AI时代的物种大爆发,连一支笔也不例外

来源:量子位
本文为约3128字,建议阅读5分钟
本文介绍
了笔扫场景下的OCR算法。
AI时代,究竟会是怎样的时代?
有一种观点是,当AI重新定义一切,推动一系列新技术、新产品、新应用在地球上掀起一场新的“物种大爆发”,那么AI本身,反而会隐匿不见。
就像水,像电,像一切最终成为人们生活基础的科学技术那样。
以此定义,我们离这样的时代又有多远?

当AI与电力的结合,催生出正在颠覆汽车工业面貌的智能驾驶。
当AI创作的文本、图画,乃至程序,越来越频繁地引发人与机器之争,又悄悄普及成为人们手中的生产力利器。
当小到一支笔,都能被装进繁复的算法,却又并未更改人们习以为常的使用方式。
现在,这个时代的序幕,或许早已向你我揭开。
一支笔的AI之旅
90后的童年里,有一句广告词人人耳熟能详:哪里不会点哪里。
彼时,这样的“笔”并不能脱离配套的书本单独发挥作用:
其原理是用带有感光设备的仪器,去感应特定印刷品中的OID光学辨别编码。
但到了10后的童年时代,一句略带夸张的广告语,却已真正成为现实:
还不只是能搞定查词这种小事。
即使是大段文本,轻扫两下,这样的设备也能以毫秒为时间单位,给出逐句对照的翻译结果。

甚至脱离开纸质材料,面对电子屏幕,这支笔也照样能发挥作用。

事实上,当有道词典笔的产品代号来到最新的P5,用户们对一支笔“横扫”一切这事儿都有点习以为常了:
于是,这支笔进化出了“超大智慧视窗”,学会了“一目十行”。

是真的可以扫10行
配合全面屏设计,一屏可以同时显示4行英文和2行中文。

翻译论文、外语资料三下即可搞定一个摘要。如果遇上pdf版,还能免去删换行的烦恼。

复制pdf文档时删到人呆滞的换行
没什么学习成本,正常该怎么用笔就怎么用。
无论是用笔的过程中出现角度变化,还是扫描出现重复,都不影响最后的识别效果。
也就是说,站在最终用户的角度来说,伴随着AI技术潮起的节奏,拿一支笔当词典这事儿,变得越来越简单,也越来越自然了。

超大智慧视窗可以同时扫描翻译最多十行文字,与此前产品对比明显
但技术这件事儿一个有趣的地方就在于:
表象越简单轻松,背后值得说道的事情,反而越多。
站在AI时代的大幕之前,其中一切,对于作为观察者的我们而言,不外如是。
小硬件里的深科技
从特殊印刷的OID,到连电子屏幕也照样能扫,从扫译一个单词、单行到“一目十行”,一支笔里最主要的算法变化,便是OCR(光学字符识别)。
一般来说,笔扫场景下的OCR算法,无论是单词识别还是“一目十行”,都比拍照识别、截图识别等情况更为复杂。
因为笔尖摄像头看到的图像,往往是这样的:

以有道词典笔为例,尤其是当P5这样的产品推出,为做到“一目十行”,在笔尖配上基于90°广角镜头的“超大智慧视窗”后,麻烦事儿也更多了:
大视窗让可视范围更大,意味着光照等条件可能更不均匀,输入图像的清晰度反而会降低;
用户扫描的方式随着大视窗变得更自由,则输入文字图像会更容易扭曲;
用户可能会扫描进更多多余的内容,需要算法能判断文本结构,精准去重。
……
算法如何解决?
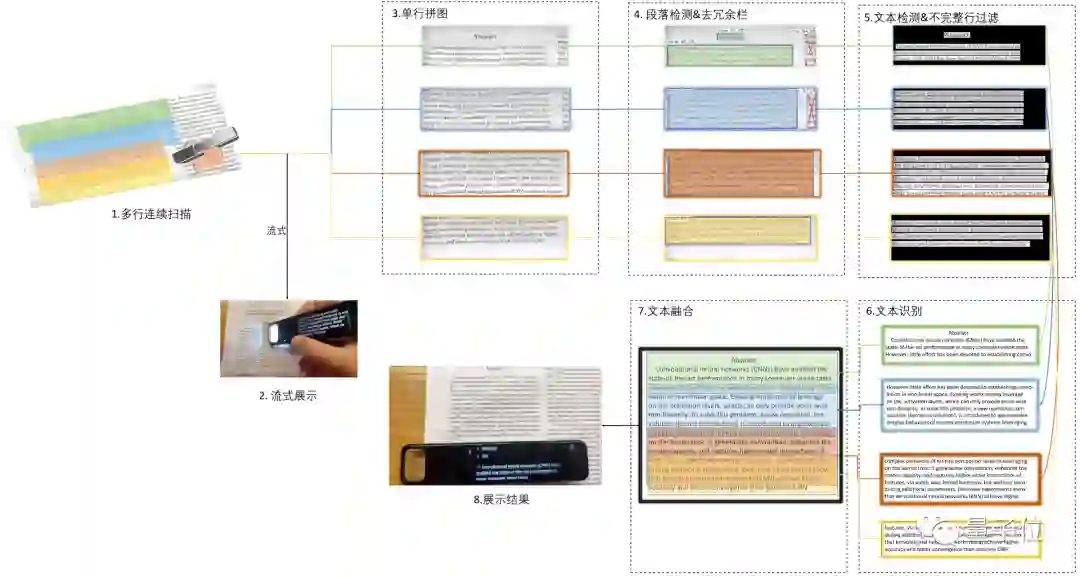
有道词典笔P5多行扫描处理流程
就从识别流程来看,当用户一次扫了多个“段落”之后,系统首先面临的是拼接问题。
也就是将扫描的n张照片拼成完整的一张。

这个过程中,用户用笔的角度可能会变化,会中途停顿……这些都会让笔头“看”到的图片出现扭曲、内容重复。
对此,有道的研发团队主要从OCR算法本身,以及硬件角度进行了优化:
算法上,采用单应性变换进行矫正。
具体来说,先通过模型计算相邻两帧图像的重合系数,然后采用多尺寸模板匹配策略,加入NEON并行计算,又快又准地得到两帧图像重叠区域(下图绿色部分)。
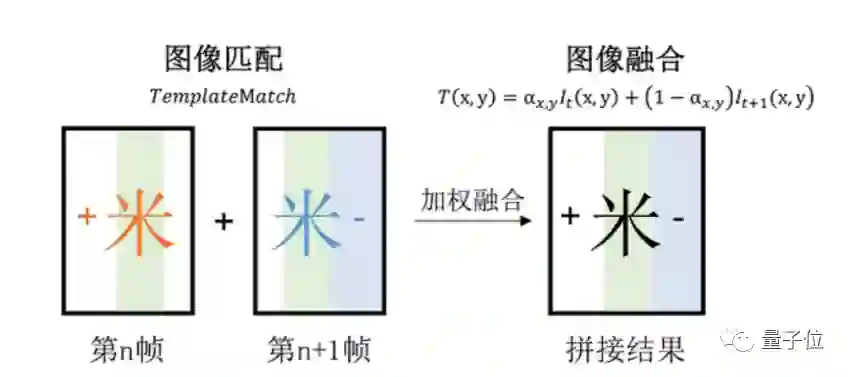
接着,通过有道自研的自适应图像加权融合算法,便能自然地将两帧图像融合了。
不过对于可能出现的上下抖动情况,融合时会出现不同程度的融合模糊。
这时,就需要针对存在上下偏移的重叠区域,进行融合区变形,之后再做加权融合,消除竖直方向上的投影偏差。

硬件上,则是进一步地让ISP对扫描摄像头采取了实时图片矫正,让它根据持笔的角度优化采图质量,保证多角度下的识别效果。
基于以上,这支词典笔便可以满足不同用户的扫描速度、角度和习惯,即使手抖,依然可以获得清晰的拼接图像。
但对于“一目十行”来说,拼接还只是第一个问题,第二个问题,是实现结构化OCR,也就是要对文章的段落、分隔栏等结构进行判断识别。
为了兼顾速度和准确性,有道主要基于先进的目标检测方法,采用自顶向下的策略,设计并研发了扫描场景的段落检测方法。
得益于解耦检测头和分类头的策略,以及先进的标签匹配方式,该算法具有很强的鲁棒性,支持教材、报纸等多样化场景。
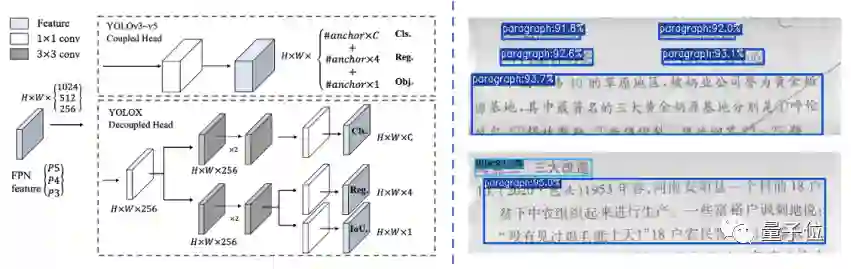
识别出结构,接下来就是文本检测,如将不完整的行进行过滤。

在这里,研发人员在AI芯片的加持下,重新设计出了一个基于分割的字符级文本检测方法,让检测更加精准。
由于字符级标注难以获取,他们还用上了半监督学习方法来训练检测模型。
以上步骤完成后,就可以开始文字识别了。
目前,有道的OCR系统可以支持横竖斜混合排版识别、手写识别、简繁公式识别、100+种语言文字的混合识别,同时也支持身份证、票据等垂直场景。
最后一步,便是文字融合,通过定位和拼接的方式将识别出来的文字进行语义信息以及结构信息上的融合。
重复扫描的内容就在这里被消除。
至此,一支词典笔才在软件方面炼就了“一目十行”的能力。
总的来看,最大的亮点便是通过文本去重、去冗余栏及冗余行等,做到了让用户扫描时不用刻意对齐,保证了良好的使用体验。
再来看硬件,该方面也存在诸多挑战,主要集中在笔尖设计上。
通常来说,经过多年发展,在词典笔这样的品类中,较为成熟的笔尖功能触发方案,是机械感应方案。
但由于实现“一目十行”需要大视窗的笔头,新的问题产生了:遮挡太多,影响扫描效果。
研发人员想到的是,用压感触发来替代机械触发。
问题是,要把压感方案做到一个小小笔头上,还要尽量减少对镜头的遮挡。这样的方案,在有道词典笔P5之前,业界属实没有先例。
为了优化横梁的遮挡以及跌落测试优化,团队一次次调整结构优化方案,甚至推到重来,确保传感器不受遮挡,能够准确识别到扫描的信息。
最后的解决方案,某度程度上来说也是一种无奈的妥协:
把传感器放到了笔头两侧而非横梁上,技术难度上升的同时,成本也增加了——原来只需要一个传感器,现在需要两个。

是的,感应器藏在这里,不在“笔尖”
这也是为什么,这样一个小硬件,从立项到正式完成,耗时整整16个月。
不过好在,经过这么多努力和折腾,“一目十行”的功能终于实现了。
“一目十行”之外,现在的有道词典笔还搭载了有道首创的词典笔OS操作系统,用户可以根据需求下载不同的应用,让词典笔变换成“随身听”、“录音笔”等更多形态,从而实现词典笔的“个性化”。
AI时代的“物种大爆发”
没想到吧,看似简简单单一支笔、一个功能,封装进的AI和硬件黑科技,值得讨论之处却着实不少。
而可以预见的是,在真正的AI时代,黑科技不仅仅是实验室中酷炫却不可及的AlphaGo、GPT-3,而更多会在人们所能感知或不能感知的角落,生根发芽。
这一方面,是软硬件技术成熟落地的标志。
另一方面,其实也是因为在各个细分领域,总有人试图把事情做到极致。
正如有道工程师们所经历的那样:初版Demo早在去年6月就已经完成,但就因为尺寸太大,影响使用效果,研发团队虽然很“崩溃”,但仍一致决定,把方案推倒重来,重新从压感方案做起。
这样对产品体验精益求精的追求,反馈到消费者的层面上,就是产品带来的更高效率、更多实用性。
如此看来,站在一个普通人的角度,AI时代有关新产品、新应用的“物种大爆发”,着实值得期待。
你觉得呢?





