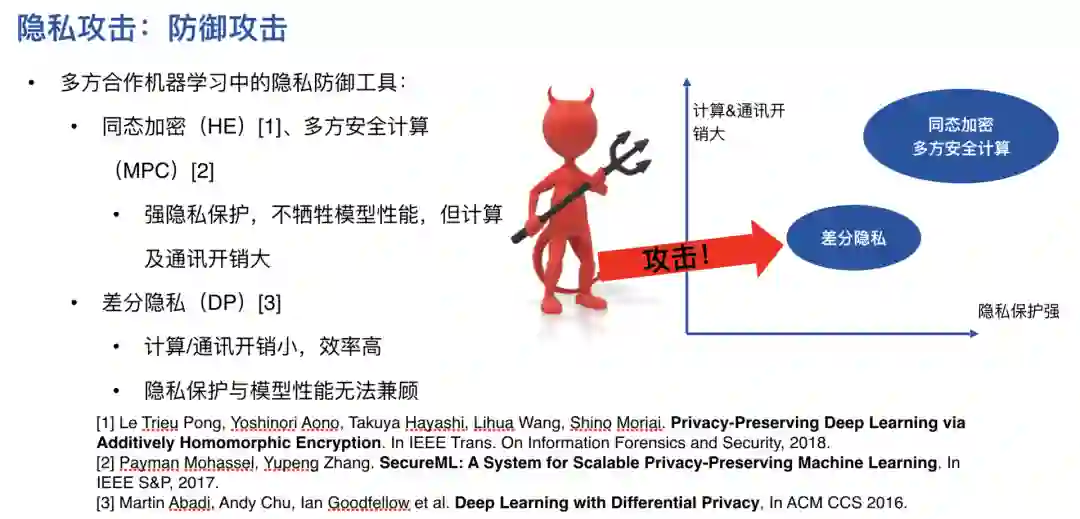



登录查看更多
相关内容



相关VIP内容
相关资讯
相关论文