ICLR今日放榜!创纪录2594篇投稿,687篇被接受论文华人学者参与近半

新智元报道
新智元报道
来源:medium
编辑:张佳、向学
【新智元导读】今天,ICLR 2020放榜了!共收到2594篇论文提交,创历史新高,其中,有687篇被接受,接受率为26.5%。粗略统计,大概有320篇被接受的论文中有华人学者参与,占比47%。放榜后,不少华人学者分享了自己组的战绩。戳右边链接上 新智元小程序 了解更多!
终于等到你!今天,ICLR 2020放榜了!

ICLR 2020官宣
作为深度学习领域的顶级会议,ICLR 素有深度学习顶会 “无冕之王” 之称。ICLR 2020共收到2594篇论文提交,其中,有687篇被接受,接受率为26.5%。共计48篇Oral、108篇Spotlight和531篇posters。
我们手动统计了一下,大概有320篇被接受的论文中有华人学者参与,占比47%。(人工统计如果有出入还望谅解)
放榜后,不少学者晒出了自己组的成绩:

UC Berkeley EECS教授马毅表示,自己一位学生的论文被接受了。“这篇文章不是追求什么SOTA,而是重在帮助大家理解。把一个看似困难的问题做得简单明了,而且与以前的经典工作在思想算法上完全统一起来。如果大家关心PCA、ICA、以及DL(Dictionary Learning)的统一关系,这应该是迄今最简单完美的解释。”
查看地址:https://openreview.net/forum?id=SJeY-1BKDS
CMU计算机学院副教授马坚表示,自己组的Hyper-SAGNN论文现在已被ICLR 2020接受。这是一种用于超图的通用图神经网络。在这项工作中,他们还展示了其对单细胞Hi-C数据的实用性。
查看地址:https://openreview.net/forum?id=ryeHuJBtPH

UCSB计算机科学系助理教授王威廉参与的多篇论文被接受。包括陈文虎同学的“TabFact: A Large-scale Dataset for Table-based Fact Verification”,在这篇文章中,我们与腾讯人工智能实验室陈建树博士合作,提出了一个基于半结构化表格的自然语言推断任务与新的数据集。以及熊文瀚同学的“Pretrained Encyclopedia: Weakly Supervised Knowledge-Pretrained Language Model ”,在这篇文章中,我们与脸书人工智能实验室Ves Stoyanov等合作,提出了一个新的基于实体的预训练模型,在问答与实体类型预测任务上结果非常不错。
查看地址:
https://openreview.net/forum?id=rkeJRhNYDH
https://openreview.net/forum?id=BJlzm64tDH
接下来和大家分享ICLR 2020的总体结果。(以下“我们”代指ICLR 2020主委会)
687篇论文被接受,接受率为26.5%
我们继续向ICLR递交最出色的工作,但遗憾的是我们无法接受每一篇提交的论文。我们祝贺那些被接受的论文的作者,也希望无法被接受的论文的作者在正在进行的研究中取得成功。
ICLR 2020将接受687篇论文:
-
在2594篇提交的论文中有687篇被接受,接受率为26.5%(687/2594); -
与往常一样,所有接受的论文都将作为posters展示; -
接受的论文中有23%将进行口头报告:108篇论文作为4分钟短报(Spotlights)展示;48篇论文有更长的10分钟发言时间。
审查过程与上一年基本没有变化,只是做了两个调整:我们不允许在讨论期间中途公开评论,以使作者和审查人员对讨论的要点有一个清晰的范围;我们有一个明确的一周时间进行替代和紧急审查。我们的大部分变化是在会议方案的结构上。
评分系统:为了使决策更加清晰,今年的评级系统进行了简化,去掉了中性评级的选项:我们只有拒绝、弱拒绝、弱接受和接受的选项。
需要为这些评级分配数值,以产生一个平均分数,尽管建议本身比数字更重要。
分数是不对称的,分别是1分、3分、6分和8分,这是有原因的。对于接受论文,我们担心审稿人不愿意给10分:您可能希望论文被接受,但并不意味着它应该得到10分。我们不想劝阻审稿人去强烈声明“接受”。此外,3分到6分之间的较大差距使得弱拒绝和弱接受之间有更大区分,以提供对建议的更多承诺并避免中立。尽管有些不常规,但得出的平均值对于指导决策还是有意义的。
119位AC和2200名审稿人支持,ICLR 2020的挑战与改进
我们看到提交给会议的论文数量延续了前几年的趋势,继续显著增长,如下图所示。这使得建立经验丰富的大型审稿人库,变得越来越困难。今年我们很幸运得到了119位AC和2200名审稿人的支持。这个方案委员会的规模没有我们所希望的那么大,却承担了更多的评审负担。我们的AC非常棒! 他们每个人都有20篇论文,在决策方面做得非常好。正是由于他们的勤奋,才使得被接受的论文质量很高。
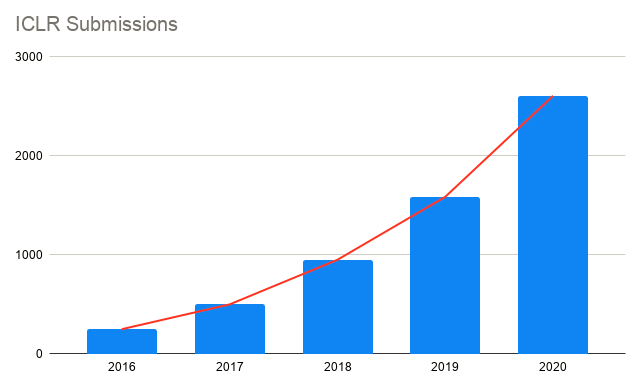
向ICLR提交论文的数量随时间变化图
公开评议的归档性质:提交给ICLR的一部分作者要认识到,它也是一个归档系统,一旦论文被提交了,它最终将变为非匿名(无论它被撤回、拒绝或做出最终决定),并且不能被删除。一些作者似乎对这一原则有误解或理解不够,我们收到了许多要求删除提交论文的请求,或在一些极端情况下,提交者试图通过用空白PDF替换信息来规避这一政策。选择提交给ICLR就是要接受这一归档政策,未来也需要更加清晰的沟通。
双重提交和撤回:我们拒绝了少数论文(不到20篇),因为它们违反了“双重提交政策”。我们也撤回了大量论文,比如与其他会议截止日期临近和重叠,或与其他会议如ACL的“匿名政策”不相符。这是适得其反的,因为这消耗了许多审稿人的精力,他们本可以将工作用在其他方面。我们未来计划的一部分是考虑如何阻止这种结果。
ICLR 2020审稿人资质和评审机制引争议
前段时间,ICLR 2020审稿人资质和评审机制引发了不小的争议。南大周志华教授曝出:ICLR 2020竟然有47%的审稿人从来没有在本领域发表过论文。
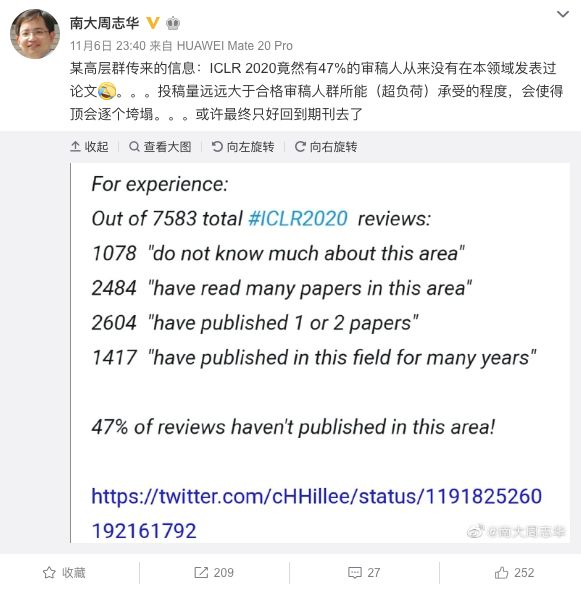
在7583位ICLR 2020审稿人中,1078人“不了解该领域”;2484人“读过该领域的很多论文”;2604人“发表过1-2篇论文”;1417人“在该领域发表论文很多年”。这样计算,47%的审稿人从来没有在该领域发表过论文!
周志华表示,open review仅当参与者都是相当level的专家才有效,否则更容易被误导。学术判断不能“讲平等”,一般从业者与高水平专家的见识和判断力不可同日而语,顶会能“顶”正是因为有高水平专家把关,但现在已不可能了。
此外,一篇ICLR 2020的论文在拿到完美的满分评价(8-8-8)后,额外的两位审稿人连续给了2个1分评价,也引发了激烈讨论。
可见ICLR 2020争议不小,不过还是要恭喜所有被接受的论文,我们也期待看到中国学者的研究获得最佳论文。
参考链接:
https://medium.com/@iclr_conf/ourhatata-the-reviewing-process-and-research-shaping-iclr-in-2020-ea9e53eb4c46
拓展阅读:
ICLR2020 双盲审稿资质雪崩:47%审稿人在领域内没发过论文,8分论文你也能审!
ICLR 2020满分论文慘遭两个1分拒绝!AI顶会评审机制再受质疑
寒冬里,这个最酷AI创新平台招人啦!新智元邀你2020勇闯AI之巅
在新智元你可以获得:
-
与国内外一线大咖、行业翘楚面对面交流的机会 -
掌握深耕人工智能领域,成为行业专家 -
远高于同行业的底薪 -
五险一金+月度奖金+项目奖励+年底双薪 -
舒适的办公环境(北京融科资讯中心B座) -
一日三餐、水果零食





