清华提出首个退化可感知的展开式Transformer|NeurIPS 2022

新智元报道
新智元报道
【新智元导读】NeurIPS 2022关于Specral Compressive Imaging (SCI)重建的工作。
本文介绍我们 NeurIPS 2022 关于 Spectral Compressive Imaging (SCI)重建的工作:
《Degradation-Aware Unfolding Half-Shuffle Transformer for Spectral Compressive Imaging》

文章:https://arxiv.org/abs/2205.10102
单曝光快照压缩成像(Snapshot Compressive Imaging,SCI)的任务是将一个三维的数据立方块如视频(H×W×T)或高光谱图像(H×W×λ)通过预先设计好的光学系统压缩成一个二维的快照估计图(H×W)从而大幅度地降低数据存储和传输的开销。
常见的单曝光快照压缩成像系统有 Coded Aperture Snapshot Spectral Compressive Imaging (CASSI),如下图所示:
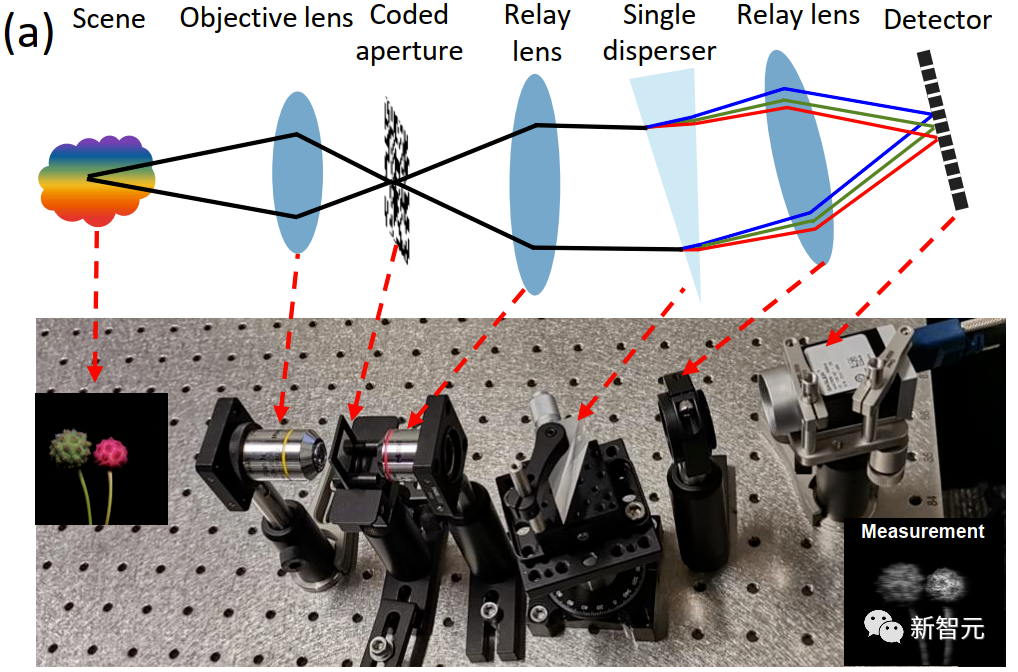
那么在 SCI 中一个至关重要的问题就是如何从被压缩过后的二维快照估计图重建出原始的三维数据,当前主流的方法大都基于深度学习,可以分为两类:端到端(End-to-end)的方法和深度展开式(Deep Unfolding)的方法。
端到端的方法直接采用一个深度学习模型,去拟合一个从 2D 快照压缩估计图到 3D 高光谱数据的映射。这种方法比较暴力,确实可解释性。
-
当前的深度展开式框架大都没有从 CASSI 中估计出信息参数用于引导后续的迭代,而是直接简单地将这些所需要的参数设置为常数或者可学习参数。这就导致后续的迭代学习缺乏蕴含 CASSI 退化模式和病态度信息指导。 -
当前的Transformer 中全局的 Transformer 计算复杂度与输入的图像尺寸的平方成正比,导致其计算开销非常大。而局部 Transformer 的感受野又受限于位置固定的小窗口当中,一些高度相关的 token 之间无法match。
CASSI 压缩退化的数学模型
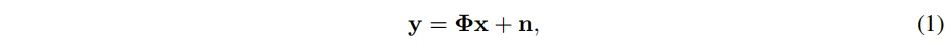
退化可感知的深度展开框架
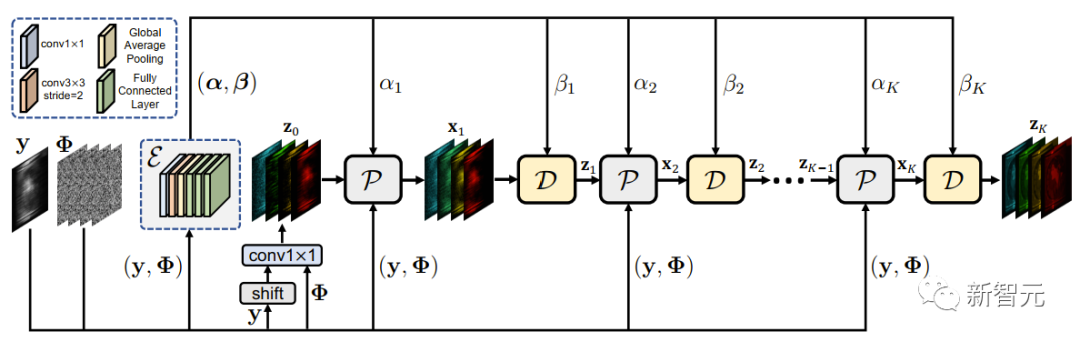
图2 退化可感知的深度展开式数学框架
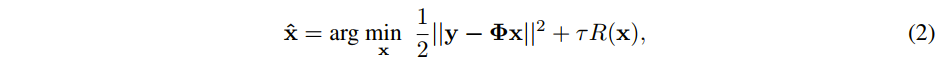
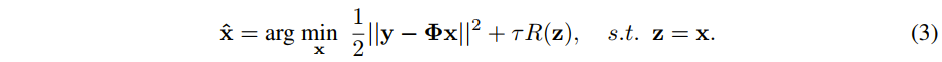
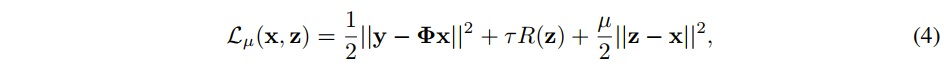
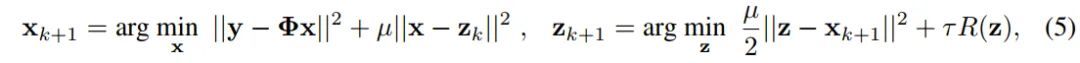
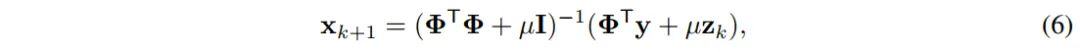
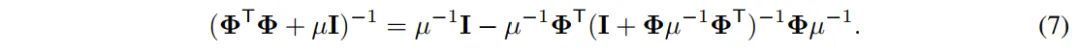
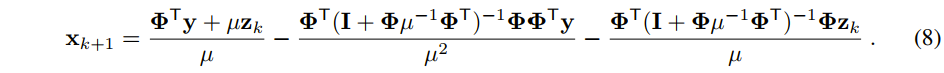
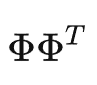 是一个对角矩阵,定义
是一个对角矩阵,定义
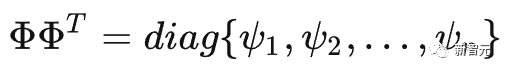 ,由此可得:
,由此可得:
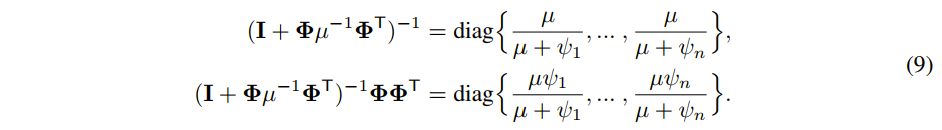
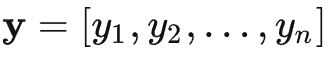 且
且
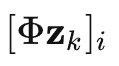 表示
表示
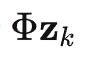 的第 i 个元素,将公式(9)代入公式(8),可得:
的第 i 个元素,将公式(9)代入公式(8),可得:
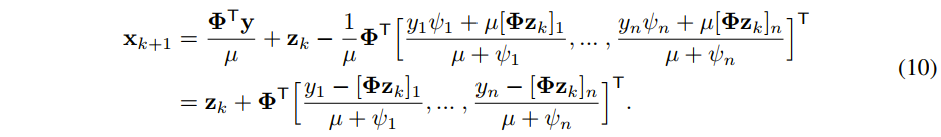
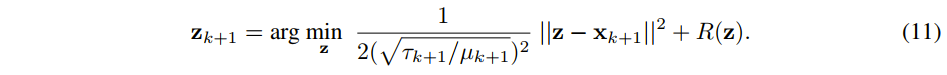
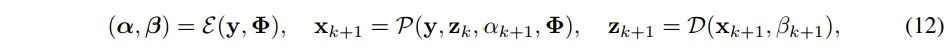
半交互式 Transformer
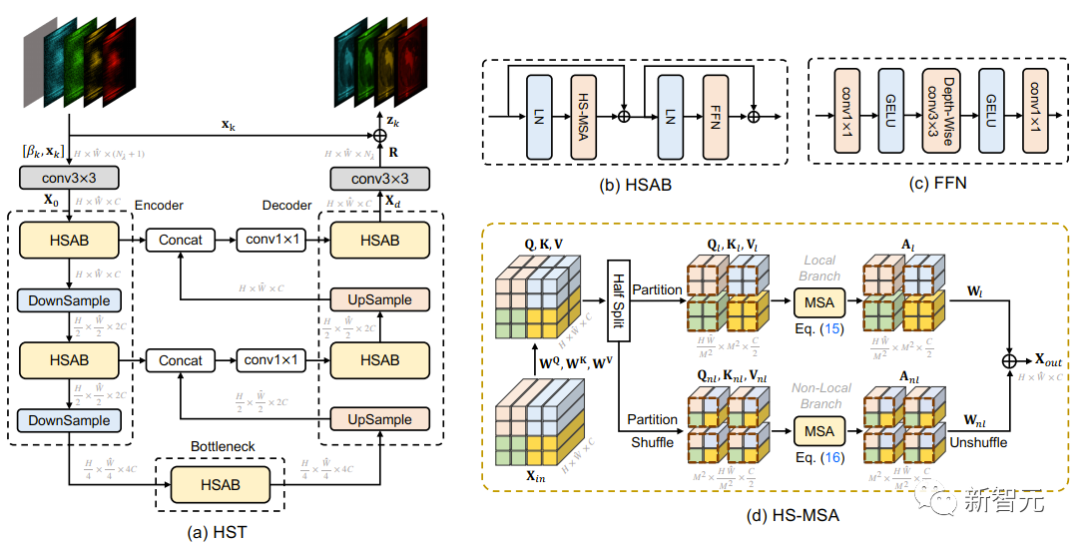
图3 半交互式 Transformer 的网络结构图
网络整体结构
Half-Shuffle Multi-head Self-Attention
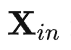 线性映射为:
线性映射为:
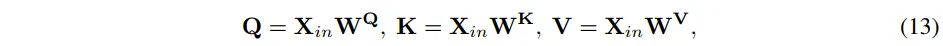
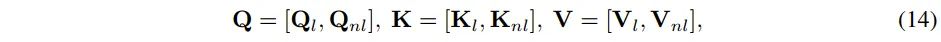
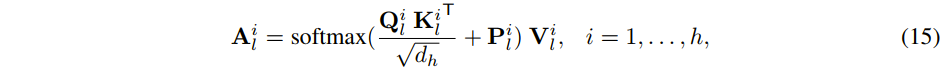
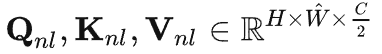 进行 网格划分,再reshape,从
进行 网格划分,再reshape,从
 ,然后再计算 self-attention 如下:
,然后再计算 self-attention 如下:
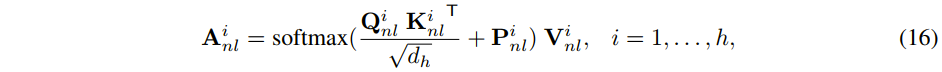
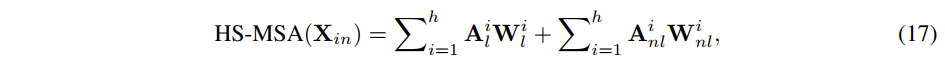
定量实验对比
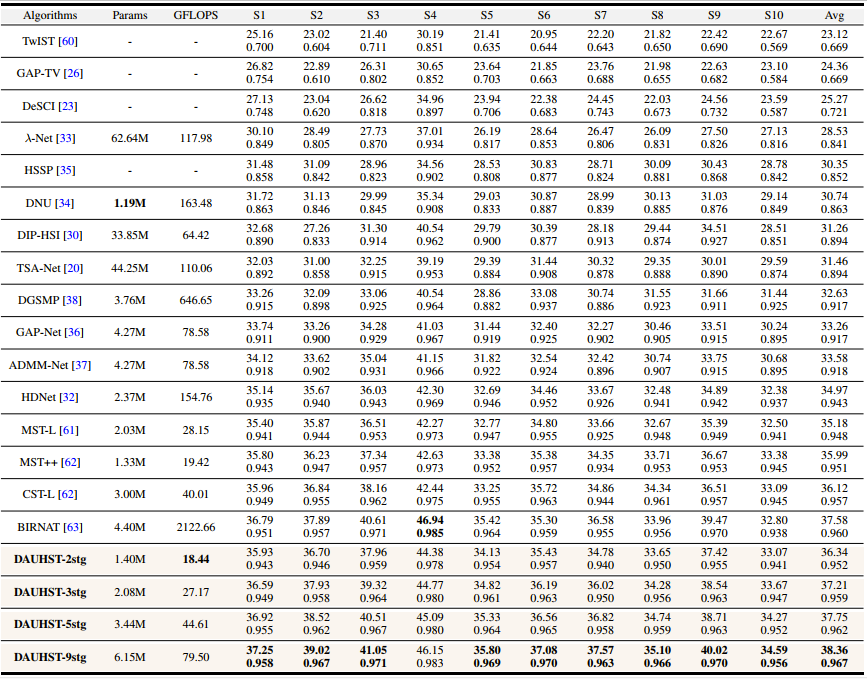
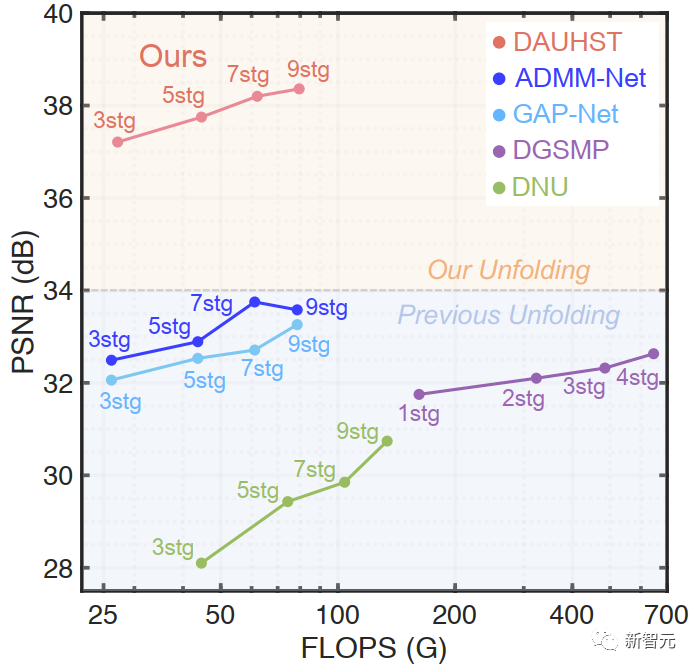
相较于先前的 Deep Unfolding 方法,我们绘制了 PSNR - FLOPS 坐标图比较 DAUHST 和其他 Deep Unfolding 方法的 性价比。如图4所示。我们的方法在消耗相同计算量的情况下比先前方法要高出 4 dB。
定性实验对比
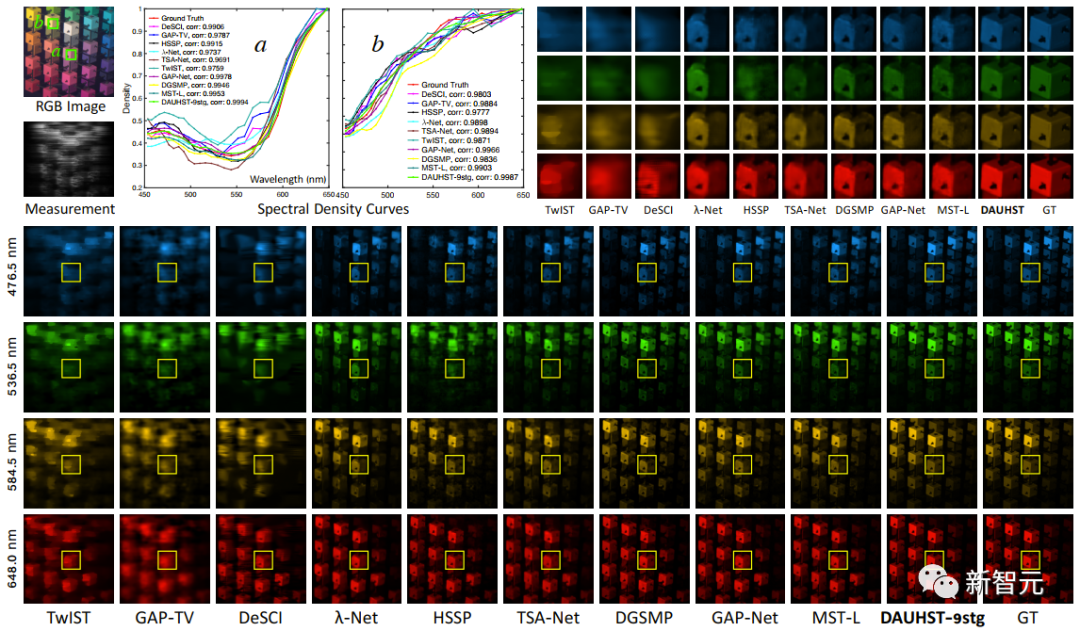
图5 仿真数据集上的视觉对比结果
在仿真数据集上的定性结果对比如图5所示。左上角是RGB图像和快照估计图(Measurement)。下方四行图像是不同方法重建的四个波长下的高光谱图像。右上角的图像是下方图像中黄色框框内的放大图。
从重建的高光谱图像来看,我们的方法能更好地恢复出细节内容和纹理结构,请注意对比小立方块区域。a 和 b 曲线对应着 RGB 图像的两个绿色框的区域的光谱强度曲线,可以看出,我们的 DAUHST 与 Ground Truth 的曲线最为接近。

本文是我们 SCI 系列代表作的第五个,也是 NeurIPS 上边首次有 SCI 重建的工作。
SCI 重建作为新兴的 low-level 方法这两年迅猛发展,希望能够看到有更多的人能够加入的这个 topic 的研究,毕竟新的领域有更多出成果的机会。
另附上我们先前在 CVPR 2022 和 ECCV 2022 上的两个工作 MST 和 CST 的知乎解读链接:
[CVPR 2022 & NTIRE 冠军] 首个高光谱图像重建Transformer
https://zhuanlan.zhihu.com/p/501101943
[ECCV 2022] CST: 首个嵌入光谱稀疏性的Transformer
https://zhuanlan.zhihu.com/p/544979161
参考资料:
https://zhuanlan.zhihu.com/p/576280023



